标签:cal ssi 数据库连接 oca cursor nump 数据库设计 mac 下载器
1、案例内容简介
易车网新车信息的爬取
内容步骤:
爬取,解析(动态requests+ajax/selenium),清洗,持久化(mysql),可视化(seaborn)
2、案例分析与设计
(1) 系统框架
整个框架分为六个模块:爬虫调度器、URL管理器、HTML下载器、HTML解析器、数据存储器、数据可视化
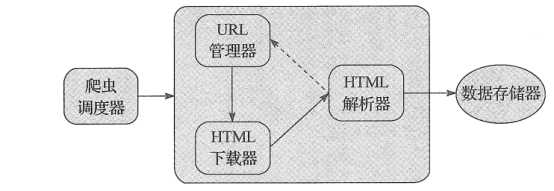
(2) 数据库设计
用于记录奥迪汽车信息
表ad_data
|
id |
Int |
自增主键 |
|
name |
Varchar(255) |
汽车名称 |
|
time_to_market |
Varchar(255) |
上市时间 |
disc |
Varchar(255) |
简介 |
img_url |
Varchar(255) |
车图片地址 |
|
level |
Varchar(255) |
车型 |
3、案例代码实现
(1) 爬虫调度器模块
主要负责其他模块的协调工作
文件相对地址(文件名):新车/SpiderMan.py
#coding:utf-8 from DataOutput import DataOutput from UrlManager import UrlManager from HtmlParser import HtmlParser from SeabornShow import SeabornShow from HtmlDownloader import HtmlDownloader import seaborn as sns class SpiderMan(object): def __init__(self): self.manager = UrlManager() self.downloader = HtmlDownloader() self.parser = HtmlParser() self.output = DataOutput() self.show = SeabornShow() def crawl(self,root_url): self.manager.add_new_url(root_url) while (self.manager.has_new_url()): try: new_url = self.manager.get_new_url() print("》》开始下载内容") html = self.downloader.download(new_url) print("》》开始解析下载的数据") new_urls,data = self.parser.parser(new_url,html) self.output.store_data(data) except: print("crawl failed") print("》》对解析的数据进行mysql数据库持久化操作") self.output.output_mysql() # 数据帧格式数据 df = self.output.mysql_to_pandas() print("》》柱状图展示新车型的数量") self.show.show(df) if __name__ == "__main__": spider_man = SpiderMan() # 新车列表页地址: http://news.bitauto.com/xinche/ssxc/ aodi = "http://news.bitauto.com/xinche/ssxc/" spider_man.crawl(aodi)
(2) Url管理模块
维护爬取的url,跟未爬取的url地址
文件相对地址(文件名):新车/HtmlDownloader.py
#coding:utf-8 ‘‘‘ url管理器 ‘‘‘ class UrlManager(object): def __init__(self): self.new_urls = set() self.old_urls = set() def has_new_url(self): ‘‘‘ 判断是否有url未被爬取 :return: ‘‘‘ return self.new_url_size() != 0 def get_new_url(self): ‘‘‘ 获取url :return: ‘‘‘ if self.has_new_url(): new_url = self.new_urls.pop() self.old_urls.add(new_url) return new_url else: return None def add_new_url(self,url): ‘‘‘ 增加url :param url: :return: ‘‘‘ if url is None: return ‘‘‘ 增加时去重跟判断以处理的url避免重复处理出现死循环 ‘‘‘ if url not in self.new_urls and url not in self.old_urls: self.new_urls.add(url) def add_new_urls(self,urls): ‘‘‘ 增加一组url :param urls: :return: ‘‘‘ if urls is None or len(urls)==0: return for url in urls: self.add_new_url(url) def new_url_size(self): return len(self.new_urls) def old_url_size(self): return len(self.old_urls)
(3) HTML下载模块
负责下载url管理器中提供的未爬url链接并返回html
文件相对地址(文件名):新车/HtmlDownloader.py
#coding:utf-8 import requests import chardet import json ‘‘‘ html下载器 ‘‘‘ class HtmlDownloader(object): def download(self,url): try: if url is None: return sessions = requests.session() # sessions.headers[ # ‘User-Agent‘] = ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.131 Safari/537.36‘ header = { ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36‘, ‘Referer‘: ‘http://news.bitauto.com/xinche/ssxc/‘ } url = ‘http://api.car.bitauto.com/CarInfo/GetNewCarIntoMarket.ashx?callback=GetNewCarIntoMarket&type=cars&year=2019&month=12&pageindex=1&pagesize=20‘ r = sessions.get(url, headers=header) print(r.status_code) if (r.status_code == 200): return r.text return None except: print("downloader failed") if __name__ == "__main__": htmlDownloader = HtmlDownloader() # 奥迪 url = "http://car.bitauto.com/tree_chexing/mb_9/" url = "http://api.car.bitauto.com/CarInfo/GetNewCarIntoMarket.ashx?callback=GetNewCarIntoMarket&type=cars&year=2019&month=2&pageindex=1&pagesize=20" print(htmlDownloader.download(url))
(4) HTML解析模块
解析下载器的html页面,并解析出有效数据,也可以解析跟进的url链接
文件相对地址(文件名):新车/HtmlParser.py
#coding:utf-8 import re import urlparser import urllib import urllib3 from bs4 import BeautifulSoup import json ‘‘‘ html解释器 ‘‘‘ class HtmlParser(object): def parser(self,page_url,html_cont): ‘‘‘ 用于解析网页内容,抽取URL和数据 :param page_url:下载页面的url :param html_cont:下载的网页内容 :return: ‘‘‘ try: if page_url is None and html_cont is None: return # soup = BeautifulSoup(html_cont, "html.parser") # 获取页面新跟进的地址 预留 new_urls = self._get_new_urls(page_url, html_cont) new_datas = self._get_new_data(page_url, html_cont) return new_urls, new_datas except: print("paser failed") ‘‘‘ 获取跟进地址方法 ‘‘‘ def _get_new_urls(self,page_url,soup): ‘‘‘ 抽取新的URL集合 :param page_url: :param soup: :return: ‘‘‘ new_urls = set() return new_urls ‘‘‘ 获取奥迪汽车信息 ‘‘‘ def _get_new_data(self,page_url,soup): newInfo = json.loads(soup[20:-1])[‘data‘] print("*******预计爬取%s 新车的信息" % newInfo[‘size‘]) return newInfo[‘data‘] if __name__ == "__main__": pass
(5) 数据存储器
将解析器解析处理的数据持久化化到mysql数据库
(包括一个数据持久化模块MasqlHelper.py)
文件相对地址(文件名):新车/DataOutput.py
#coding:utf-8 import codecs from MysqlHelper import MysqlHelper class DataOutput(object): def __init__(self): self.datas=[] self.host = "localhost" self.user = "root" self.password = "" self.database = "ai_info" self.charset = "utf-8" self.mh = MysqlHelper(self.host,self.user,self.password,self.database,self.charset) def store_data(self,data): if data is None: return self.datas = data def output_mysql(self): TABLE_NAME = "new_car" sql = "insert into " + TABLE_NAME + " (name, time_to_market, disc, img_url, level) values(%s,%s,%s,%s,%s)" rows = 0 for data in self.datas: name = data[‘CsName‘] time_to_market = str(data[‘MYear‘])+"-"+str(data[‘MMonth‘])+"-"+str(data[‘MDay‘]) disc = data[‘WillSaleNewsTitle‘] img_url = data[‘CoverImage‘] level = data[‘Level‘] params = (name, time_to_market, disc, img_url, level) row = self.mh.aud(sql,params) rows = rows + row print("*******插入%s 辆新车的信息成功!" % rows) def find_output(self): TABLE_NAME = "ad_data" sql = "select * from " + TABLE_NAME print(self.mh.find(sql, None)) ‘‘‘ 取轿车信息并转化为pandas 的数据帧类型存储 ‘‘‘ def mysql_to_pandas(self): TABLE_NAME = "new_car" sql = "select * from " + TABLE_NAME return self.mh.findPandas(sql)
文件相对地址(文件名):新车/MysqlHelper.py
import pymysql as ps import pandas as pd class MysqlHelper: def __init__(self, host, user, password, database, charset): self.host = host self.user = user self.password = password self.database = database self.charset = charset self.db = None self.curs = None # 数据库连接 def open(self): self.db = ps.connect(host=self.host, user=self.user, password=self.password,database=self.database) self.curs = self.db.cursor() # 数据库关闭 def close(self): self.curs.close() self.db.close() # 数据增删改 def aud(self, sql, params): self.open() try: row = self.curs.execute(sql, params) self.db.commit() self.close() return row except : print(‘cud出现错误‘) self.db.rollback() self.close() return 0 # 数据查询 def find(self, sql, params): self.open() try: df = pd.read_sql(sql=sql,con=self.db) print(df.head()) result = self.curs.execute(sql, params) self.close() return result except: print(‘find出现错误‘) # 解析为pandas def findPandas(self,sql): self.open() try: df = pd.read_sql(sql=sql,con=self.db) return df except: print(‘解析为pandas出现错误‘)
(6) 数据可视化模块
负责对数据库的数据进行可视化
文件相对地址(文件名):新车/SeabornShow.py
import seaborn as sns import pandas as pd import pymysql as ps import numpy as np import scipy.stats as sci import matplotlib.pyplot as plt import re # seaborn构建散点图 class SeabornShow(object): ‘‘‘ 奥迪油耗参考价数据的展示函数 ‘‘‘ def show(self,data): sns.countplot(data[‘level‘]) plt.rcParams[‘font.sans-serif‘] = [‘SimHei‘] plt.ylabel("车型数量表") plt.show() if __name__ == ‘__main__‘: seabornShow = SeabornShow() pddata = pd.DataFrame([[1, ‘ty‘, ‘12-12‘, ‘dz‘, ‘img‘, ‘SUV‘], [2, ‘ty‘, ‘12-12‘, ‘dz‘, ‘img‘, ‘SUV‘]], columns=[‘id‘, ‘name‘, ‘time_to_market‘, ‘disc‘, ‘img_url‘, ‘level‘]) sns.countplot(pddata[‘SUV‘])
4、效果跟细节
(1)代码运行步骤:
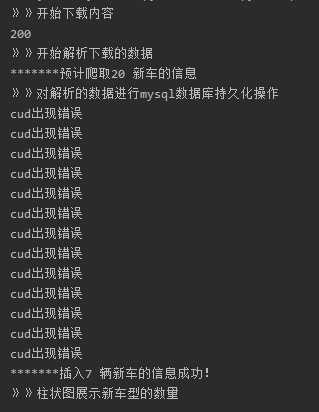
(2)数据库数据表

(3)数据显示
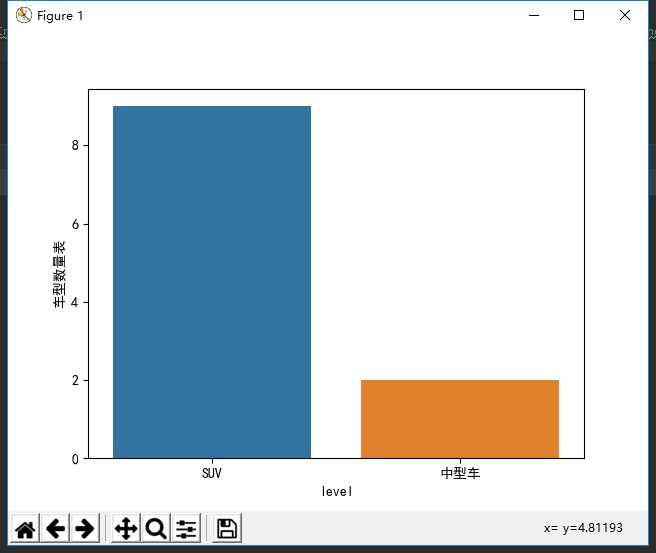
标签:cal ssi 数据库连接 oca cursor nump 数据库设计 mac 下载器
原文地址:https://www.cnblogs.com/cfz666/p/12006685.html