标签:body ali password iss 知识 into reg div 运算
一、MySQL联结表:
预备知识:
1、关系表:把信息分解成多个表,一类数据一个表,各表通过某些共同的值相互关联(所以才称为关系数据库)。
2、联结:联结是一种机制,用来在一条SELECT语句中关联表,因此称为联结。通过联结,一条SELECT语句可以联结多个表返回一组输出。
3、完全限定列名:表名+.+列名。
4、笛卡儿积(叉联积):由没有联结条件表关系返回的结果为笛卡儿积,结果的行数是第一个表的行数乘以第二个表的行数。
5、表别名和列别名(SQL 一个别名只存在于查询期间。表别名只会在查询执行中使用。与列别名不同,表别名不返回MySQL客户端):SELECT 列名 AS 列别名 FROM 表名 AS 表别名 (Oracle中没有AS,别名设置不用AS,直接指定别名即可)
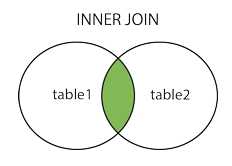
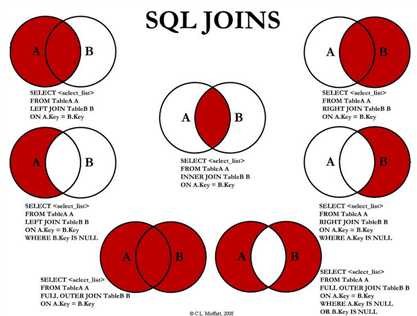
一、INNER JOIN(内连接/等值连接)--获取两个表中字段匹配关系的记录;
mysql> SELECT a.runoob_id, a.runoob_author, b.runoob_count FROM runoob_tbl a INNER JOIN tcount_tbl b ON a.runoob_author = b.runoob_author; mysql> SELECT a.runoob_id, a.runoob_author, b.runoob_count FROM runoob_tbl a, tcount_tbl b WHERE a.runoob_author = b.runoob_author;
二、自联结(self-join):自联结通常用作外部语句,用来代替从相同表中检索数据使用的子查询语句。一个SELECT语句查询两次查询是同一个表,但是使用相同的表名,DBMS会有歧义。通过设置表别名,DBMS处理联结远比处理子查询快得多!
mysql> SELECT a.runoob_id, a.runoob_author FROM runoob_tbl_a AS a, runoob_tbl_a AS b where a.runoob_author = b.runoob_author and b.runoob_name=‘c++‘;
三、自然联结(natural join):被联结的表至少有一列不止出现在一个表(被联结的列存在于多个表),标准的联结返回所有的数据,相同的列甚至多次出现!自然联结排除多次出现,使每一列只返回一次。通过对一个表使用通配符(SELECT*),而对其他表的列使用明确的子集来完成。
mysql> SELECT C。*,O.order_num,O.order_date,OI.prod_id,OI.quantity,OI.item_price
->FROM Cuntomers AS C,Orders AS O,OrderItems AS OI
->WHERE C.cust_id=O.cust_id AND OI.order_num = O.order_num AND prod_id =‘AS‘
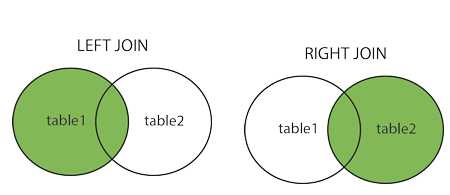
四、外联结(outer join):LEFT (OUTER)JOIN(左连接)--获取左表所有记录。如果右表没有对应匹配的记录,右表数据字段值用NULL表示;
RIGHT(OUTER) JOIN(右连接)--获取右表所有记录,如果左表没有对应匹配的记录,左表数据字段值用NULL表示;
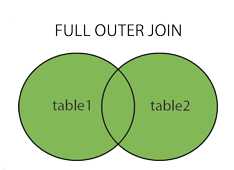
FULL OUTER JOIN
mysql> SELECT a.runoob_id, a.runoob_author, b.runoob_count FROM runoob_tbl a LEFT JOIN tcount_tbl b ON a.runoob_author = b.runoob_author; mysql> SELECT a.runoob_id, a.runoob_author, b.runoob_count FROM runoob_tbl a RIGHT JOIN tcount_tbl b ON a.runoob_author = b.runoob_author; mysql> select column_name(s) from table 1 FULL OUTER JOIN table 2 ON table 1.column_name=table 2.column_name;
二、数据表column中有null字段:
1、IS NULL
2、IS NOT NULL
3、<=>: 比较操作符(不同于=运算符),当比较的的两个值为 NULL 时返回 true
注:
where语句判断列的值是否为null,where column_name IS NULL;where column_name IS NOT NULL
三、MySQL 正则表达式:MySQL中使用 REGEXP 操作符来进行正则表达式匹配
mysql> SELECT name FROM person_tbl WHERE name REGEXP ‘^st‘;
表-1 正则表达式模式说明
| 模式 | 描述 |
|---|---|
| ^ | 匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 ‘\n‘ 或 ‘\r‘ 之后的位置。 |
| $ | 匹配输入字符串的结束位置。如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 ‘\n‘ 或 ‘\r‘ 之前的位置。 |
| . | 匹配除 "\n" 之外的任何单个字符。要匹配包括 ‘\n‘ 在内的任何字符,请使用象 ‘[.\n]‘ 的模式。 |
| [...] | 字符集合。匹配所包含的任意一个字符。例如, ‘[abc]‘ 可以匹配 "plain" 中的 ‘a‘。 |
| [^...] | 负值字符集合。匹配未包含的任意字符。例如, ‘[^abc]‘ 可以匹配 "plain" 中的‘p‘。 |
| p1|p2|p3 | 匹配 p1 或 p2 或 p3。例如,‘z|food‘ 能匹配 "z" 或 "food"。‘(z|f)ood‘ 则匹配 "zood" 或 "food"。 |
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,‘zo+‘ 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,‘o{2}‘ 不能匹配 "Bob" 中的 ‘o‘,但是能匹配 "food" 中的两个 o。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。 |
四、MySQL 事务:
1、在 MySQL 中,只有使用了 Innodb 数据库引擎的数据库或表才支持事务
2、事务是必须满足4个条件(ACID)::原子性(Atomicity,或称不可分割性)、一致性(Consistency)、隔离性(Isolation,又称独立性)、持久性(Durability)
一、原子性:事务中的命令要么全部执行完成,要么全部不执行。如果在队列命令中间发生错误,MySQL支持rollback(回滚)到事务开始前的状态,就像整个事务从来没有被执行一样。
二、一致性:分布式系统的数据一致性与集中式系统的数据一致性。
分布式系统:某个数据存在了三个服务器上。如果数据要更新,就必须保证三个服务器上数据全都更新好,如果有一个没有成功,那么其他两个也应该维持不变,
集中式系统:数据只存储在服务器,没有数据副本的概念。数据一致性就需要用户来定义,也就是ACID链接里的valid状态,其实由用户来定义。一致性模型则可以认为是存储系统和数据使用者之间的一种约定。一般情况下,数据一致性通常指关联数据之间的逻辑关系(用户定义的一致性状态)是否正确和完整。
三、隔离性:数据库允许多个并发事务同时对其数据进行读写和修改的能力。InnoDB 存储引擎提供事务的隔离级别:读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)
四、持久性:当一个事务执行完成后,执行事务所得的结果已经被保存到永久性存储介质中,对数据的修改是永久的,即使系统故障也不会丢失。
4、MYSQL 事务处理:BEGIN(开始一个事务), ROLLBACK(事务回滚), COMMIT(事务确认);MySQL还支持保存点操作:创建保存点:SAVEPOINT identifier、删除保存点:RELEASE SAVEPOINT identifier、把事务回滚到保存点:ROLLBACK TO identifier
五、ALTER命令修改数据表名和数据表字段
# 在 ALTER TABLE 语句中使用 RENAME 子句修改数据表名 mysql> ALTER TABLE testalter_tbl RENAME TO alter_tbl; # 通过使用DROP、ADD删除和增加字段 mysql> ALTER TABLE testalter_tbl DROP i; mysql> ALTER TABLE testalter_tbl ADD i INT; ALTER TABLE testalter_tbl ADD i INT FIRST; ALTER TABLE testalter_tbl DROP i; ALTER TABLE testalter_tbl ADD i INT AFTER c; # 通过使用 MODIFY 或 CHANGE 子句修改字段类型及名称 mysql> ALTER TABLE testalter_tbl MODIFY c CHAR(10); mysql> ALTER TABLE testalter_tbl CHANGE i j BIGINT NOT NULL DEFAULT 100; # 通过SET和DROP子句修改DEFAULT mysql> ALTER TABLE testalter_tbl ALTER i SET DEFAULT 1000; mysql> ALTER TABLE testalter_tbl ALTER i DROP DEFAULT;
注:当数据表只有一个字段时,不能通过DROP删除字段。
1、设置索引的三种方法:创建索引(create);修改表结构,添加索引(alter);创建表时直接指定字段作为索引。
1、MySQL临时表用于存储临时数据,临时表只在当前连接可见,当关闭连接,MySQL自动删除临时表并释放空间。
# 创建临时表(TEMPORARY TABLE)
mysql> CREATE TEMPORARY TABLE SalesSummary (
-> product_name VARCHAR(50) NOT NULL
-> , total_sales DECIMAL(12,2) NOT NULL DEFAULT 0.00
-> , avg_unit_price DECIMAL(7,2) NOT NULL DEFAULT 0.00
-> , total_units_sold INT UNSIGNED NOT NULL DEFAULT 0
);
# 删除临时表
mysql> DROP TABLE SalesSummary;
1、MySQL复制表,第一步、需要获取创建数据表的SQL语句,从而创建一样数据表名,数据表字段,默认值一致,索引一致的数据表结构;第二步、将源数据表的各个数据表字段的值全部复制到目标数据表字段中。
第一步:SHOW CREATE TABLE 语句
mysql> SHOW CREATE TABLE runoob_tbl \G;
第二步:INSERT INTO ... SELECT 语句
mysql> INSERT INTO clone_tbl (runoob_id,
-> runoob_title,
-> runoob_author,
-> submission_date)
-> SELECT runoob_id,runoob_title,
-> runoob_author,submission_date
-> FROM runoob_tbl;
1、防止出现重复数据:primary key和unique进行数据表字段属性约束“唯一性”
2、统计重复数据:确定哪个数据表字段的值可能会重复>>SELECET COUNT(*) as repetiions列出这些数据表字段>>在GROUP BY子句中列出的列>>HAVING子句设置重复数大于 1(HAVING repetitions > 1)
3、过滤重复数据:SELECT 语句中使用 DISTINCT 关键字来过滤重复数据或者使用GROUP BY 来读取数据表中不重复的数据
SELECT 语句中使用 DISTINCT 关键字:
mysql> SELECT DISTINCT last_name, first_name
-> FROM person_tbl;
使用GROUP BY 来读取数据表中不重复的数据:
mysql> SELECT last_name, first_name
-> FROM person_tbl
-> GROUP BY (last_name, first_name);
4、删除重复数据:
使用SQL语句:
mysql> CREATE TABLE tmp SELECT last_name, first_name, sex FROM person_tbl GROUP BY (last_name, first_name, sex); mysql> DROP TABLE person_tbl; mysql> ALTER TABLE tmp RENAME TO person_tbl;
在数据表中添加 INDEX(索引) 和 PRIMAY KEY(主键)删除表中的重复记录:
mysql> ALTER IGNORE TABLE person_tbl
-> ADD PRIMARY KEY (last_name, first_name);
1、使用SELECT...INTO OUTFILE语句来简单的导出数据到文本文件,并设置数据输出的指定格式,类似redis的RDB持久化。
mysql> SELECT * FROM passwd INTO OUTFILE ‘/tmp/runoob.txt‘
-> FIELDS TERMINATED BY ‘,‘ ENCLOSED BY ‘"‘
-> LINES TERMINATED BY ‘\r\n‘;
2、mysqldump 是 mysql 用于转存储数据库的实用程序。可以读取数据库的数据也可以将创建数据库所需的命令保存。
mysqldump 产生一个SQL脚本,其中包含从头重新创建数据库所必需的命令 CREATE TABLE INSERT 等。类似AOF持久化。使用 mysqldump 导出数据库的必须命令需要使用 --tab 选项来指定导出文件指定的目录,该目标必须是可写的:
$ mysqldump -u root -p --no-create-info --tab=/tmp RUNOOB runoob_tbl password ******
mysqldump导出包含命令的文件中的数据
$ mysqldump -u root -p RUNOOB runoob_tbl > dump.txt password ******
mysqldump导出数据库数据
$ mysqldump -u root -p RUNOOB > database_dump.txt password ******
mysqldump备份数据库数据
$ mysqldump -u root -p --all-databases > database_dump.txt password ******
mysqldump将数据库数据导入MySQL服务器
$ mysql -u root -p database_name < database_dump.txt password *****
mysqldump指定数据库及数据表,通过管道将导出的数据导入到指定的远程主机上
$ mysqldump -u root -p database_name | mysql -h other-host.com database_name
标签:body ali password iss 知识 into reg div 运算
原文地址:https://www.cnblogs.com/yinminbo/p/11792126.html