标签:ring group 非贪婪 window target http 标志位 csdn detail
正则表达式是一个特殊的字符序列,用于简洁表达一组字符串特征,检查一个字符串是否与某种模式匹配,使用起来十分方便。
在Python中,我们通过调用re库来使用re模块:
import re
下面介绍Python常用的正则表达式处理函数。
re.match函数
re.match 函数从字符串的起始位置匹配正则表达式,返回match对象,如果不是起始位置匹配成功的话,match()就返回None。
re.match(pattern, string, flags=0)
pattern:匹配的正则表达式。
string:待匹配的字符串。
flags:标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
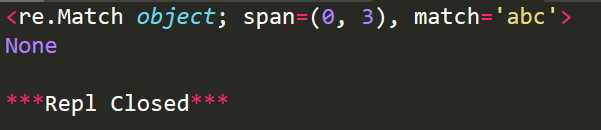
import re #从起始位置匹配 r1=re.match(‘abc‘,‘abcdefghi‘) print(r1) #不从起始位置匹配 r2=re.match(‘def‘,‘abcdefghi‘) print(r2)
运行结果:
使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
group(num):匹配的整个表达式的字符串,group() 可以一次输入多个组号,这时它将返回一个包含那些组所对应值的元组。
groups():返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。
import re s=‘This is a demo‘ r1=re.match(r‘(.*) is (.*)‘,s) r2=re.match(r‘(.*) is (.*?)‘,s) print(r1.group()) print(r1.group(1)) print(r1.group(2)) print(r1.groups()) print() print(r2.group()) print(r2.group(1)) print(r2.group(2)) print(r2.groups())
运行结果:
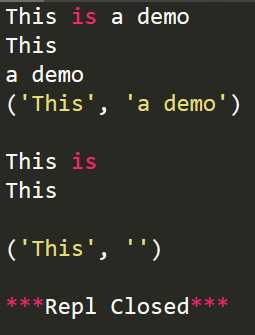
上述代码中的(.*)和(.*?)表示正则表达式的贪婪匹配与非贪婪匹配,详情见此:https://blog.csdn.net/lxcnn/article/details/4756030
re.search函数扫描整个字符串并返回第一个成功的匹配。
re.search(pattern, string, flags=0)
pattern:匹配的正则表达式。
string:待匹配的字符串。
flags:标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
import re #从起始位置匹配 r1=re.search(‘abc‘,‘abcdefghi‘) print(r1) #不从起始位置匹配 r2=re.search(‘def‘,‘abcdefghi‘) print(r2)
运行结果:
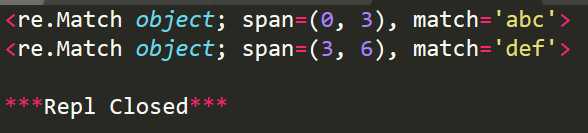
使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。匹配成功re.search方法返回match对象,否则返回None。
group(num=0):匹配的整个表达式的字符串,group() 可以一次输入多个组号,这时它将返回一个包含那些组所对应值的元组。
groups():返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。
import re s=‘This is a demo‘ r1=re.match(r‘(.*) is (.*)‘,s) r2=re.match(r‘(.*) is (.*?)‘,s) print(r1.group()) print(r1.group(1)) print(r1.group(2)) print(r1.groups()) print() print(r2.group()) print(r2.group(1)) print(r2.group(2)) print(r2.groups())
运行结果:
从上面不难发现re.match与re.search的区别:re.match只匹配字符串的起始位置,只要起始位置不符合正则表达式就匹配失败,而re.search是匹配整个字符串,直到找到一个匹配为止。
标签:ring group 非贪婪 window target http 标志位 csdn detail
原文地址:https://www.cnblogs.com/BIXIABUMO/p/12041544.html