标签:int 条件 使用 type 爬虫 嵌套 属性 首页 find
使用requests库获取html页面并将其转换成字符串之后,需要进一步解析html页面格式,提取有用信息。
BeautifulSoup4库,也被成为bs4库(后皆采用简写)用于解析和处理html和xml。
1.调用
bs4库中最主要的便是bs类了,每个实例化的对象都相当于一个html页面
需要采用from-import导入bs类,同时通过BeautifulSoup()创建一个bs对象
代码如下:
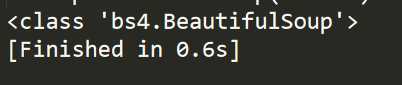
import requests from bs4 import BeautifulSoup r=requests.get("https://www.baidu.com/") r.encoding="utf-8" soup=BeautifulSoup(r.text) print(type(soup))
运行结果:
2.常用属性
创建的BeautifulSoup对象是一个树形结构,它包含html页面中的每一个Tag(标签)元素,可以通过<a>.<b>的形式获得
常见的属性如下:
head:
html页面<head>内容
title:
html页面标题,在<head>之中,由<title>标记
body:
html页面<body>内容
p:
html页面第一个<p>内容
strings:
html页面所有呈现在web上的字符串,即标签的内容
stripped_string:
html页面所有呈现在web上的非空字符串

接下来尝试爬取百度的标语“百度一下,你就知道”
首先我们通过requests来建立请求,可以通过查看源代码找到对应部分
如下所示:
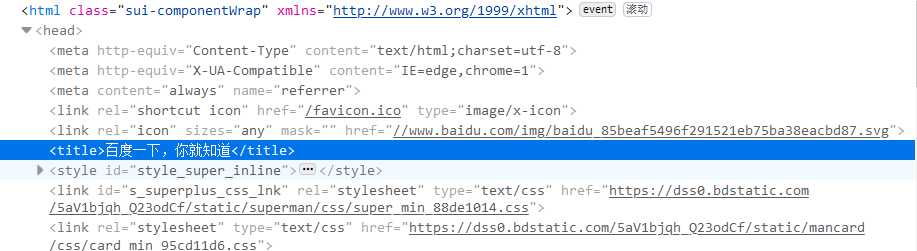
所以直接通过调用<title>标签即可
代码如下:
import requests from bs4 import BeautifulSoup r=requests.get("https://www.baidu.com/") r.encoding="utf-8" soup=BeautifulSoup(r.text) title=soup.title print(title)
结果如图所示:

3.标签常用属性
每一个标签在bs4中也是一个对象,被称为tag对象,以糯米为例,常见结构如下:
<a class=“mnav” href="http://www.nuomi.com">糯米</a>
其中尖括号(<>)中标签的名字为 name,其他项为attrs,尖括号之间的内容为string
所以常见的标签属性分为4种
name:
字符串、标签的名字
attrs:
字典、包含了原来页面tag的所有属性,比如href
contrnts:
列表、tag下所有子tag的内容
string:
字符串、tag所包含的文本,网页中的真实文字
由于html可以在标签中嵌套其他的标签,所以string返回遵循以下原则
①如果标签内没有其他标签,string属性返回其中的内容
②如果标签内部还有标签,但只有一个标签,string返回最里面的标签内容
③如果内部超过1层嵌套标签,则返回为none
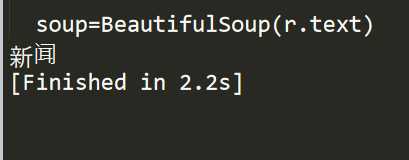
依然以百度为例,我们需要找到第一个<a>标签的string代码应当如下:
import requests from bs4 import BeautifulSoup r=requests.get("https://www.baidu.com/") r.encoding="utf-8" soup=BeautifulSoup(r.text) print(soup.a.string)
结果如图所示:
4.调用find()与find_all()
html中,同一个特标签会有很多内容,比如百度首页<a>一共有13处,但值返回第一处
所以这时候需要通过find与find_all来寻找,这两个方法都会遍历html文档按照条件返回内容
使用方法如下:
BeautifulSoup.find_all(name,attrs,recursive,string,limit)
name:以标签名字进行搜索,名字用字符串类型表示
attrs:按照标签的属性来搜索,需要列出属性的名字和值,用json方法表示
recursive:设置查找层次,只查找当前标签的西一层时使用recursiv=false
string:按照关键字查找string属性内容,采用string=开始
limit:返回结果个数,默认全部
至于find()使用方法如find_all()相同,
BeautifulSoup.find_all(name,attrs,recursive,string)
区别在于find()只搜索第一个结果,find_all()返回所有结果。
我们尝试来通过find_all()来获取所有含有“百度”这一关键词的标签
首先需要调用re库,re是python的标准库可以采用compile()对字符串的检索
所以代码如下:
import requests import re from bs4 import BeautifulSoup r=requests.get("https://www.baidu.com/") r.encoding="utf-8" soup=BeautifulSoup(r.text) w=soup.find_all(string=re.compile("百度")) print(w)
结果如下:

Python网络爬虫——BeautifulSoup4库的使用
标签:int 条件 使用 type 爬虫 嵌套 属性 首页 find
原文地址:https://www.cnblogs.com/lyy135146/p/12005188.html