标签:har 循环 get concat div copyright 返回结果 res ttext
set @rn=0; SELECT @rn:=@rn+1 序号, ryxm `人员姓名`, cylb `成员类别`, gzdw `工作单位`, zc `职称`, GROUP_CONCAT(zzqmc) AS `著作权名称`--多字段合并到一起 FROM (SELECT VCA.ryxm ryxm, VCA.cylb cylb, VCA.gzdw gzdw, VCA.zc zc, VC.zzqmc zzqmc FROM V_COPYRIGHT AS VC ,V_COPYRIGHT_AUTHOR AS VCA WHERE VC.id=VCA.zzqid)d GROUP BY ryxm,cylb,gzdw,zc
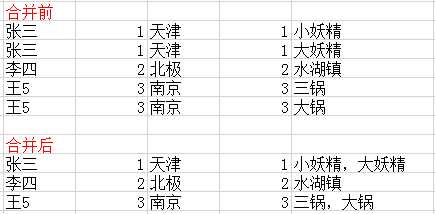
统计合并列中的个数
DROP FUNCTION GetTextCount // /********** -- 获取字符串中有几个部分. **********/ CREATE FUNCTION GetTextCount(pSourceText VARCHAR(255), pDivChar CHAR(1)) RETURNS TINYINT BEGIN -- 预期结果. DECLARE vResult TINYINT; -- 当前逗号的位置. DECLARE vIndex INT; -- 前一个逗号的位置. DECLARE vPrevIndex INT; -- 结果的初始值. SET vResult = 1; -- 查询第一个 逗号的位置. SET vIndex = INSTR(pSourceText, pDivChar); IF vIndex = 0 THEN -- 参数中没有逗号,直接返回. RETURN vResult; END IF; -- 初始化情况,前一个逗号不存在. SET vPrevIndex = 0; -- 循环处理。 WHILE vIndex > 0 DO -- 结果递增. SET vResult = vResult + 1; -- 前一个逗号的位置 = 当前逗号的位置 SET vPrevIndex = vIndex; -- 查询下一个逗号的位置. SET vIndex = LOCATE(pDivChar, pSourceText, vPrevIndex + 1); END WHILE; -- 返回结果. RETURN vResult; END;
-- 查询结果.
SELECT
GetTextCount(zzqmc,‘,‘)
FROM perso
/********** 显示合并列的内容及个数**********/
/********** -- 获取字符串中具体某一个部分的数据. **********/ CREATE FUNCTION GetTextValue(pSourceText VARCHAR(255), pDivChar CHAR(1), pIndex TINYINT) RETURNS VARCHAR(255) BEGIN -- 预期结果. DECLARE vResult VARCHAR(255); IF pIndex = 1 THEN SELECT SUBSTRING_INDEX(pSourceText, pDivChar, 1) INTO vResult; ELSE SELECT REPLACE( SUBSTRING_INDEX(pSourceText, pDivChar, pIndex), CONCAT(SUBSTRING_INDEX(pSourceText, pDivChar, pIndex - 1) , pDivChar), ‘‘) INTO vResult; END IF; -- 返回. RETURN vResult; END; SELECT GetTextValue(t.name, ‘,‘, MaxNum.No) AS `名称`, COUNT(*) AS `个数` FROM person t, (SELECT 1 No UNION ALL SELECT 2 No UNION ALL SELECT 3 No UNION ALL SELECT 4 No UNION ALL SELECT 5 No ) MaxNum WHERE GetTextCount(t.name, ‘,‘) >= MaxNum.No GROUP BY GetTextValue(t.name, ‘,‘, MaxNum.No);
标签:har 循环 get concat div copyright 返回结果 res ttext
原文地址:https://www.cnblogs.com/mergy/p/12054059.html