标签:代码 response element 了解 block nts item 运行 col
search2015_cpitem

第一步:先了解需要用到的工具
1. requests 库: 用来获取网页内容
2. BeautifulSoup 库: 用来解析网页,提取想要的内容
3. selenium 库 :Selenium测试直接运行在浏览器中,就像真正的用户在操作一样
第二步:代码解释
用美食杰网站为例,第一步是获取页面内所有的网页连接
def each_page(html):
# 传递进去网页信息,然后获取beautifulsoup解析对象。 soup = BeautifulSoup(html, ‘lxml‘)
# 在解析内容中寻找类为search2015_cpitem的字段 a = soup.find_all(class_=‘search2015_cpitem‘) for li in a: url.append(li.find(‘a‘).get(‘href‘))
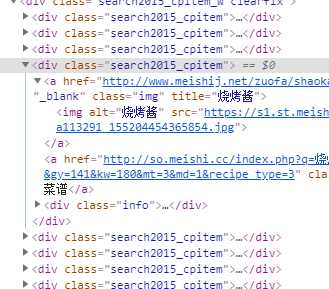
在打开检查可以看到,源码里面类为 search2015_cpitem 的标签很多,那是因为界面内有很多菜谱,所以使用 find_all()获取,然后对获得的内容进行循环先获取标签 <a/> 然后获取href 属性,就可以得到菜谱链接。
第二步:进行网页翻页

有图可以得知,菜谱网站大部分都不是一页,所以要有翻页自动去获取所有的url。首先要查询网页的下一页信息,获取准确的按钮信息,才可以成功翻页。

有图可以知道源码内有下一页关键字,可以根据这个关键字去进行翻页。#代码如下:
def next_page(): for i in fenlei:
browser = webdriver.Chrome() browser.get(i) while True: if ‘下一页‘ in browser.page_source: html = browser.page_source each_page(html) a = browser.find_element_by_link_text(‘下一页‘) a.click() continue else: # return urls html = browser.page_source each_page(html) browser.close() break return url
代码的主要内容就是调用each_page函数去获取所有页面的url。
当然,最后不单单只是爬取url,还要进入url内去获取相关的数据内容。
def get_message(urls): # tongjititle 菜谱名称 # tongjind 菜谱难度 # tongjiprsj 菜谱烹饪时间 # 用料 # 做法 s=‘‘ l=‘‘ shicaizhu=‘‘ shicaifu=‘‘ headers = {‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0‘} response = requests.get(urls, headers=headers) soup = BeautifulSoup(response.text, ‘html.parser‘) # 获取菜谱的名称 if soup.find(id=‘tongji_title‘)==None: tongjititle=‘‘ else: tongjititle=soup.find(id=‘tongji_title‘).string # 获取难度 if soup.find(id=‘tongji_nd‘)==None: tongjind=‘‘ else: tongjind = soup.find(id=‘tongji_nd‘).string # 获取烹饪口味 if soup.find(id=‘tongji_kw‘)==None: tongjikw=‘‘ else: tongjikw = soup.find(id=‘tongji_kw‘).string # 获取烹饪时间 if soup.find(‘li‘,class_=‘w270 bb0 br0‘)==None: tongjiprsj=None else: tongjiprsj=soup.find(‘li‘,class_=‘w270 bb0 br0‘).contents[1].text # print(tongjiprsj) # 获取烹饪的食材 # 获取辅料 for fuliao in soup.find_all(class_=‘yl fuliao clearfix‘): shicaifu=fuliao.find(class_=‘clearfix‘) for zhuliao in soup.find_all(class_=‘yl zl clearfix‘): shicaizhu=zhuliao.find(class_=‘clearfix‘) # 获取烹饪步骤 for ls in soup.find_all(class_=‘content clearfix‘): l=l+ls.contents[1].string+ls.contents[3].text l=l.replace(‘\n‘,‘‘) if shicaifu==‘‘: if shicaizhu!=‘‘: s=shicaizhu.text.replace(‘\n‘,‘‘) elif shicaizhu==‘‘: s=‘没有食材‘ else: s=shicaizhu.text.replace(‘\n‘,‘‘)+shicaifu.text.replace(‘\n‘,‘‘) return tongjititle,tongjind,tongjikw,tongjiprsj, s, l
代码主要是获取单个菜谱的相关信息。
主要功能只有这三个模块。大家可以试着尝试去实现,当然如果有好的想法的话

交流qq群:515458373
项目地址: https://github.com/blearch/-/tree/master/%E7%BE%8E%E9%A3%9F%E6%9D%B0
标签:代码 response element 了解 block nts item 运行 col
原文地址:https://www.cnblogs.com/qiujichu/p/12056408.html