标签:字符 老师 agent lock 利用 inf 数据 数据库 步骤

人生苦短,我用 Python
前文传送门:
小白学 Python 爬虫(2):前置准备(一)基本类库的安装
小白学 Python 爬虫(3):前置准备(二)Linux基础入门
小白学 Python 爬虫(4):前置准备(三)Docker基础入门
小白学 Python 爬虫(6):前置准备(五)爬虫框架的安装
小白学 Python 爬虫(10):Session 和 Cookies
小白学 Python 爬虫(11):urllib 基础使用(一)
小白学 Python 爬虫(12):urllib 基础使用(二)
小白学 Python 爬虫(13):urllib 基础使用(三)
小白学 Python 爬虫(14):urllib 基础使用(四)
小白学 Python 爬虫(15):urllib 基础使用(五)
小白学 Python 爬虫(16):urllib 实战之爬取妹子图
小白学 Python 爬虫(17):Requests 基础使用
前面我们在介绍 urllib 的时候也介绍过超时,我们现在来看下在 Requests 中的超时应该怎么写。
import requests
r = requests.get("https://www.geekdigging.com/", timeout = 1)
print(r.status_code)具体的执行结果小编就不贴了。
注意
timeout 仅对连接过程有效,与响应体的下载无关。 timeout 并不是整个下载响应的时间限制,而是如果服务器在 timeout 秒内没有应答,将会引发一个异常(更精确地说,是在 timeout 秒内没有从基础套接字上接收到任何字节的数据时)If no timeout is specified explicitly, requests do not time out.
和 urllib 一样,多的介绍就不说了,直接上代码:
import requests
proxies = {
"http": "http://10.10.1.10:3128",
"https": "http://10.10.1.10:1080",
}
requests.get("https://www.geekdigging.com/", proxies=proxies)当然,直接运行这个示例可能不行,因为这个代理可能是无效的,可以自己找一些免费的代理进行测试。
而 Requests 除了支持 HTTP 代理,还支持 Socket 代理,因为这是一个可选的功能,在 Requests 的标准库中并未包含,所以在使用前需要先安装。
pip install requests[socks]安装好依赖以后,使用 SOCKS 代理和使用 HTTP 代理一样简单:
import requests
proxies_socket = {
'http': 'socks5://user:pass@host:port',
'https': 'socks5://user:pass@host:port'
}
requests.get("https://www.geekdigging.com/", proxies = proxies_socket)前面我们使用 urllib 处理 Cookies 的时候,写法比较复杂,而使用 Requests 会使证件事情变得非常简单,获取和设置 Cookies 只需一步就能完成。先看一个简单的示例:
import requests
r = requests.get("https://www.csdn.net")
print(type(r.cookies), r.cookies)
for key, value in r.cookies.items():
print(key + '=' + value)结果如下:
<class 'requests.cookies.RequestsCookieJar'> <RequestsCookieJar[<Cookie dc_session_id=10_1575798031732.659641 for .csdn.net/>, <Cookie uuid_tt_dd=10_19615575150-1575798031732-646184 for .csdn.net/>, <Cookie acw_tc=2760827715757980317314369e26895215355a996a74e112d9936f512dacd1 for www.csdn.net/>]>
dc_session_id=10_1575798031732.659641
uuid_tt_dd=10_19615575150-1575798031732-646184
acw_tc=2760827715757980317314369e26895215355a996a74e112d9936f512dacd1在 Requests 中我们使用 cookies 属性就可以直接得到 Cookies 。通过打印我们可以发现它的类型是 requests.cookies.RequestsCookieJar ,然后用 items() 方法将其转化为元组组成的列表,遍历输出每一个 Cookie 的名称和值,实现 Cookie 的遍历解析。
因为知乎是需要登录才能访问的,我们选址知乎作为测试的站点,首先直接访问知乎,看下返回的状态码。
import requests
r = requests.get('https://www.zhihu.com')
print(r.status_code)结果如下:
400状态码 400 的含义是请求无效(Bad request)。
我们打开浏览器,登录知乎,打开 F12 开发者模式,看下我们登录后的 Cookies 是什么。
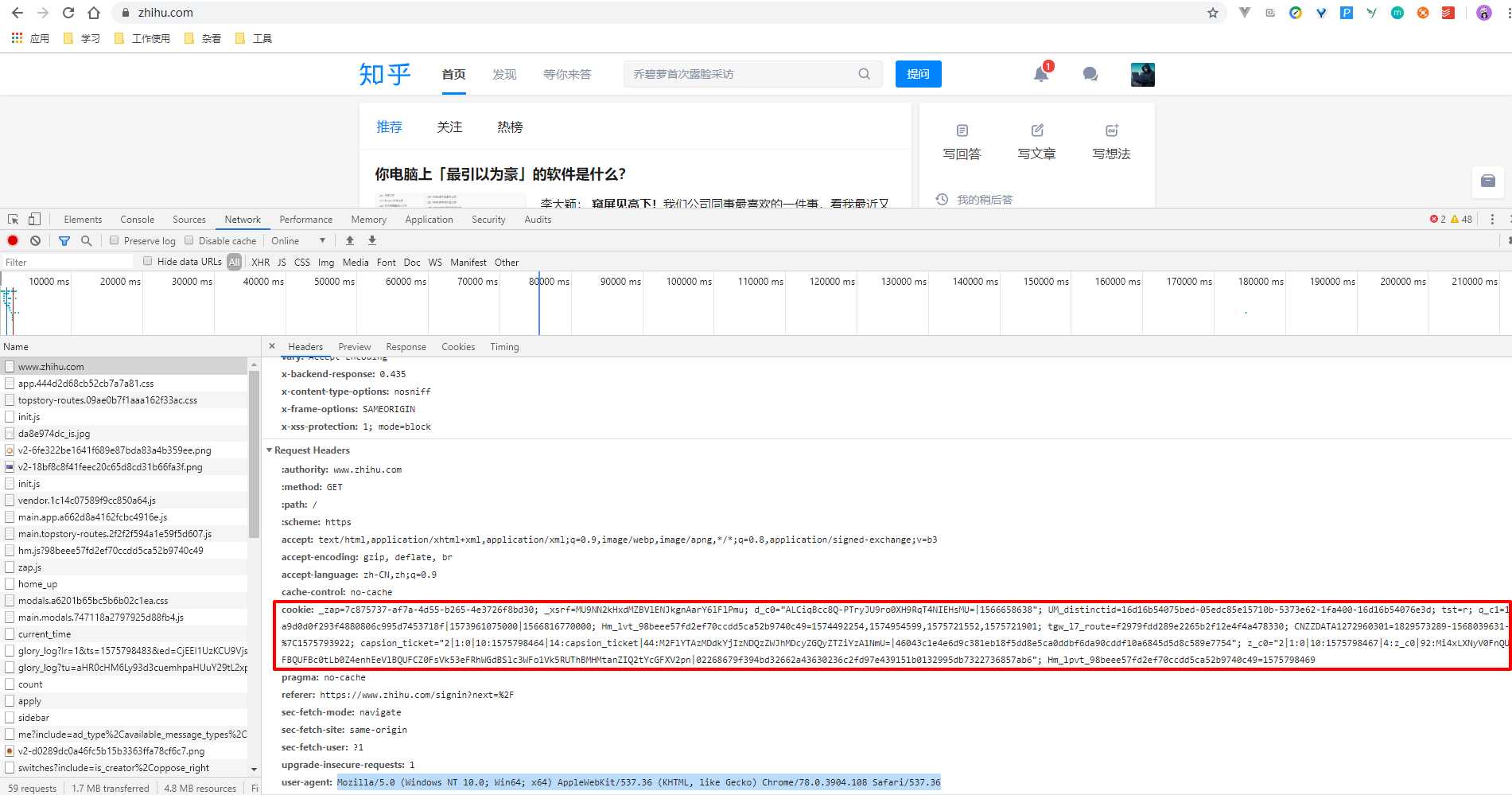
我们将这段内容 copy 下来,加到访问头中:
import requests
headers = {
'cookie': '_zap=7c875737-af7a-4d55-b265-4e3726f8bd30; _xsrf=MU9NN2kHxdMZBVlENJkgnAarY6lFlPmu; d_c0="ALCiqBcc8Q-PTryJU9ro0XH9RqT4NIEHsMU=|1566658638"; UM_distinctid=16d16b54075bed-05edc85e15710b-5373e62-1fa400-16d16b54076e3d; tst=r; q_c1=1a9d0d0f293f4880806c995d7453718f|1573961075000|1566816770000; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1574492254,1574954599,1575721552,1575721901; tgw_l7_route=f2979fdd289e2265b2f12e4f4a478330; CNZZDATA1272960301=1829573289-1568039631-%7C1575793922; capsion_ticket="2|1:0|10:1575798464|14:capsion_ticket|44:M2FlYTAzMDdkYjIzNDQzZWJhMDcyZGQyZTZiYzA1NmU=|46043c1e4e6d9c381eb18f5dd8e5ca0ddbf6da90cddf10a6845d5d8c589e7754"; z_c0="2|1:0|10:1575798467|4:z_c0|92:Mi4xLXNyV0FnQUFBQUFBc0tLb0Z4enhEeVlBQUFCZ0FsVk53eFRhWGdBSlc3WFo1Vk5RUThBMHMtanZIQ2tYcGFXV2pn|02268679f394bd32662a43630236c2fd97e439151b0132995db7322736857ab6"; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1575798469',
'host': 'www.zhihu.com',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
r = requests.get('https://www.zhihu.com', headers = headers)
print(r.text)执行结果如下:

结果太长了,小编就直接截个图。
有一点需要注意的是,这里的请求头增加了 UA 和 host ,不然也是无法访问的。
当然除了直接贴这么一串字符串,也是可以通过构造 cookies 的参数来设置 cookies ,这样需要构建一个 RequestsCookieJar 对象,步骤相对会复杂一点,结果是一样的。
# 构建 RequestsCookieJar 对象
cookies = '_zap=7c875737-af7a-4d55-b265-4e3726f8bd30; _xsrf=MU9NN2kHxdMZBVlENJkgnAarY6lFlPmu; d_c0="ALCiqBcc8Q-PTryJU9ro0XH9RqT4NIEHsMU=|1566658638"; UM_distinctid=16d16b54075bed-05edc85e15710b-5373e62-1fa400-16d16b54076e3d; tst=r; q_c1=1a9d0d0f293f4880806c995d7453718f|1573961075000|1566816770000; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1574492254,1574954599,1575721552,1575721901; tgw_l7_route=f2979fdd289e2265b2f12e4f4a478330; CNZZDATA1272960301=1829573289-1568039631-%7C1575793922; capsion_ticket="2|1:0|10:1575798464|14:capsion_ticket|44:M2FlYTAzMDdkYjIzNDQzZWJhMDcyZGQyZTZiYzA1NmU=|46043c1e4e6d9c381eb18f5dd8e5ca0ddbf6da90cddf10a6845d5d8c589e7754"; z_c0="2|1:0|10:1575798467|4:z_c0|92:Mi4xLXNyV0FnQUFBQUFBc0tLb0Z4enhEeVlBQUFCZ0FsVk53eFRhWGdBSlc3WFo1Vk5RUThBMHMtanZIQ2tYcGFXV2pn|02268679f394bd32662a43630236c2fd97e439151b0132995db7322736857ab6"; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1575798469'
jar = requests.cookies.RequestsCookieJar()
for cookie in cookies.split(';'):
key, value = cookie.split('=', 1)
jar.set(key, value)
headers_request = {
'host': 'www.zhihu.com',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
r = requests.get('https://www.zhihu.com', cookies = jar, headers = headers)
print(r.text)结果是可以访问成功的,小编这里就不贴了。
简单讲一下实现思路,将上面复制下来的 cookies 使用 split() 进行切割,然后使用 set() 方法将 key 和 value 赋值到 RequestsCookieJar 这个对象中,然后在访问知乎的时候将 RequestsCookieJar 赋值给 cookies 参数即可。需要注意的是这里的 header 参数不能少,只是原来 header 里面的 cookies 无需再设置了。
接下来这一个是大招,这个功能在 urllib 中是没有的。
先想像一个场景,我们在爬取一个网站的数据,其中有一部分需要使用 GET 请求,有一部分需要使用 POST 请求。但是我们在程序中写一个 get() 再写一个 post() ,实际上是两个不同的会话。
可能有的同学要说了,老师,我们前面讲的会话维持是通过 Cookies 来做的,可以在每次请求的时候添加上 Cookies 。
没问题,这样确实是可以的,但是这么干有些麻烦。 Requests 为我们提供了更加简洁高效的方法—— Session 。
我们还是通过前面介绍过的 https://httpbin.org/ 来进行演示,我们可以通过访问链接:https://httpbin.org/cookies/set/number/123456789 来设置一个 Cookies ,名称叫做 number ,内容是 123456789 。
首先看直接使用 Requests 的示例:
import requests
requests.get('https://httpbin.org/cookies/set/number/123456789')
r = requests.get('https://httpbin.org/cookies')
print(r.text)结果如下:
{
"cookies": {}
}我们直接调用两次 get() 方法,并没有在第二次调用的时候获得 Cookies 。接下来我们换 Session 再看一下:
import requests
s = requests.Session()
s.get('https://httpbin.org/cookies/set/number/123456789')
r = s.get('https://httpbin.org/cookies')
print(r.text)结果如下:
{
"cookies": {
"number": "123456789"
}
}显而易见,我们成功获取到了之前设置的 Cookies 。
所以,利用 Session 可以做到模拟同一个会话而不用手动再去设置 Cookies,它在我们平时的使用中使用的极其广泛,因为它可以模拟在同一个浏览器中访问同一个站点的不同的页面,这在我们爬取很多需要登录的网页时,极大的方便了我们代码的书写。
本系列的所有代码小编都会放在代码管理仓库 Github 和 Gitee 上,方便大家取用。
小白学 Python 爬虫(18):Requests 进阶操作
标签:字符 老师 agent lock 利用 inf 数据 数据库 步骤
原文地址:https://www.cnblogs.com/babycomeon/p/12042023.html