标签:alt 之间 append 对象 mic src 样本 聚类 有一个
使同一类对象的相似度尽可能地大;不同类对象之间的相似度尽可能地小。
二、层次聚类
层次聚类算法实际上分为两类:自上而下或自下而上。自下而上的算法在一开始就将每个数据点视为一个单一的聚类,然后依次合并(或聚集)类,直到所有类合并成一个包含所有数据点的单一聚类。因此,自下而上的层次聚类称为合成聚类或HAC。聚类的层次结构用一棵树(或树状图)表示。树的根是收集所有样本的唯一聚类,而叶子是只有一个样本的聚类。在继续学习算法步骤之前,先查看下面的图表
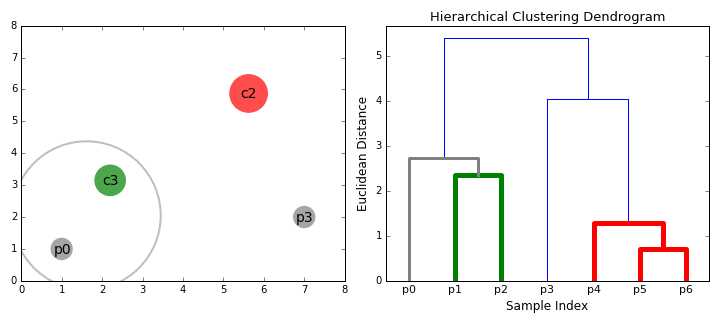
1.我们首先将每个数据点作为一个单独的聚类进行处理。如果我们的数据集有X个数据点,那么我们就有了X个聚类。然后我们选择一个度量两个聚类之间距离的距离度量。作为一个示例,我们将使用平均连接(average linkage)聚类,它定义了两个聚类之间的距离,即第一个聚类中的数据点和第二个聚类中的数据点之间的平均距离。
2.在每次迭代中,我们将两个聚类合并为一个。将两个聚类合并为具有最小平均连接的组。比如说根据我们选择的距离度量,这两个聚类之间的距离最小,因此是最相似的,应该组合在一起。
3.重复步骤2直到我们到达树的根。我们只有一个包含所有数据点的聚类。通过这种方式,我们可以选择最终需要多少个聚类,只需选择何时停止合并聚类,也就是我们停止建造这棵树的时候!
层次聚类算法不要求我们指定聚类的数量,我们甚至可以选择哪个聚类看起来最好。此外,该算法对距离度量的选择不敏感;它们的工作方式都很好,而对于其他聚类算法,距离度量的选择是至关重要的。层次聚类方法的一个特别好的用例是,当底层数据具有层次结构时,你可以恢复层次结构;而其他的聚类算法无法做到这一点。层次聚类的优点是以低效率为代价的,因为它具有O(n³)的时间复杂度,与K-Means和高斯混合模型的线性复杂度不同。
层次聚类方法对给定的数据集进行层次的分解,直到某种条件满足或者达到最大迭代次数。具体又可分为:
凝聚的层次聚类(AGNES算法):一种自底向上的策略,首先将每个对象作为一个簇,然后合并这些原子簇为越来越大的簇(一般是计算所有簇的中心之间的距离,选取距离最小的两个簇合并),直到某个终结条件被满足或者达到最大迭代次数。
分裂的层次聚类(DIANA算法):采用自顶向下的策略,它首先将所有对象置于一个簇中,然后逐渐细分为越来越小的簇(一般是每次迭代分裂一个簇为两个),直到达到了某个终结条件或者达到最大迭代次数。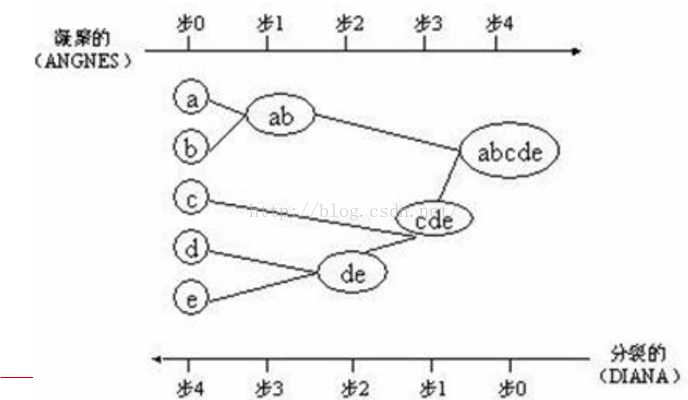
import sys,os
import numpy as np
class Hierarchical:
def __init__(self,center,left=None,right=None,flag=None,distance=0.0):
self.center = center
self.left = left
self.right = right
self.flag = flag
self.distance = distance
def traverse(node):
if node.left==None and node.right==None:
return [node.center]
else:
return traverse(node.left)+traverse(node.right)
def distance(v1,v2):
if len(v1)!=len(v2):
print("出现错误了")
distance = 0
for i in range(len(v1)):
distance+=(v1[i]-v2[i])**2
distance = np.sqrt(distance)
return distance
def hcluster(data,n):
if len(data)<=0:
print(‘invalid data‘)
clusters = [Hierarchical(data[i],flag=i) for i in range(len(data))]
#print(clusters)
distances = {}
min_id1 = None
min_id2 = None
currentCluster = -1
while len(clusters)>n:
minDist = 100000000000000
for i in range(len(clusters)-1):
for j in range(i+1,len(clusters)):
#print(distances.get((clusters[i], clusters[j])))
if distances.get((clusters[i],clusters[j]))==None:
distances[(clusters[i].flag,clusters[j].flag)]=distance(clusters[i].center,clusters[j].center)
if distances[(clusters[i].flag,clusters[j].flag)]<= minDist:
min_id1 = i
min_id2 = j
minDist = distances[(clusters[i].flag,clusters[j].flag)]
if min_id1!=None and min_id2!=None and minDist!=1000000000:
newCenter = [(clusters[min_id1].center[i]+clusters[min_id2].center[i])/2 for i in range(len(clusters[min_id2].center))]
newFlag = currentCluster
currentCluster -= 1
newCluster = Hierarchical(newCenter,clusters[min_id1],clusters[min_id2],newFlag,minDist)
del clusters[min_id2]
del clusters[min_id1]
clusters.append(newCluster)
finalCluster = [traverse(clusters[i]) for i in range(len(clusters))]
return finalCluster
if __name__ == ‘__main__‘:
data = [[123,321,434,4325,345345],[23124,141241,434234,9837489,34743],\
[128937,127,12381,424,8945],[322,4348,5040,8189,2348],\
[51249,42190,2713,2319,4328],[13957,1871829,8712847,34589,30945],
[1234,45094,23409,13495,348052],[49853,3847,4728,4059,5389]]
#print(len(data))
finalCluster = hcluster(data,3)
print(finalCluster)
#print(len(finalCluster[0]))
标签:alt 之间 append 对象 mic src 样本 聚类 有一个
原文地址:https://www.cnblogs.com/limingqi/p/11996796.html