标签:man mysql 分类 支持 压力 系统 复杂 返回 情况下
数据库优化出现的原因
数据库部分基于初始参数的优化(不多,具体有用到再说)
数据库sql优化的具体实例
数据库缓存,我的理解就是,对于查询过一次的数据,在再次遇到相同查询条件的时候,数据库如果开启了缓存,数据库会查询缓存,看看之前是否执行过相同条件的语句;如果一条sql语句所关联的表在这段时间期间:没有进行过表结构的改动,没有进行过数据的增添和改,查询就会命中缓存,更快的返回数据;
缓存的失效是十分频繁的,只要某个表的某一条数据进行更新,该表的所有缓存都会失效,而且如果开启列缓存,又频繁的更新缓存,肯定会给数据库带来更大的压力,所以,缓存使用要十分的谨慎:
缓存一般用在“静态表”上,即很长时间都不会做数据的改变,但是又会经常进行查询的表上,例如系统配置表、字典属性表;
对于有的缓存需求的数据库,可以将数据库的query_cache_type 参数设置成DEMAND,这样默认的sql语句都不适用缓存,对于需要使用缓存的语句:
-- 查询数据时候使用缓存
select SQL_CACHE * from T where ID=10;mysql参数修改命令,修改配置文件:
#linux 下
vi /etc/my.cnf
#修改参数为2 0,1,2,分别代表了off、on、demand。
query_cache_type =2更多数据库缓存内容参考:http://blog.itpub.net/15498/viewspace-2640129/
MySQL8.0版本默认删除了整块缓存的功能
分库分表:
优化条件:单表优化总条数:200w+
创建表:
使用limit直接分页第200w条后的20条数据:
select * from issue where occur_org_code like '1.1.%' limit 2000000,20; 分页前面的数据是很快的,但是越到后面的记录会越慢,为了体现优化结果,中间使用了like,occur_org_code为已经创建索引的字段,下面是执行的结果:
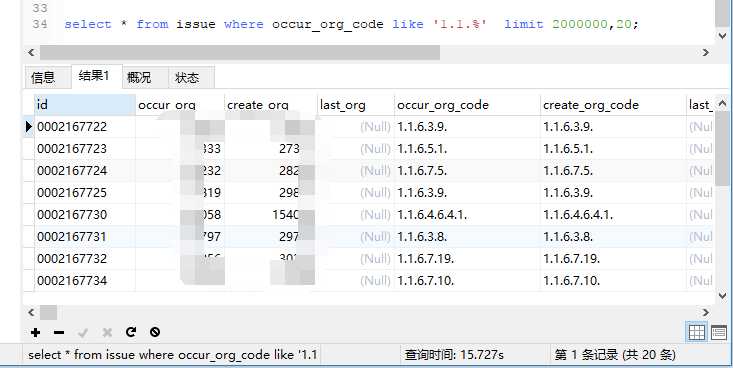
执行时间为15s多;查询中是使用了索引的:

覆盖索引:主键索引,叶子节点存储的是具体的详细数据,非主键索引,叶子节点存储的是主键,所以使用非主键索引,会在查询到id后再到主键索引上去查询详细的数据,这个过程称为回表,例如:select id from table where t >400;称为覆盖索引;
采用覆盖索引语句:
select id from issue where occur_org_code like '1.1.%' limit 1000000,20;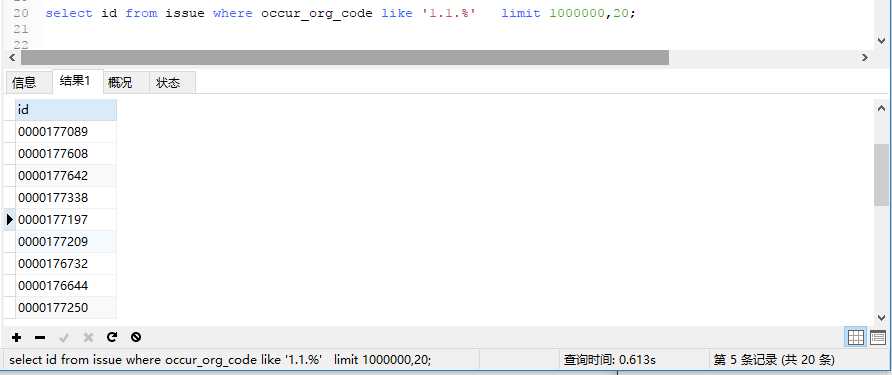
可以看到,是非常快的,所以分页sql如下:
select * from issue where id in(select id from issue where occur_org_code like '1.1.%' limit 1000000,20);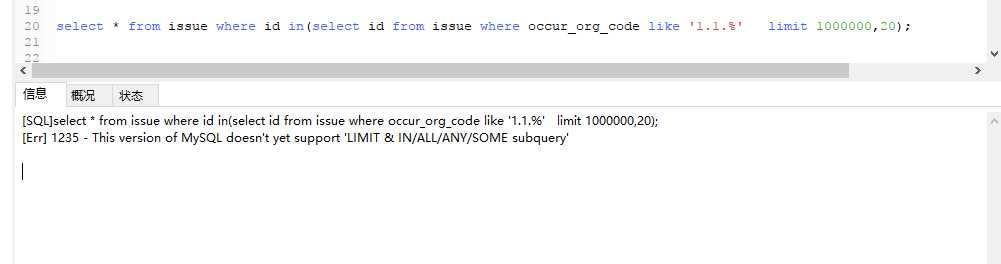
然而这样写是错的,在高版mysql中不支持在子查询使用limit
两种方法:
使用join
select * from issue i join (select id as bid from issue limit 1000000,20 )as b on i.id = b.bid;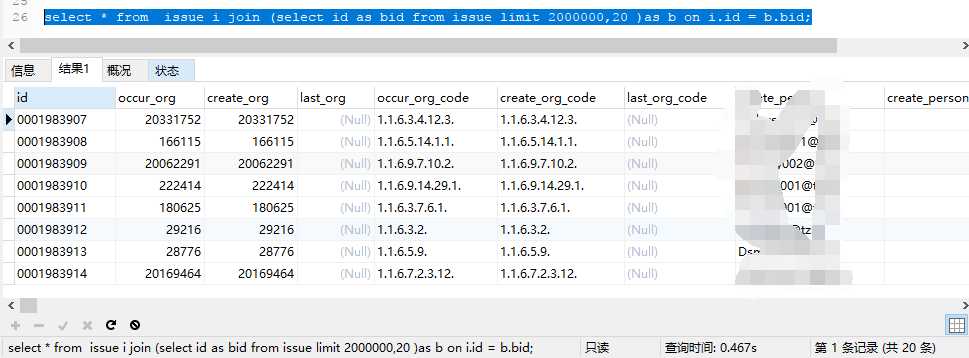
快了很多;在添加一条子查询
select * from issue where id in (select t.id from (select id from issue limit 2000000,20)as t) 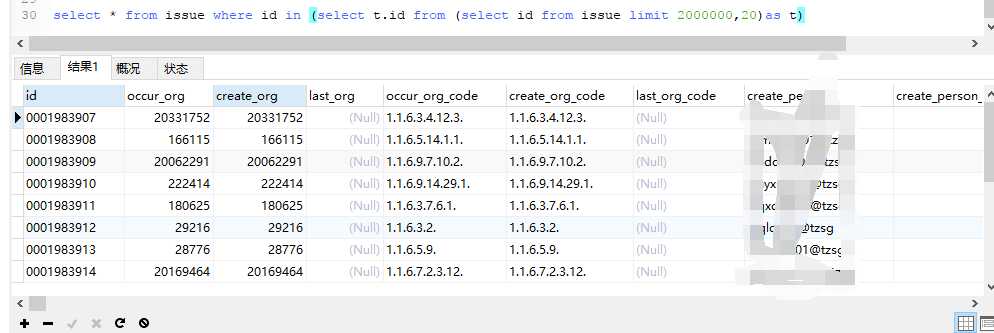
**这个明显没有join语句快弃用掉;**先说一下具体思路:将datetime转换为秒值新建一个字段存储入到表记录当中,根据sql建立组合索引,比较两种情况下sql的时间和效率;
测试结果又一定的差异不大,可以查看下面文章
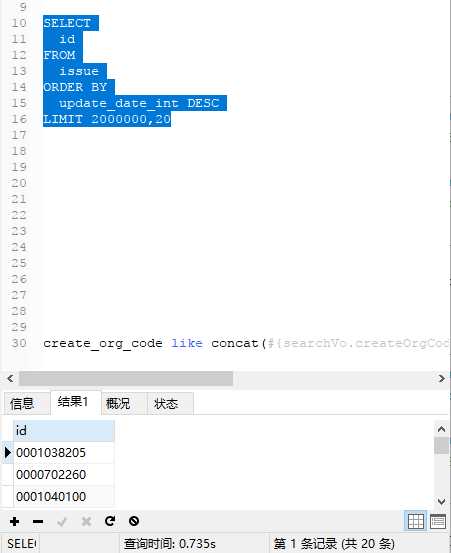
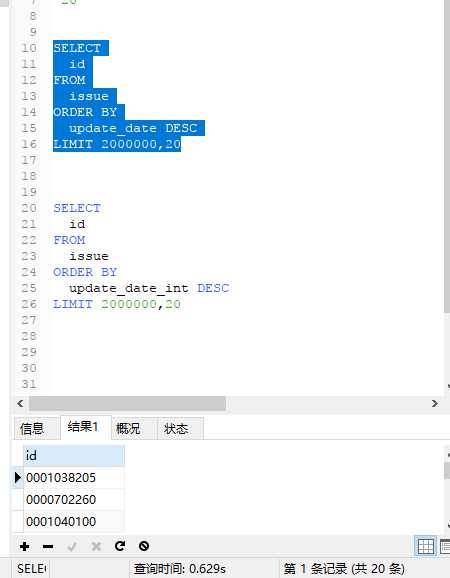
执行多次发现datetime反而更快https://blog.csdn.net/u011820505/article/details/79756652
先到这里,join优化,范围值优化,后面再测试
标签:man mysql 分类 支持 压力 系统 复杂 返回 情况下
原文地址:https://www.cnblogs.com/liweiweicode/p/12045919.html