标签:rom 出现 chrome 背景 str alt 去除 beautiful 分词
爬虫:requests,beautifulsoup
词云:wordcloud,jieba
代码加注释:
1 # -*- coding: utf-8 -*- 2 import xlrd#读取excel 3 import xlwt#写入excel 4 import requests 5 import linecache 6 import wordcloud 7 import jieba 8 import matplotlib.pyplot as plt 9 from bs4 import BeautifulSoup 10 11 if __name__=="__main__": 12 yun="" 13 14 n=0#ID编号 15 target=‘https://api.bilibili.com/x/v1/dm/list.so?oid=132084205‘#b站oid页 16 user_agent = ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36‘ 17 headers = {‘User-Agent‘:user_agent}#伪装浏览器 18 19 req=requests.get(url=target) 20 html=req.text 21 html=html.encode(‘ISO 8859-1‘) 22 #html=html.replace(‘<br>‘,‘ ‘).replace(‘<br/>‘,‘ ‘).replace(‘/>‘,‘>‘) 23 bf=BeautifulSoup(html,"html.parser") 24 25 texts=bf.find(‘i‘) 26 texts_div=texts.find_all(‘d‘) 27 #print(texts_div) 28 for item in texts_div: 29 n=n+1 30 item_name=item.text#标题 31 yun+=str(item_name) 34 35 yun=yun.replace(" ","") 36 yun=yun.replace("哈","") 37 yun=yun.replace("啊","") 38 yun=yun.replace("一","")#去除无意义弹幕 39 # 结巴分词,生成字符串,wordcloud无法直接生成正确的中文词云 40 cut_text = " ".join(jieba.cut(yun)) 41 wc = wordcloud.WordCloud( 42 #设置字体,不然会出现口字乱码,文字的路径是电脑的字体一般路径,可以换成别的 43 font_path="C:/Windows/Fonts/simfang.ttf", 44 #设置了背景,宽高 45 background_color="white",width=1000,height=880).generate(cut_text) 46 47 plt.imshow(wc, interpolation="bilinear") 48 plt.axis("off") 49 plt.show() 50 print("Done!")
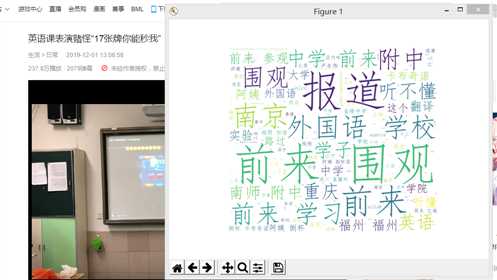
运行结果图:
标签:rom 出现 chrome 背景 str alt 去除 beautiful 分词
原文地址:https://www.cnblogs.com/ljy1227476113/p/12000264.html