标签:style blog http color os ar 使用 for sp
7.1文本处理的用途
总的来说,文本处理背后的全部思想是找到目标文本。当然,有的情况下数据以结构化的方式组织,这就是所谓的数据库。然而有些数据资源包含的信息完全不是有序和规整的,例如成百上千的文件的目录结构。当需要查找这种类型的数据或者以某种方式处理它们,文本处理就非常实用。也可以同RDBMS(关系数据库管理系统)结合起来查找。
文本处理领域的两个主要的工具是目录导航和一种称为正则表达式的神奇技术。
目录导航:是一个不同的操作系统真正给简单的程序带来大量麻烦的领域,因为三个主要的操作系统的家族都是以不同的方式组织它们的目录;而且,最棘手的是,他们使用不同的字符分隔子目录。pyth考虑到这个问题,提供了一系列跨平台工具来执行目录和路径操作。
正则表达式:是指定一个分厂简单的文本解析器的方法,对任意多行文本进行处理时,这种文本解析器的开销很低,意味着速度很快。
首先看一些需要编写文本处理脚本的原因,然后用新知识做一些试验。
使用正则表达式最普遍的原因包括:
搜索文件
从程序日志(例如web服务器日志)中提取有用的数据
搜索电子邮件
7.1.1搜索文件
当面对一个任务需要执行大量手工工作来处理计算机上的数据时,考虑使用python,写一两个脚本能过节省几个小时的单调工作。
还有一个类似的情况是当今大硬盘的附带结果,很多用户在硬盘上零散地存放文件,也没空去组织它们,当面对一个装满文件的硬盘,需要从中提取一些知道肯定存在,但又不知道确切位置的信息时,情况会很糟糕。所以,像很多公司都提供了桌面搜索的功能。
可以把python看作是加强版的桌面搜索功能。
7.1.2日志剪辑
系统管理中另一个普遍的文本处理任务是需要过滤日志得到各种信息。过滤日志的脚本可以是回答特定问题的临时想法。如电子邮件声明时候发送,或者最近一次我的程序记录一条特定的消息是什么时候?或者它们可能是数据处理系统的永久部分,随着时间变化可以管理正在进行的任务。例如,他们可以是系统管理和性能监视系统的一部分,脚本按规则过滤日志,得到信息的特定子集,这通常被称为日志剪辑,其思想是,就像可以裁剪多边形来适合屏幕,也可以来裁剪日志适合需要的任何系统视角。
7.1.3邮件筛选
最后的文本处理任务您大概已经发现是很有用的:通过邮箱文件的处理来找到正常的收件箱搜索不能找到的东西。
然而搜索脚本要从外部数据源得到数据,例如网页或者其他数据源,如数据库,来交叉引用数据或在搜索中完成其他不能使用普通邮件客户端完成的任务,对于这种情况,结合使用文本处理和其他技术可能是一个非常有用的方法,能够采用其他方法不容易找到的信息。
7.2使用os模块导航文件系统
对于必须在许多不同的平台上执行的日常任务,os模块和他的子模块os.path是最有用的工具之一了。
写跨平台脚本的其中一个困难在于windows下用反斜杠(\)分隔目录名,但是UNIX下用(/)。而且,python用反斜杠字符表示特殊文本,这让windows上创建文件路径的脚本变得很复杂。
然而python的os.path模块可以得到一些现成的函数,它们可以使用正确的字符为您分割和链接路径名,并且能在任何正在运用python的操作系统上正确地工作。可以用单个函数来迭代目录结构,并对它在层次结构中找到的每个文件调用自己选择的另一个函数。您将在下面的例子中看到许多这样的函数,但是首先看一个os和os.path模块中将被用到的一些有用的函数的综述。



列出文件并处理路径
(1)在python解释器中导入os和os.path模块:
>>>import os, os.path
(2)首先看您在哪个文件系统中运行
>>>os.getcwd() ‘C:\\python31‘
(3)如果要用程序进行处理,可以把它拆分成路径的元组

(4)为了找到一些关于目录或任何文件的感兴趣的信息,使用os.start:

注意:名为"."的目录是当前目录的简单表示。
(5)如果实际上想要列出目录中的文件,可以使用下面代码:

注意两点:1.listdir、split和star构造一个迭代脚本,但是并不需要这么做, os.path提供了walk函数来实现这种功能。2.来自系统调用的stat调用是很不透明的,它返回的元组对应于posixc的同名库函数返回的结构。
搜索特殊类型的文件
如果使用其他编程语言,会感觉到使用python搜索文件是多么简单。os.walk可以完成文件系统迭代的所有繁重工作,您只需写一个简单的函数,对它叨叨的结果执行参数即可。
(1)使用自己喜欢的文本编辑器,在想要扫描的pdf文件的目录中打开一个名为scan_pdf.py的脚本,并输入下面代码:
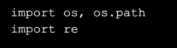
(2)运行该脚本:
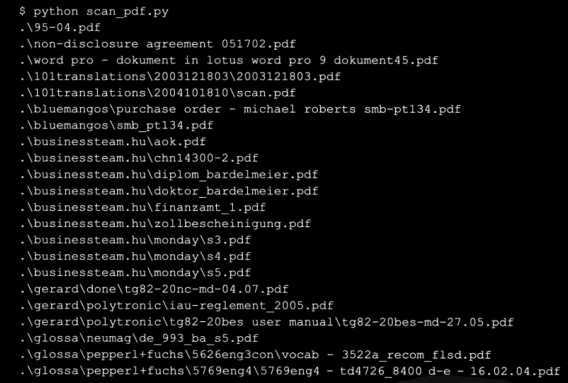
这是一个不错的小脚本,python做了所有的工作,使您得到目录中的pdf文件的列表,包括它们的位置及全名,位置中甚至带有空格,在unix和linux上这是很难处理的。
注意,代码中使用了一个非常简单的正则表达式来检查文件名结尾,也可以使用os.path.splitext得到包括文件的基本名和扩展名的元组,并和pdf比较,这样可能更清晰。
形式r"<string constant>"简单地告诉python,字符串常量应该禁止对反斜杠做出任何特殊处理,这样,"\n"是一个单个字母长度的,相当于一个新行的字符串,而r"\n"是两个字母长度的字符串,表示反斜杠字符后面跟着一个字母"n"。因为正则表达式总是包括很多反斜杠。
改进搜索
还想排除名称中有一个空格的所有pdf文件,例如,因为正在搜索的文件是从网站下载的,实际上没有空格,但是很多接受的电子邮件消息中包含的文件是别人文件系统的附件,所以经常包含空格,因此这个改进非常合适。
import os, os.path import re def print_pdf(arg, dir, files): for file in files: path = os.path.join(dir, file) path = os.path.normcase(path) if not re.search(r".*\.pdf", path): continue if re.search(r" ", path):continue print(path) for root, dirs, files in os.walk(‘.‘):
(2)现在运行修改后的脚本。同样这个输出结果将同你的系统不一致。

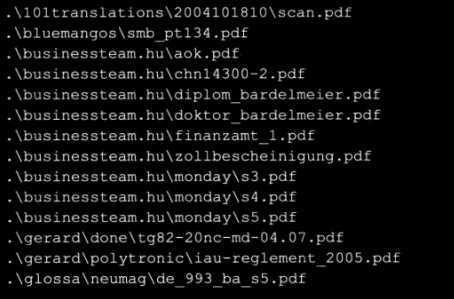
这个代码有一个格式上的修改,当作为这些面向快速文本处理的过滤器脚本时工作得很好。看看代码中的print_pdf函数,它首先建立和规范化路径名,然后对他们运行测试以保证得到象牙哦的路径名。
7.3使用正则表达式和re模块
一个正则表达式定义了一个简单的解析器,可以匹配文本中的字符串。当使用正则表达式在命令行上指定多个文件时,它们在本质上以和通配符一样的方式工作。
正则表达式和简单的通配符之间存在两个主要的不同:
.正则表达式可以在长字符串的任何位置匹配多次。
.正则表达式复杂得多,也丰富得多。
练习正则表达式
使用filter函数,对于其输入列表的每个成员应用带有一个参数的函数,而re.match和re.search有两个参数,所以您不得不使用函数定义或者匿名lambda形式。
(1)打开python解析器并导入re模块:
$ python >>> import re
(2)现在,使用各种正则表达式定义一个要过滤的字符串列表:
>>>s =(‘xxx‘,‘abcxxxabc‘,‘xyx‘,‘abc‘,‘x.x‘,‘axa‘,‘axxxa‘,‘axxya‘)
(3)首先执行最简单的正则表达式:
>>>a = filter((lambda s:re.match(r"xxx",s)),s) >>>print(*a) xxx
(4)为什么没有找到“axxxxa”?这是因为,python中re.match函数自从它输入的开始搜索匹配。这时需要re.search:

(5)搜索那个语句:

(6)下面的代码显示了如何只匹配句点(通过转义特殊字符):

(7)也可以通过使用星号:

(8)为什么axxya也会匹配成功,因为*代表0个或者多个字符,如果确实想要确保两个x之间有字符,可以使用一个加号。

(9)如果匹配其中有一个“c”的任何字符串:

(10)如何匹配没有“c”的任何字符?正则表达式使用方括号表示要匹配的特殊字符集。

(11)这居然把整个列表都匹配出来了。上面没有把^用对地方,为了清楚地说明,可以过滤一个具有很多c的列表:

(12)为了真正匹配其中没有一个"c"的任何字符串,必须在字符串的开始和结束使用^和$特殊字符,然后告诉re您想要的是从头到尾不包含c字符的字符串:

添加测试:
(1)再次使用喜欢的文本编辑器打开scan_pdf.py,并做下面修改。修改的部分用斜体表示:
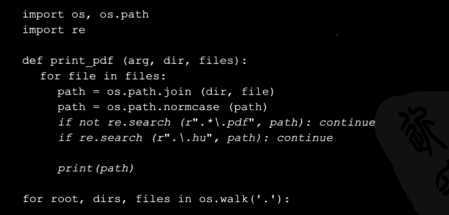
(2)现在运行修改后的脚本,这个输出将同您的系统中输出不一致:

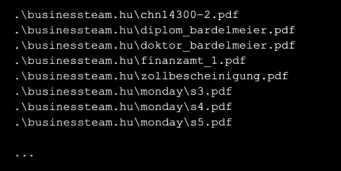
在这个例子中,测试只搜索在名称中有一个.hu的文件名(其包括完整的路径)。这里的假设是名称中有一个.hu的文件是匈牙利的国家代码。因此这个例子表明如何缩小搜索范围,仅搜索从匈牙利语翻译过来的文件。
标签:style blog http color os ar 使用 for sp
原文地址:http://www.cnblogs.com/romanhzzz/p/4059826.html