标签:分布 ade scribe 开启 auth erro inpu update 存储
nodeManager.py
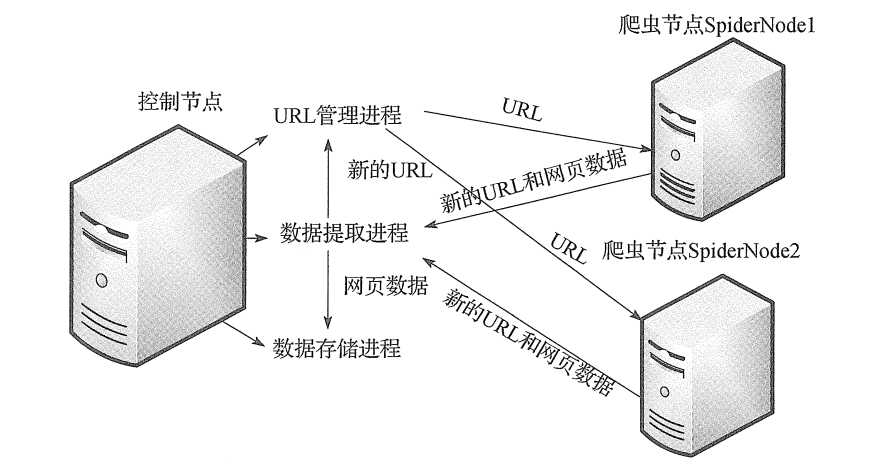
#coding:utf-8 from multiprocessing.managers import BaseManager import time import sys from multiprocessing import Process, Queue from DataOutput import DataOutput from UrlManager import UrlManager ‘‘‘ 分布式爬虫 ‘‘‘ class NodeManager(object): def __init__(self): sys.setrecursionlimit(100000000) # 设置递归分界 self.countPage = 0 def start_Manager(self, url_q, result_q): ‘‘‘ 创建一个分布式管理器 :param url_q: url队列 :param result_q: 结果队列 :return: ‘‘‘ # 把创建的两个队列注册在网络上,利用register方法,callable参数关联了Queue对象, # 将Queue对象在网络中暴露 BaseManager.register(‘get_task_queue‘, callable=lambda: url_q) BaseManager.register(‘get_result_queue‘, callable=lambda: result_q) # 绑定端口8001,设置验证口令‘baike’。这个相当于对象的初始化 manager = BaseManager(address=(‘localhost‘, 8001), authkey=‘baike‘.encode(‘utf-8‘)) # 返回manager对象 self.countPage = int(input("请爬取您想要爬取的歌手的个数(记得要在爬虫节点没开启之前输入):")) return manager def url_manager_proc(self, url_q, conn_q, root_url): # url管理进程 url_manager = UrlManager() for i in range(1,self.countPage+1):#写死表示要爬取几个列表 url = ‘https://fz.lianjia.com/chengjiao/pg‘+str(i)+"/" url_manager.add_new_url(url) while True: while (url_manager.has_new_url()): # 从URL管理器获取新的url new_url = url_manager.get_new_url() # 将新的URL发给工作节点 url_q.put(new_url) print(‘old_url=‘, url_manager.old_url_size()) def result_solve_proc(self, result_q, conn_q, store_q): # 数据提取进程 while (True): try: if not result_q.empty(): # Queue.get(block=True, timeout=None) content = result_q.get(block=True, timeout=None) if content[‘new_urls‘] == ‘end‘: # 结果分析进程接受通知然后结束 print(‘结果分析进程接受通知然后结束!‘) store_q.put(‘end‘) return store_q.put(content[‘data‘]) # 解析出来的数据为dict类型 else: time.sleep(0.1) # 延时休息 except BaseException as e: time.sleep(0.1) # 延时休息 def store_proc(self, store_q): # 数据存储进程 output = DataOutput() while True: if not store_q.empty(): data = store_q.get() if data == ‘end‘: print(‘存储进程接受通知然后结束!‘) output.add_mysql() df = output.get_house() print(">>>>>>>>>>>>>>>>>>>>二手成交房基本信息表") print(df[[‘id‘, ‘addr‘, ‘house_class‘, ‘size‘, ‘closing_time‘, ‘price‘]]) output.show(df) return output.store_data(data) else: time.sleep(0.1) pass if __name__==‘__main__‘: #初始化4个队列 url_q = Queue() result_q = Queue() store_q = Queue() # 数据提取进程存储url的队列 conn_q = Queue() # 数据提取进程存储data的队列 # 创建分布式管理器 node = NodeManager() manager = node.start_Manager(url_q,result_q) #创建URL管理进程、 数据提取进程和数据存储进程 root_url = ‘https://fz.lianjia.com/chengjiao/‘ url_manager_proc = Process(target=node.url_manager_proc, args=(url_q,conn_q,root_url,)) result_solve_proc = Process(target=node.result_solve_proc, args=(result_q,conn_q,store_q,)) store_proc = Process(target=node.store_proc, args=(store_q,)) #启动3个进程和分布式管理器 url_manager_proc.start() result_solve_proc.start() store_proc.start() manager.get_server().serve_forever()#永远服务
#coding:utf-8 import pickle import hashlib class UrlManager(object): def __init__(self): self.new_urls = set() # 未爬取的URL集合 self.old_urls = set() # 已爬取的URL集合 def has_new_url(self): ‘‘‘ 判断是否有未爬取的URL集合 :return: ‘‘‘ return self.new_url_zize() != 0 def has_old_url(self): ‘‘‘ 判断是否有以爬取的URL集合 :return: ‘‘‘ return self.old_url_size() != 0 def get_new_url(self): ‘‘‘ :return: ‘‘‘ new_url = self.new_urls.pop() self.add_old_url(new_url) return new_url def add_new_url(self,url): ‘‘‘ 将新的URL添加到未爬取的URL集合中 :param url:单个URL :return: ‘‘‘ if url is None: return None m = hashlib.md5() m.update(url.encode("utf-8")) url_md5 = m.hexdigest()[8:-8] if url not in self.new_urls and url not in self.old_urls: self.new_urls.add(url) def add_new_urls(self,urls): if urls is None and len(urls) != 0: return None for url in urls: self.add_new_url(url) def add_old_url(self,url): if url is None: return None m = hashlib.md5() m.update(url.encode("utf-8")) # m.hexdigest() 32的长度去中间的16位 self.old_urls.add(m.hexdigest()[8:-8]) return True def new_url_zize(self): ‘‘‘ 获取未爬取URL集合的大小 :return: ‘‘‘ return len(self.new_urls) def old_url_size(self): ‘‘‘ 获取已爬取URL集合的大小 :return: ‘‘‘ return len(self.old_urls) if __name__ == "__main__": urlManager = UrlManager() urlManager.get_new_url()
DataOutput.py
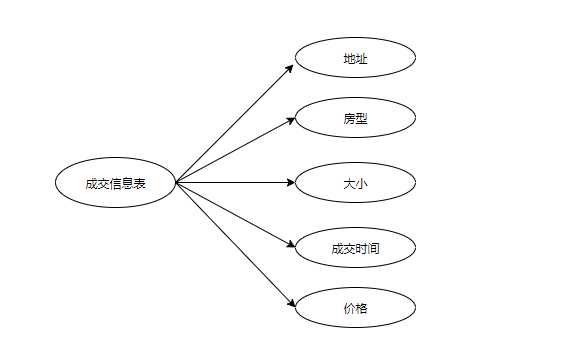
#coding:utf-8 import codecs import time import pymysql as ps import pandas as pd import matplotlib.pyplot as plt import numpy as np class DataOutput(object): def __init__(self): self.datas = [] self.host = "localhost" self.user = "root" self.password = "" self.database = "lianjia" self.charset = "utf-8" self.db = None self.curs = None def store_data(self, data): if data is None: return self.datas.append(data) def add_mysql(self): return self.output_mysql() def output_mysql(self): sql = "insert into chenjiao (addr, house_class, size, closing_time,price) values(%s,%s,%s,%s,%s)" num = 0 self.open() for data in self.datas: try: params = (data[‘addr‘], data[‘house_class‘], data[‘size‘], data[‘closing_time‘],data[‘price‘]) num = num + self.curs.execute(sql, params) self.db.commit() except: print(‘存取%s失败‘%data) self.db.rollback() self.close() return num def open(self): self.db = ps.connect(host=self.host, user=self.user, password=self.password, database=self.database) self.curs = self.db.cursor() def close(self): self.curs.close() self.db.close() def get_house(self): self.open() try: sql = sql = "select * from chenjiao order by id asc" datas = pd.read_sql(sql=sql, con=self.db) return datas self.close() except: print("显示失败!") self.close() def show(self,data): print(data.describe()) dataHouseClass = data[‘house_class‘] dataDict = {} for value in dataHouseClass.values: if value in dataDict.keys(): dataDict[value] = dataDict[value]+1 else: dataDict[value] = 1 plt.figure() plt.rcParams[‘font.sans-serif‘] = [‘SimHei‘] zone1 = plt.subplot(1,2,1) plt.bar([‘平均值‘,‘最小值‘,‘最大值‘,‘25%‘,‘50%‘,‘75%‘],[data.describe().loc[‘mean‘,‘price‘],data.describe().loc[‘min‘,‘price‘],data.describe().loc[‘max‘,‘price‘],data.describe().loc[‘25%‘,‘price‘],data.describe().loc[‘50%‘,‘price‘],data.describe().loc[‘75%‘,‘price‘]]) plt.ylabel(‘价格‘) plt.title(‘基本信息表‘) zone2 = plt.subplot(1, 2, 2) plt.pie(dataDict.values(),labels=dataDict.keys(),autopct=‘%1.1f%%‘) plt.title(‘比例图‘) plt.show()
SpiderWord.py
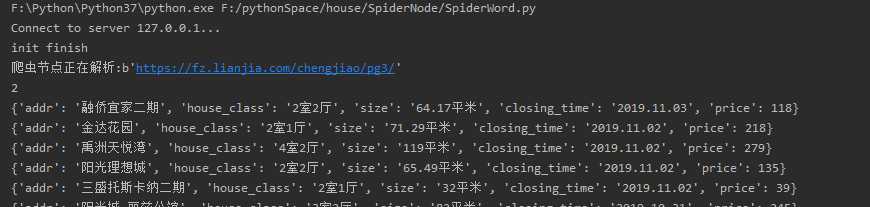
#coding:utf-8 from multiprocessing.managers import BaseManager import time import sys from HtmlDownloader import HtmlDownloader from HtmlParser import HtmlParser class SpiderWork(object): def __init__(self): sys.setrecursionlimit(1000000) # 例如这里设置为一百万 #初始化分布式进程中的工作节点的连接工作 # 实现第一步:使用BaseManager注册获取Queue的方法名称 BaseManager.register(‘get_task_queue‘) BaseManager.register(‘get_result_queue‘) # 实现第二步:连接到服务器: server_addr = ‘127.0.0.1‘ print((‘Connect to server %s...‘ % server_addr)) # 端口和验证口令注意保持与服务进程设置的完全一致: self.m = BaseManager(address=(server_addr, 8001), authkey=‘baike‘.encode(‘utf-8‘)) # 从网络连接: self.m.connect() # 实现第三步:获取Queue的对象: self.task = self.m.get_task_queue() self.result = self.m.get_result_queue() #初始化网页下载器和解析器 self.downloader = HtmlDownloader() self.parser = HtmlParser() print(‘init finish‘) def crawl(self): while(True): try: if not self.task.empty(): url = self.task.get() print(‘爬虫节点正在解析:%s‘%url.encode(‘utf-8‘)) print(self.task.qsize()) content = self.downloader.download(url) new_urls,datas = self.parser.parser(url,content) for data in datas: print(data) self.result.put({"new_urls":new_urls,"data":data}) if self.task.qsize() <= 0: print(‘爬虫节点通知控制节点停止工作...‘) #接着通知其它节点停止工作 self.result.put({‘new_urls‘:‘end‘,‘data‘:‘end‘}) return except EOFError as e: print("连接工作节点失败") return except Exception as e: print(e) print(‘Crawl faild ‘) if __name__=="__main__": spider = SpiderWork() spider.crawl()
HtmlDownloader.py
#coding:utf-8 import requests import chardet from selenium import webdriver class HtmlDownloader(object): def __init__(self): opt = webdriver.chrome.options.Options() opt.set_headless() self.browser = webdriver.Chrome(chrome_options=opt) def download(self,url): if url is None: return None self.browser.get(url) # self.browser.switch_to.frame(‘g_iframe‘) html = self.browser.page_source return html
注意:静态内容跟动态内容的爬取

HtmlParser.py
#coding:utf-8 import re import urllib.parse from bs4 import BeautifulSoup class HtmlParser(object): def parser(self,page_url,html_cont): ‘‘‘ 用于解析网页内容抽取URL和数据 :param page_url: 下载页面的URL :param html_cont: 下载的网页内容 :return:返回URL和数据 ‘‘‘ if page_url is None or html_cont is None: return soup = BeautifulSoup(html_cont,‘html.parser‘) new_urls = self._get_new_urls(page_url,soup) new_datas = self._get_new_data(page_url,soup) return new_urls,new_datas def _get_new_urls(self,page_url,soup): new_urls = set() return new_urls def _get_new_data(self,page_url,soup): ‘‘‘ 抽取有效数据 :param page_url:下载页面的URL :param soup: :return:返回有效数据 ‘‘‘ dataList = [] liList = soup.select(‘ul.listContent>li‘) for li in liList: title = li.select(‘div > div.title > a‘) result = re.split(r‘[\s]+‘, title[0].string) #使用正则表达式分割 addr = result[0] house_class = result[1] size = result[2] # 定位 eg:高楼层(共26层) 塔楼 # position = str(li.select(‘div > div.flood > div.positionInfo‘)[0].string) closing_time = str(li.select(‘div > div.address > div.dealDate‘)[0].string) #加str() 防止报:RecursionError: maximum recursion depth exceeded while pickling an object price = int(re.compile(r‘[\d]+‘).findall(li.select(‘div > div.address > div.totalPrice > span‘)[0].string)[0]) data = {‘addr‘:addr,‘house_class‘:house_class,‘size‘:size,‘closing_time‘:closing_time,‘price‘:price} dataList.append(data) return dataList
from multiprocessing.managers import BaseManager
import time
import sys
from multiprocessing import Process, Queue
import hashlib
import pymysql as ps
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import requests
import chardet
from selenium import webdriver
from bs4 import BeautifulSoup
import re
2、运行NodeManager(控制节点)---》》输入爬取的范围---》》最后运行SpiderWord(爬虫节点)
3、效果图
提前输入爬取的成交安分页个数来算,会显示出爬取地址的个数

启动爬虫节点,链接控制节点与之通信
数据进行存储
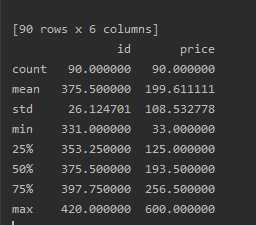
数据库内容
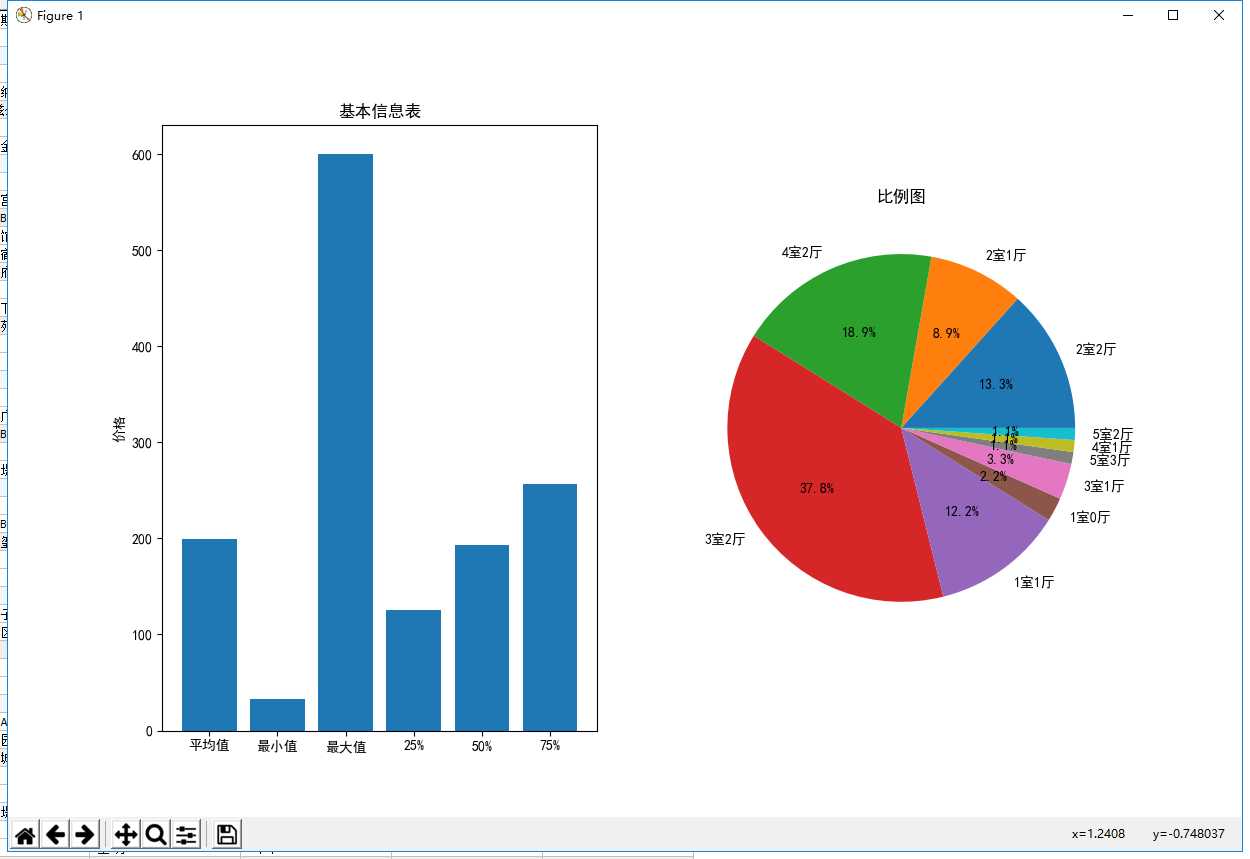
最终效果图
标签:分布 ade scribe 开启 auth erro inpu update 存储
原文地址:https://www.cnblogs.com/cfz666/p/12008342.html