标签:位置 组成 计算机管理 优化 形式 大于 管理 除了 区别
说起Mysql就离不开SQL优化,说起优化就离不开索引,那么什么是索引?为什么加了索引就可以快?那接下来我们就一起来探讨一下索引相关的知识!【对这块数据结构了解的同学建议跳过本节】说起二叉树,我们都知道每个结点最多只能有两个子结点,例如: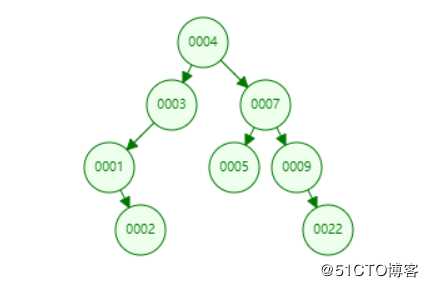
可以发现二叉树很有规律,左子结点小于当前结点,右子结点大于当前结点。那这样不是查询起来很方便呢?二叉树的性质决定了它的时间复杂度为 Olog(n),当然,二叉树的时间复杂度与它的插入顺序有着,如果按升序或降序的方式插入数据,那么它的二叉树的高度h就与结点个数相等了,此时复杂度就提高到了O(n)。
假如,数据库使用二叉树来做索引,此时需要插入1000条数据,我们来计算一下这树的高度。(深度为k的二叉树最少有k个结点,最多有2^k-1个结点)
2^10-1 ≈ 1000 此时树的高度约为10
最差的情况,树的高度为1000树的高度决定了查询的效率,而二叉树又会存在高度10~1000这么大的差距,很明显它已经不适合做我们的索引了!
前面把问题摆出来了,二叉树的高度很不稳定,那我们能不能把高度稳定一下呢?这就是平衡树,它会根据插入的情况,动态的调整二叉树的高度(左右子树的高度最多差1),比如:我们插入从10,9,8,,,1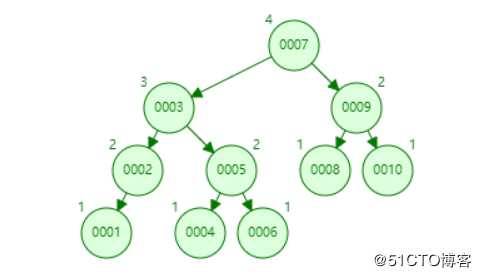
看,我没有骗你吧,它会根据插入的情况调整树的高度,具体怎么调整的,我只简单说明一下吧,毕竟不是本文的重点。
平衡树的调整分四种情况:
LL、LR、RL、RR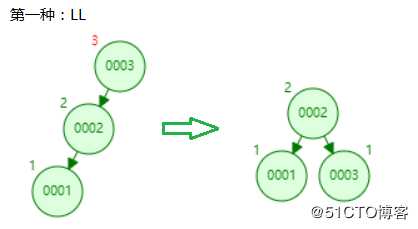
这种情况很好理解
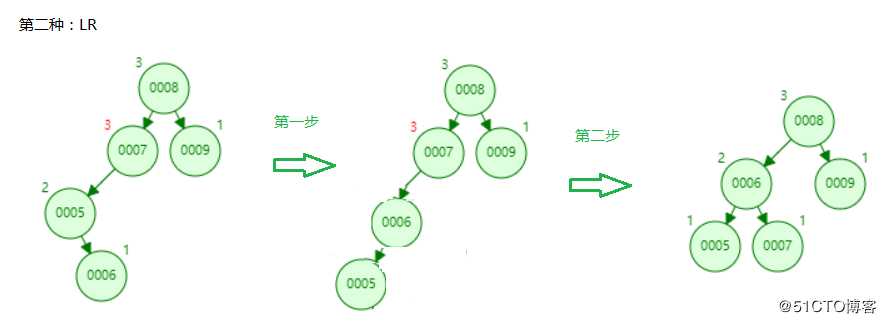
这种情况就是,先将5与6结点左旋转,然后转成了LL型,再右旋转。
好了,另外两种就不说了,和这两种的旋转方式正好相反而已。
咳咳,回到正题,现在好了,平衡树足以保证了树的平衡,那么使用它来做索引有没有 问题呢?
假如我们有100000 条记录,那么根据二叉树的性质,树的高度最低约为2^16,也就是查找一个元素需要查找16次,有同学可能说,嗯,查询16次我可以接受了,那么假如插入或删除数据呢?AVL树的最大缺点就是插入结点时,树需要频繁的旋转调整结点,所以平衡树也不太适合做索引。
前面说了平衡树对二叉树的要求,左右子树的高度最多差1,插入数据稍有不慎就会造成平衡树的转换操作,而转换又是非常耗时的一件事情。
而红黑树的出现就是为了避免平衡树的频繁转换结点操作。红黑树 并不追求 完全平衡 它只要求部分结点达到平衡,降低了对旋转的要求,从而提高了性能。先看下红黑树的定义吧!
* 每个结点要么是红的要么是黑的。
* 根结点是黑的。
* 每个叶结点(叶结点即指树尾端NIL指针或NULL结点)都是黑的。
* 如果一个结点是红的,那么它的两个儿子都是黑的。
* 对于任意结点而言,其到叶结点树尾端NIL指针的每条路径都包含相同数目的黑结点。 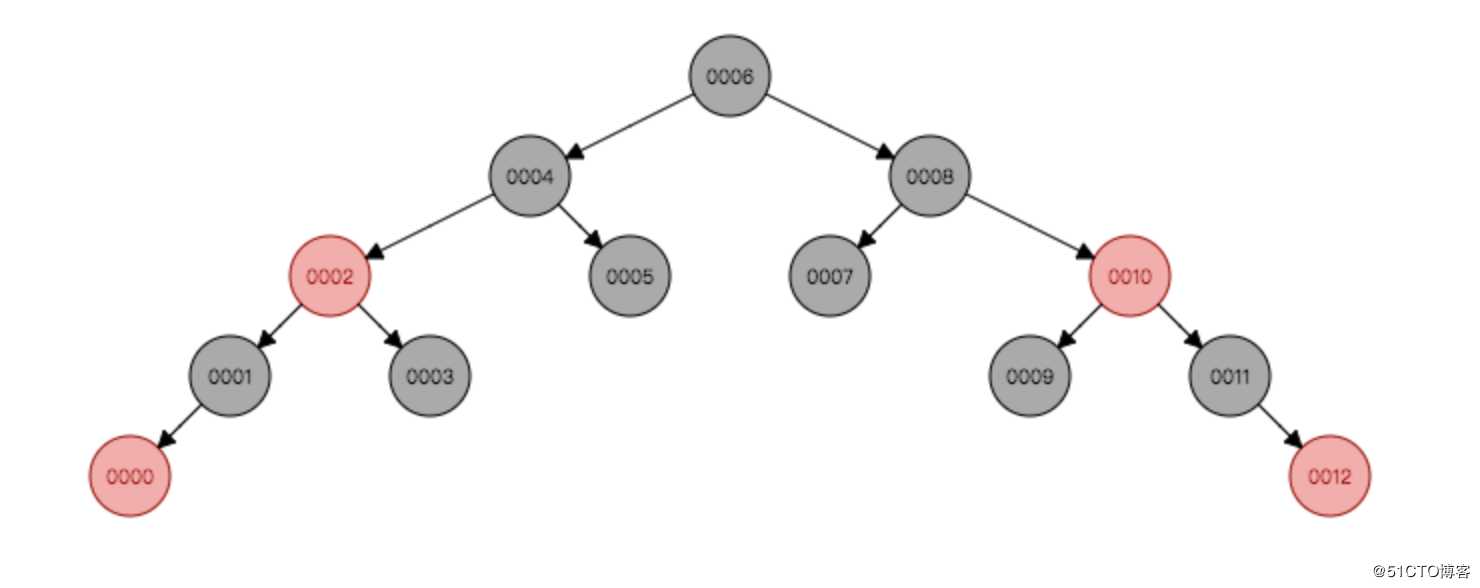
插入或删除元素时,也是需要维护红黑树结构的,之所以索引也不使用红黑树主要是二叉树保存大量结点的时候,会导致树的高度不断增加。比如1亿个节点,树的高度就会达到27层左右,而一般索引又是保存到磁盘中的,如果每次查询都需要一次IO的话,那也就是需要27次IO操作,而每次IO操作都是非常耗时的。
平衡树、红黑树都是二叉树,当二叉树保存大量元素的时候会导致树的高度不断增高,那可不可以使用多叉树呢?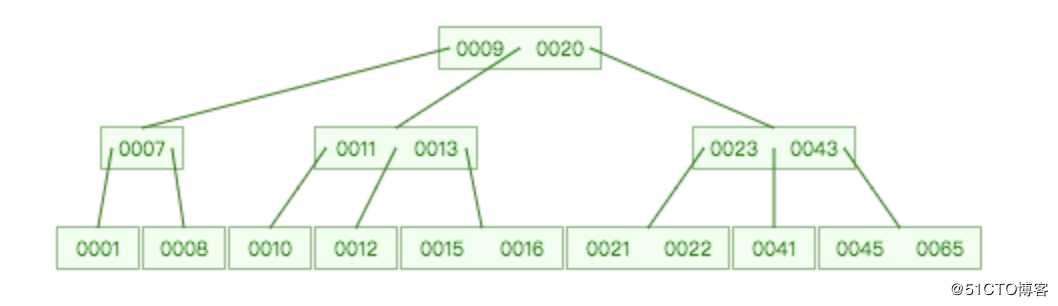
先来看下B树的定义:
1、B树的组成
关键字(可以理解为数据)
指向孩子节点的指针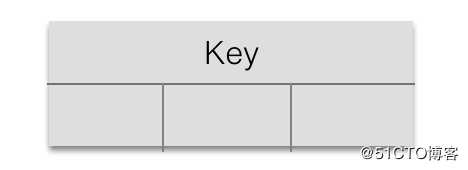
2、B树的性质:
* 若根结点不是终端结点,则至少有2棵子树
* 除根节点以外的所有非叶结点至少有 M/2 棵子树,至多有 M 个子树(关键字数为子树减一)
* 所有的叶子结点都位于同一层B+树与B树的区别主要在于:
* 节点的子树数和关键字数相同(B 树是关键字数比子树数少一)
* 节点的关键字表示的是子树中的最大数,在子树中同样含有这个数据
* 叶子节点包含了全部数据,同时符合左小右大的顺序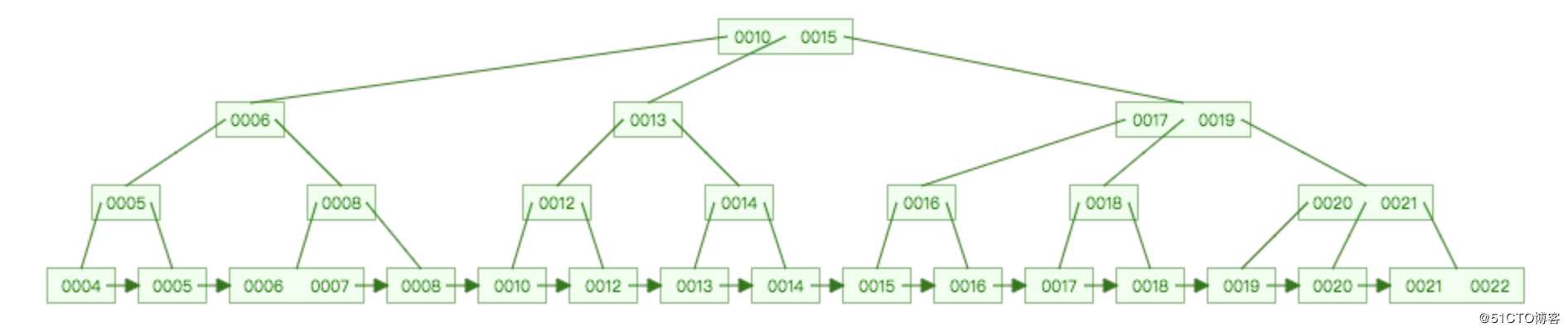
B+树相比B树的优点再于:层级更低,叶子结点形成链表,范围查询方便;
索引文件一般以文件的形式存在磁盘上面,索引检索操作需要磁盘的IO,但是磁盘顺序读取的效率很高,所以在读取的时候,磁盘往往不是按需读取,而且每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。由于磁盘顺序读取的效率很高,因此对于具有局部性的程序来说,预读可以提高IO效率。预读的长度一般为页的整数倍(页是计算机管理存储器的逻辑块,操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页,大小通常是4K)主存和磁盘以页为单位交换数据。当程序要读取的数据不在主存中时,会触发一个缺页异常,此时系统会向磁盘发出读盘信号,磁盘会找到数据的起始位置并向后连续读取一页或几页载入内存中,然后异常返回,程序继续运行
Innodb中使用是B+树作为索引,比如下图中的主索引: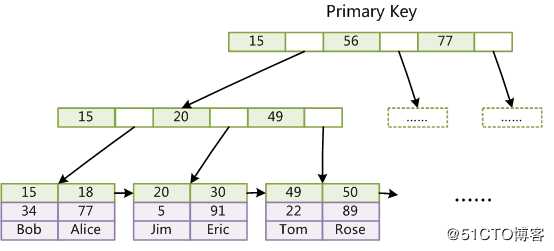
叶子结点包含了所以的结点,除了叶子结点之外,其它结点不包含值,而叶子结点包含具体的值二级索引
Innodb中的二级索引,也是一棵B+树,只是它的叶子结点指向的是主索引中的主键值,然后再去主索引中查找具体的值;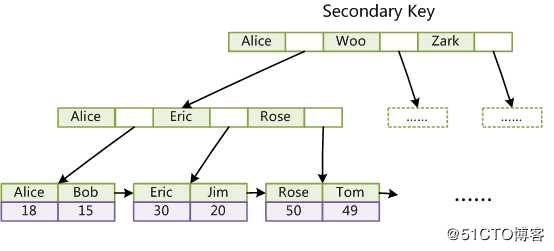
MyISAM引擎使用B+树作索引时,结构与Innodb大致相同,只是它叶子结点存放的不是具体的记录值,而是记录的地址。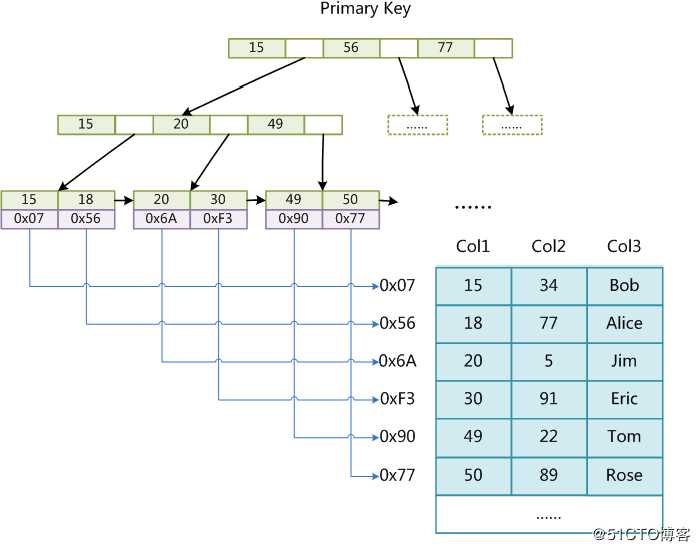
二级索引
一级索引中,MyISAM的索引文件仅仅保存数据记录的地址,而二级索引在结构上没有任何区别,二级索引也是直接指向记录的地址。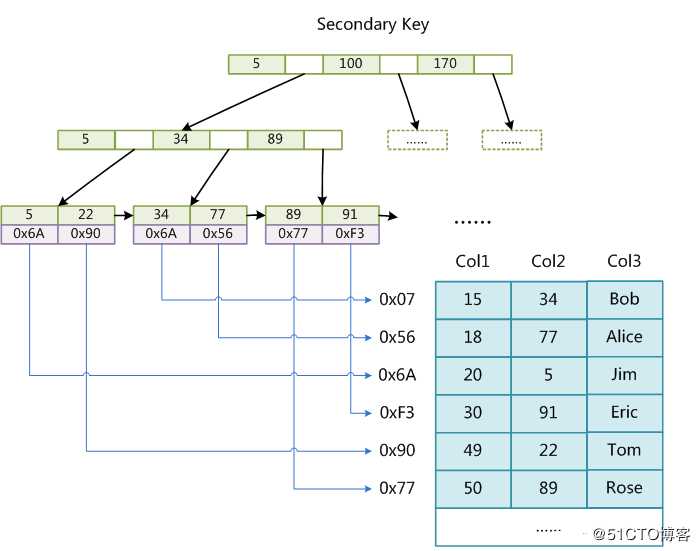
标签:位置 组成 计算机管理 优化 形式 大于 管理 除了 区别
原文地址:https://blog.51cto.com/13733462/2458713