标签:速度 play windows环境 releases pow 安装过程 pip 自动安装 ntc
之前用爬虫抓点数据的时候基本上就是urllib3+BeautifulSoup4,后来又加入requests,大部分情况就够用了。但是最近心血来潮想学一下Scrapy,于是找了本书——《精通Python爬虫框架Scrapy》。内容算是比较可以的,但是按书中附录搭建环境着实折腾了一点时间,于是想把碰到的问题总结一下,让大家也少走点弯路。
进入正题之前,有几点要说明一下:
言归正传,开始吧。
一、安装Scrapy
我一般用pip安装各种库,只有一点值得注意一下,就是从pypi.org下载实在是一言难尽,于是:
pip install scrapy -i https://pypi.douban.com/simple
二、安装Vagrant
Vagrant Windows版32位下载地址,64位下载地址。安装就不多说了。
三、安装Docker Toolbox
关于这个书里介绍得比较简单,详细的内容需要自行到https://www.docker.com/docker-toolbox去研究。当然Docker的网站也让我想吐槽一下,看半天也不知道下载入口在哪里,WTF!
docker-toolbox下载地址
我查了很多网上一些资料,有些说还要安装VirtualBox、Git等,但是实际上不需要,安装完Docker-toolbox之后会自动安装。

四、安装PowerShell 3.0
因为我用的是Windows 7,在执行后面的vagrant up命令时候提示了一个错误,索性还是装了。
要注意的是安装时需要启动Windows Update服务。下载地址
五、克隆scrapy示例项目
直接到github去下载就行了,书中有链接,或者
git clone https://github.com/scalingexcellence/scrapybook.git
六、开始配置
cd scrapybook-master
启动之前,我碰到了执行vagrant up时总会提示错误的问题,最终解决办法就是需要手动启动docker:
docker-start.cmd
接着就是最扯淡的启动过程了。先创建box:
vagrant box add lookfwd/scrapybook https://vagrantcloud.com/lookfwd/boxes/scrapybook/versions/1.0.0/providers/virtualbox.box
注意:
vagrant box add lookfwd/scrapybook -f 你的保存路径\virtualbox.box #注意改路径
最后就是:
vagrant up --no-parallel
需要花几分钟时间来执行完,可惜我又碰到一个问题(VBOX_E_FILE_ERROR):
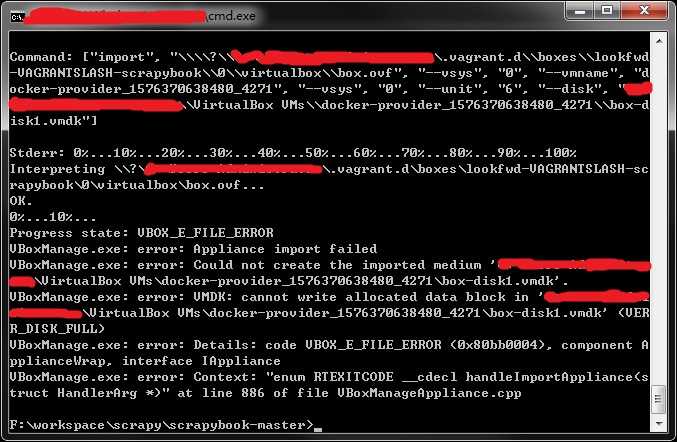
注意到其中有个(VERR_DISK_FULL),实际上就是我的磁盘满了,F*CK!默认虚拟机全放了C盘,好吧,都这个时候了我也不想再折腾了,果断清理系统盘。重新执行!测试!OK!
七、总结一下
Learning Scrapy:《精通Python爬虫框架Scrapy》Windows环境搭建
标签:速度 play windows环境 releases pow 安装过程 pip 自动安装 ntc
原文地址:https://www.cnblogs.com/cbdeng/p/12045168.html