标签:维数 形式 首字母 绘图 接口 帮助 studio rev 运行
R和RStudio 是与计算机进行对话的两个工具
RStudio 是话筒
R是沟通所用的语言
R的由来:基于S语言,由新西兰奥克兰大学的Robert Gentleman和Ross Ihaka开发,因两位开发者名字首字母都是R,所以该语言命名为R。
怎样理解R
一种计算机语言
一种用于统计分析、绘图的操作环境
用户接口
R 语言特点
R 是一款开源、免费的软件,可以跨平台运行
R 提供了非常丰富的统计分析技术
有很多非常实用并包含最新技术的R包,而且更新速度非常快
R的绘图功能十分强大
软件界面:
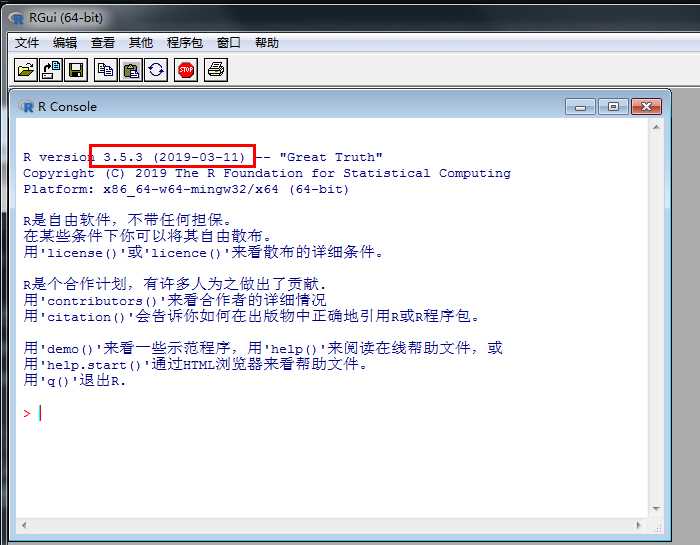
配置文件,选择SDI单窗口
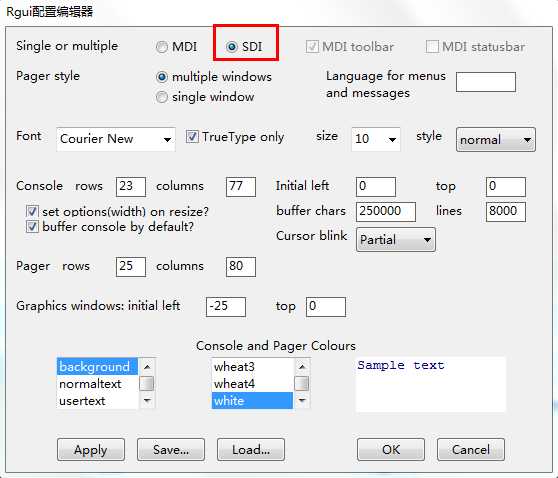
选择save进行直接保存修改,不需要更改路径
效果图:
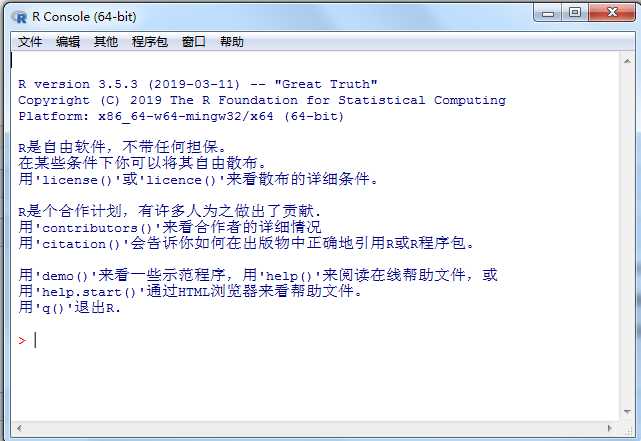
R环境下的提示符:

2、R包的安装

下载包:
查看所有包的命名:
(.packages(all=T))

加载包命令:

没有任何提示表示结果正常
向量的长度=向量的个数
字符串向量,双引号 “ ”
c函数:拼接功能
同时下载两个包
install.packages(c("reshape2","dplyr"))
R语言区分大小写
对象sz
<-赋值符号
1:6数值
sz<-1:6

连续赋值:

ls()函数调取所有对象
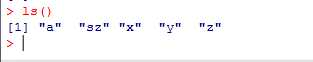
get()函数得到变量的数值
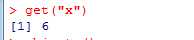
删除对象:
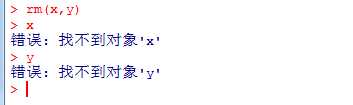
删除所有对象
rm(list=ls())
统计函数
sum()

sz+1:2

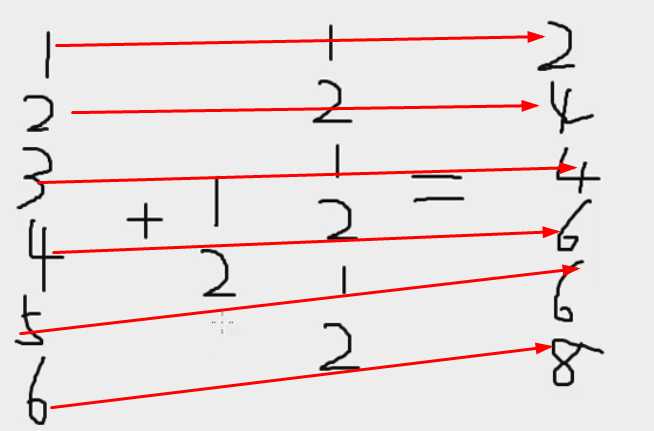
sz+1:4

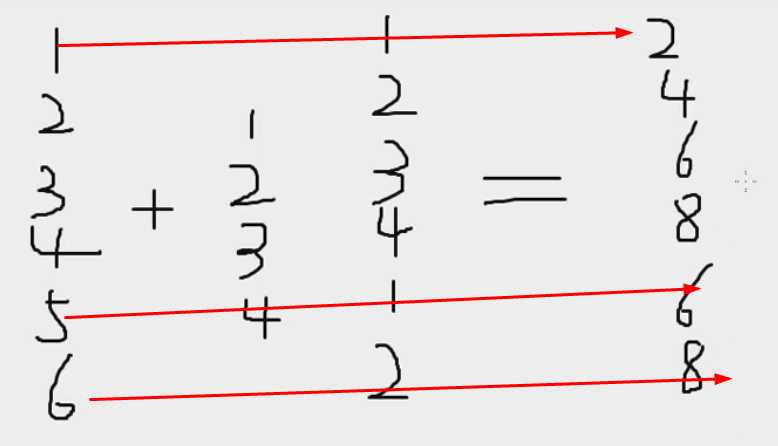
R使用元素执行方式运算的机制:匹配向量,独立操作每对元素 如果两个向量长度不等,R会在较短的向量上重复 以上这种行为在R中被称为向量循环,帮助R执行元素方式运算 矩阵乘法:当需要使用矩阵乘法时,需要做出专门的请求 计算向量的内积:sz %*% sz 计算向量的外积:sz %o% sz 转置:t() 计算矩阵的行列式:det()
sz*sz 平方运算

sz%*%sz 一行一列
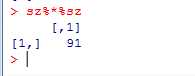
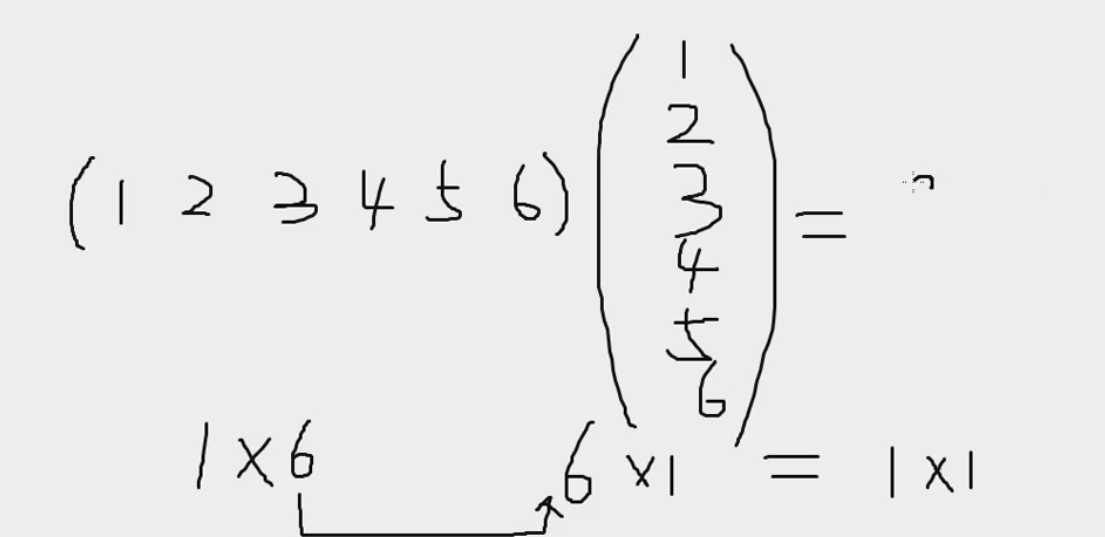
sz%o%sz

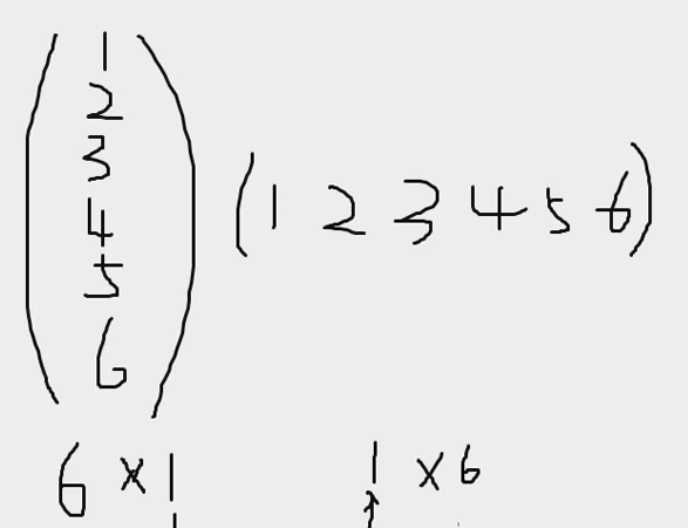
c(2,5,6,8)%o%c(3,7)



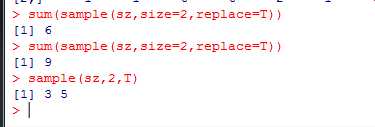
用sample()函数,抽取1:6的随机数,抽取两次
sample函数可以完成随机抽样处理,其基本形式为:
sample(x, size, replace = FALSE)
replace=False 表示不可放回抽样

用replicate()函数执行100次

replace=TRUE/replace=T可放回抽样

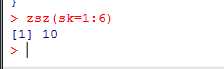
基于名称的传参和基于位置的传参
基于位置的传参必须严格按照位置顺序,否则出错
自定义函数------------调用函数
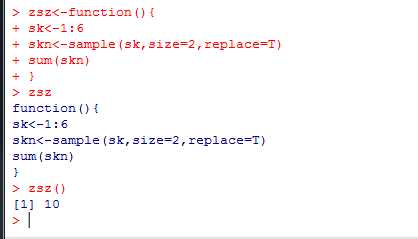
练习:重复执行10次郑色子,得到10个点数和
首先自定义函数,再调用函数

直接调用前面定义的函数

修改函数fix(函数名)
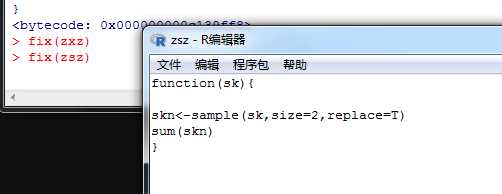

传参处理:
生成等差数列函数seq
seq(...) ## Default S3 method: seq(from = 1, to = 1, by = ((to - from)/(length.out - 1)), length.out = NULL, along.with = NULL, ...) seq.int(from, to, by, length.out, along.with, ...) seq_along(along.with) seq_len(length.out)

输出9个

伴随向量:

生成步长为1的等差数列
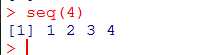
乘方运算
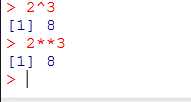
绘制一个散点图:两个变量的关系

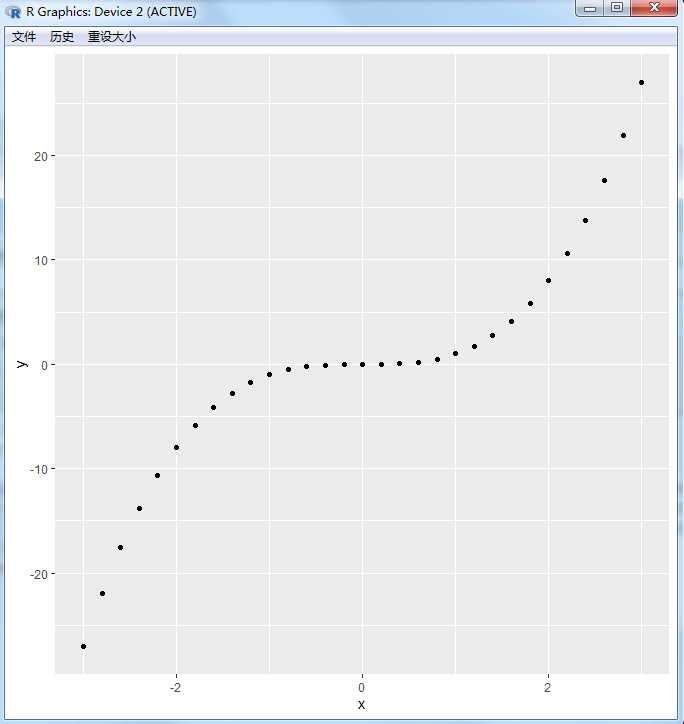
直方图
直方图的横纵坐标都是连续的,强调的是数值连续的变化规律,可以表示两个变量
> x<-c(1,2,3,3,3) > x [1] 1 2 3 3 3 > qplot(x)
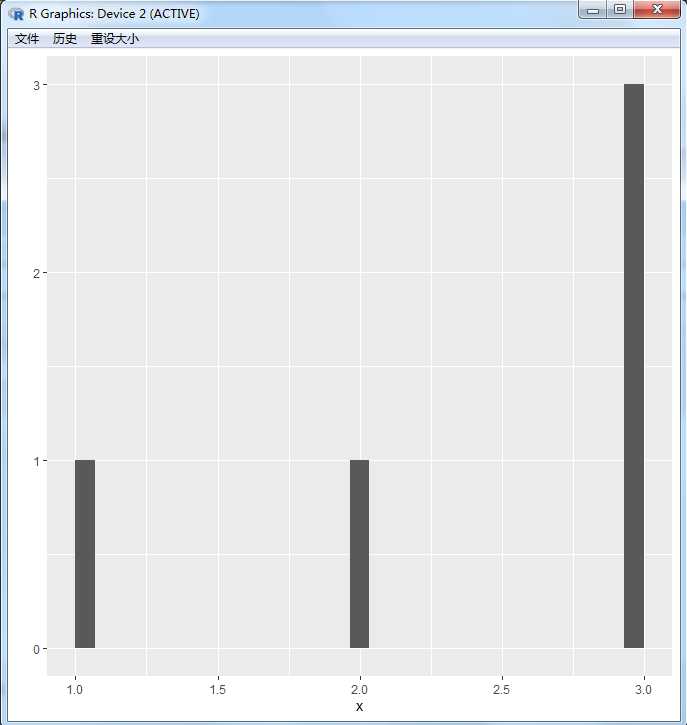
qplot(x,binwidth=1)
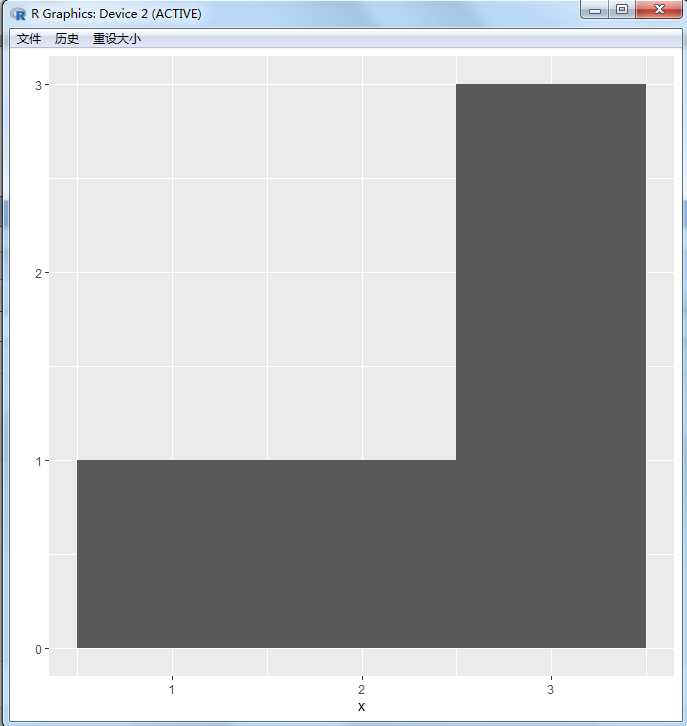
当次数够多满足正态分布
zn<-replicate(10000,zsz(sk=1:6))
> qplot(zn,binwidth=1)
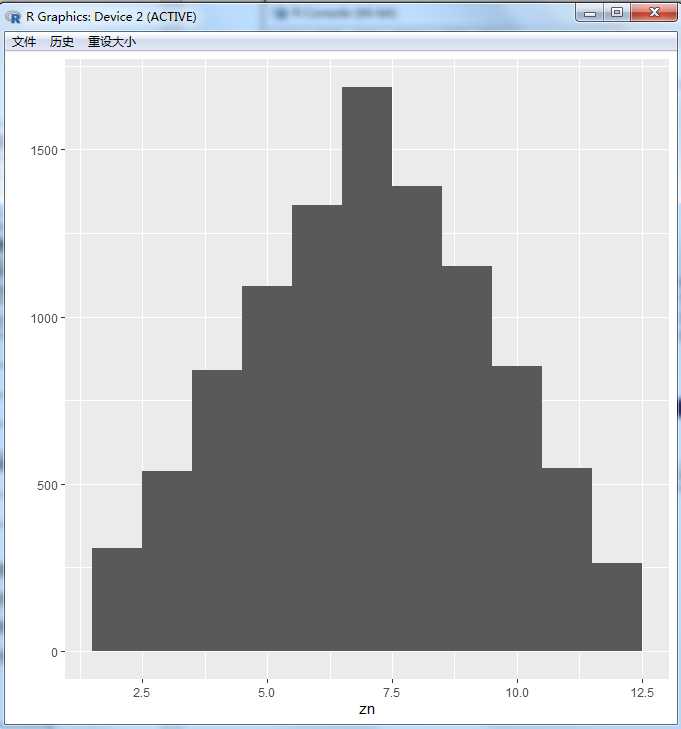
# 入样概率 prob控制概率
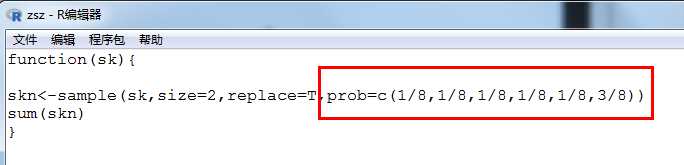
> zsz function(sk){ skn<-sample(sk,size=2,replace=T,prob=c(1/8,1/8,1/8,1/8,1/8,3/8)) sum(skn) } > zn<-replicate(10000,zsz(sk=1:6)) > qplot(zn,binwidth=1)
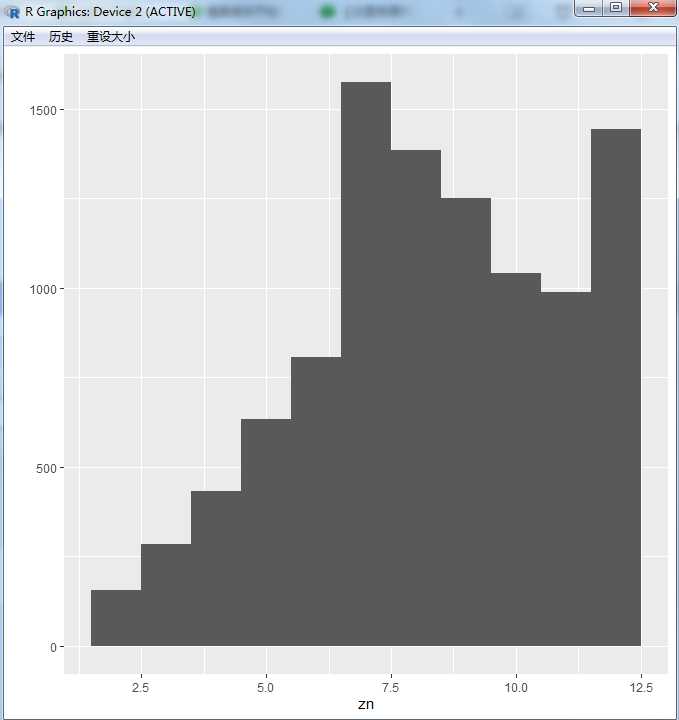
#添加入样概率,6点概率是其他点数概率的3倍 function(sk=1:6){ skn<-sample(sk,size=2,replace=T,prob=c(1,1,1,1,1,3)) sum(skn) }
向量的循环:
> rep(1:3,times=3) [1] 1 2 3 1 2 3 1 2 3 > rep(1:3,each=3) [1] 1 1 1 2 2 2 3 3 3 > rep(1:3,times=c(1,3,2)) [1] 1 2 2 2 3 3 >
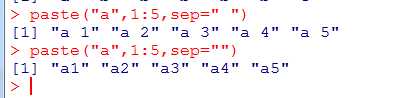
paste()
其中...表示一个或多个R可以被转化为字符型的对象;参数sep表示分隔符,默认为空格;
要求:自动洗牌、发牌
任务一:创建一副牌。学会如何使用R的数据类型和数据结构。
任务二:编写发牌和洗牌的函数。学习从一个数据集中抽取想要的数值。
任务三:改变点数系统。学习在数据的内部改变数据的取值
任务四:管理扑克牌的状态。学习R的环境系统和作用域规则。
原子型向量
数据结构:数据结构是存储、组织数据的方式,是数据内部的构成方法。
原子型向量:R里面最简单的数据类型,是构成其他对象类型的基本元素。
原子型向量的特点:每个原子型向量都将一种类型的数据存储在一个一维向量中。
原子型向量的分类:
双整型:存储普通的数值型数据;
> x1<-c(1,2,3,4,5,6)
> x1
[1] 1 2 3 4 5 6
> is.vector(x1)
[1] TRUE
> length(x1)
[1] 6
> typeof(x1)
[1] "double"
整型:存储整型的数据;
> int<-c(-1L,2L,4L)
> int
[1] -1 2 4
字符型:存储文本型数据;
逻辑型:用来存储TRUE和FALSE这两个布尔数据。
> logic<-c(TRUE,FALSE)
> logic
[1] TRUE FALSE
> typeof(logic)
[1] "logical"
复数型和原始类型:分别来存储复数和数据的原始字节。
is.vector():查看某个对象是否为向量。
typeof():查看某个对象的数据类型

#练习:生成一个原子型向量,来存储同花顺的牌面
同一种花色的顺子,比如黑桃的 A 、 K 、 Q 、 J 、 10
R-属性
属性:附加给原子型向量的额外信息。
attributes():查看一个对象包含哪些属性信息。
原子向量最常见的三种属性:名称、维度和类。每种属性都有自己的辅助函数。
练习1:给骰子的每个点数命名,并查看。
命名向量:
> kl<-c(a=1,b=2)
> kl
a b
1 2
关于维度:dim()函数可以将一个原子型向量转换为一个n维数组。
> dim(sz)<-c(2,3) > sz [,1] [,2] [,3] [1,] 1 3 5 [2,] 2 4 6 >
练习2:将一个向量转换为矩阵,并查看数据排列方式。
dim(sz)<-c(2,3,3)2行3列,切片3
练习3:用matrix()函数创建矩阵。
3行2列
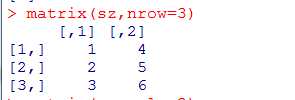
2行3列

练习4:用array()函数创建数组。
2行3列,4个切片

typeof():查看某个对象的数据类型
类:新的结构,新的格式。
class():查看一个对象的类。
练习1:赋予向量以维度属性,观察其class属性的变化。
用属性系统表示更多的数据类型:日期时间与因子。
日期与时间:R用一个特殊的类来表示日期和时间数据。
POSIXct:一个被广泛用于表示日期与时间的框架。
R处理规则:R函数在显示该对象之前,会根据POSIXct标准将该时间转换为用户可以理解的字符串。
练习2:用Sys.time()函数查看当前系统时间,并查看该对象的类和类型。
> Sys.time() [1] "2019-12-05 21:37:24 CST" > now<-Sys.time() > now [1] "2019-12-05 21:37:57 CST"
练习3:用unclass()函数移除对象的class属性。
> now [1] "2019-12-05 21:37:57 CST" > class(now) [1] "POSIXct" "POSIXt" > typeof(now) [1] "double" > unclass(now) [1] 1575553078
> #练习:1970年1月1日零点之后的100万秒是哪一天? > mil<-1000000 > class(mil)<-c("POSIXct","POSIXt") > mil [1] "1970-01-12 21:46:40 CST"
因子:存储分类信息。
R中因子生成机制:R会将向量中的值重新编码为一串整数值,再将编码的结果存储在一个整型向量中,
然后对其添加一个levels属性和一个class属性。其中levels属性包含显示因子值的一组标签。
练习1:用factor()函数创建一个因子。
练习2:用as.character()函数将一个因子强制转换为字符串。
问题:当在原子型向量中存储多种类型的数据会发生什么问题呢?
integer整型向量
> xb<-factor(c("female","male","male","female")) > xb [1] female male male female Levels: female male > class(xb) [1] "factor" > typeof(xb) [1] "integer" > as.numeric(xb) [1] 1 2 2 1
R强制转换所遵循的规则:
如果一个原子型向量包含字符串,R会将该向量中的所有元素都转换成字符型。
如果一个原子型向量只包含逻辑型和数值型元素,R会将逻辑型全部转换成数值型。
原因:单一数据类型的好处:数据操作更加直接和高效;而且就变量而言,变量中每个值度量的都是相同的属性,
因此没有必要使用不同的数据类型。
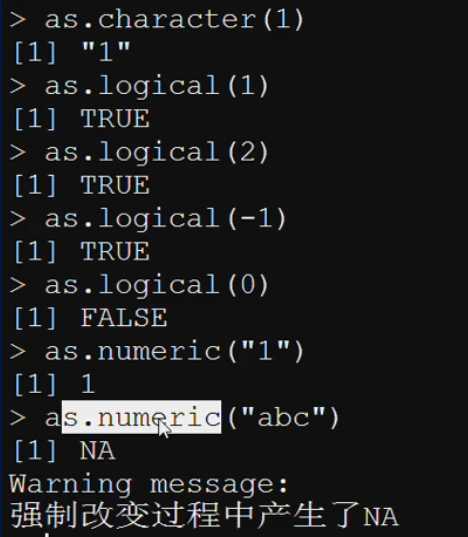
NA表示缺失值
> mn<-c("男","男","女") > mn [1] "男" "男" "女" > sum(mn=="男") [1] 2 > sum(mn=="女") [1] 1 > sum(mn=="男")/sum(mn) Error in sum(mn) : ‘type‘(character)参数不对 > sum(mn=="男")/sum(mn!="") [1] 0.6666667 > sum(mn=="男")/length(mn) [1] 0.6666667 > sum(mn=="男")/sum(c(mn=="男",mn=="女")) [1] 0.6666667 > mean(mn=="男") [1] 0.6666667
列表:将数据组织在一个一维集合中。与原子型向量的区别在于,列表并不是将某些具体的值组织起来,而是组织R对象。
练习:用list()函数创建一个列表
[[]]:表示来自列表的哪一个元素。
双索引系统:因为列表的元素可以是任意一种R对象。
列表的特点:R中全能型的存储工具。
下面最外层的list有三个元素

命名:

二维表
> data.frame(姓名=c("张三","李四"),成绩=c(100,90)) 姓名 成绩 1 张三 100 2 李四 90
数据框:列表的二维版本。将向量组织在一个二维表格中,每一个向量作为这个表格一列。
需要注意的问题:
不同的列可以包含不同的数据类型;
每一列必须具有相同的长度;
每个向量都有自己的名称;
stringsAsFactors参数应设置为FALSE。
练习:用data.frame()函数创建一副牌。
> data.frame(姓名=c("张三","李四"),成绩=c(100,90))->df > df 姓名 成绩 1 张三 100 2 李四 90 > typeof(df) [1] "list"
stringsAsFactors=F
> data.frame(姓名=c("张三","李四"),成绩=c(100,90),stringsAsFactors=F)->df > df 姓名 成绩 1 张三 100 2 李四 90 > str(df) ‘data.frame‘: 2 obs. of 2 variables: $ 姓名: chr "张三" "李四" $ 成绩: num 100 90
#项目二-构建一副扑克牌
pkp<-data.frame(pm=rep(c("A",2:10,"J","Q","K"),times=4),
hs=rep(c("红桃","黑桃","梅花","方块"),each=13),
ds=rep(1:13,times=4),
stringsAsFactors = F)
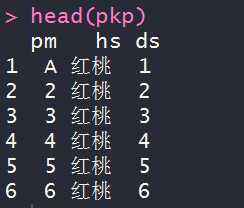
str(pkp) #查看pkp的前六条数据 head(pkp)
#查看pkp的前八条数据 head(pkp,n=8) #查看pkp的后六条数据 tail(pkp)
#查看当前的工作目录 getwd() #设置工作目录 setwd("C:\\Users\\Desktop\\DT") # 写入外部文件 write.csv(pkp,file = "puke.csv",row.names = F)
# 小结 # 第一个角度:从数据类型的角度 #数据类型相同的,向量、矩阵、数组 #数据类型不同的:列表、数据框 # 第二个角度 #一维结构:向量、矩阵 #二维结构:矩阵、数据框 #三维或三维以上结构:数组
选中要运行的代码,执行运行
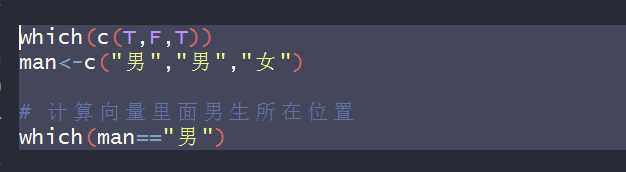

# 必知必会的函数 #which\which.max()\which.min() # which:返回一个逻辑向量里面真值所在位置 which(c(T,F,T)) man<-c("男","男","女") # 计算向量里面男生所在位置 which(man=="男") # which.max():返回一个向量里面最大值所在位置 which.max(c(3,4,7)) # which.min():返回一个向量里面最大值所在位置 which.min(c(3,4,7)) # 排序 # 第一种:直接排序 x<-c(7,5,8,9,2) sort(x) x<-sort(x) #降序排序 sort(x,decreasing = T) # 第二种:间接排序 order(x) #第三种:倒着排 rev(x)
标签:维数 形式 首字母 绘图 接口 帮助 studio rev 运行
原文地址:https://www.cnblogs.com/foremostxl/p/11984711.html