标签:编译器 未定义 级别 技术 oat 算术运算 默认 table 决定
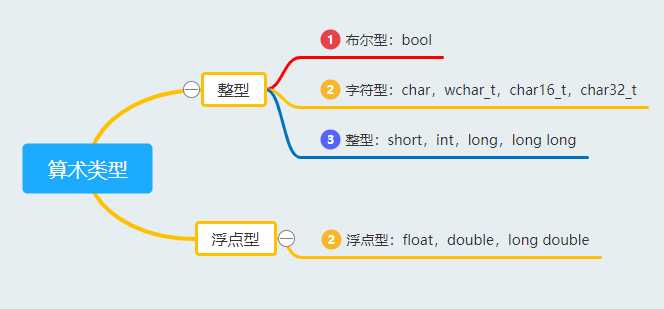
在C++提供的基本内置类型中包含了算术类型和void类型。而算术类型又分为布尔型,字符型,整型以及浮点型:
和很多“现代”语言不同,C++并没有规定其基本内置类型的具体大小(所占的bit数),标准只对以下两点提了要求:
| 类型 | 含义 | 最小长度 | 备注 |
|---|---|---|---|
| bool | 布尔值 | NA | |
| char | 字符型 | 8 bits | 大小等于一个字节 |
| wchar_t | 宽字符型 | 16 bits | |
| char16_t | unicode字符型 | 16 bits | 大小固定 |
| char32_t | unicode字符型 | 32 bits | 大小固定 |
| short | 短整型 | 16 bits | |
| int | 整型 | 16 bits | |
| long | 长整型 | 32 bits | |
| long long | 超长整型 | 64 bits | C++11标准引入 |
| float | 单精度浮点型 | 6位有效数字 | |
| double | 双精度浮点型 | 10位有效数字 | |
| long double | 扩展精度浮点型 | 10位有效数字 |
sizeof(char)等于1。signed char或者unsigned char。当然最好用int8_t或者uint8_t来做小整数运算。%lld。>>不等于算术右移:>>和<<的未定义行为:%d,float和double都是用%f的原因。int->long->long long;而对于八进制和十六进制整型字面值常量,类型推导顺序则为int->unsigned->long->unsigned long->long long->unsigned long long。对于浮点型字面值常量,类型推导顺序为double->long double。有些人觉得C++基本内置类型不定长这一设定非常落后,对源码级别的移植性造成了很大的阻碍。但我却认为这恰恰是C++的优点,因为C++将决定基本内置类型长度的权力交给了编译器实现,这样编译器就能根据具体的硬件平台来选择处理效率最高的方案。
就像刚才提到的整型字面值默认为int类型,这样做的原因就是因为int类型的处理效率往往是最高的,但每种硬件平台都有它自己的“int”类型,如果规定死了int类型的长度,那这种高效的语义也就失效了。
其实C++规定的最小长度已经可以满足很多应用场景了,当业务场景确实需要某种定长的类型的时候还有<cstdint>中定义的各种定长类型宏。这一点也符合C++语言的风格,那就是没有语言规定的最佳实践,将选择留给程序员自己。
标签:编译器 未定义 级别 技术 oat 算术运算 默认 table 决定
原文地址:https://www.cnblogs.com/HachikoT/p/12008728.html