标签:解释器 指示 and pen 加载 检查 font overflow lex
本章节主要讲解模块和包的概念,模块是用来组织Python代码的方法,而包则是用来组织模块的。
模块支持从逻辑上组织Python代码,当代码量很大的时候,我们最好把代码分成一些有组织的代码段,前提是保证它们之间的彼此交互,这些代码段之间有一定的联系,彼此是共享的,Python允许“调入”一个模块,允许其他模块的属性来利用之前的工作成果,实现代码重用。这个把其他模块中属性附加到你的模块中的操作叫导入(import),那些自我包含并且有组织的代码片段就是模块(module)。
如果说模块是按照逻辑来组织Python代码的,那么文件便是物理层上组织模块的方法。一个文件被看作一个独立的模块,一个模块也可看做是一个文件。模块的文件名就是模块的名称加上扩展名.py。
从基本概念来说,一个名称空间就是一个从名称到对象的关系映射集合。给定一个模块名之后,只可能有一个模块被导入到Python解释器中,所以不同的模块间不会出现名称交叉现象。所以每个模块都有它自己的唯一的名称空间。如果在自定义的模块mymodule里创建了一个atoi()函数,那么它的名字应该是mymodule.atoi()。所以即使属性之间有名称冲突,但它们的完整授权名称(fully qualified name)通过句点属性标识指定了各自的名称空间,防止了名称冲突的发生。
模块的导入需要一个叫做“路径搜索”的过程,即在文件系统“预定义区域”中查找mymodule.py文件。这些预定义区域是你的Python搜素路径的集合。路径搜索和搜索路径是不同的概念:前者是指查找某个文件的操作,后者是去查找一组目录。
默认搜索路径是在编译或者安装时指定的,可以有两种方法修改:一个是在环境变量中添加;另一个是在解释器启动之后也可以添加。解释器启动之后,也可以访问搜索路径,它会别保存在sys模块的sys.path变量中。
1 >>> sys.path 2 [‘‘, ‘/usr/lib64/python26.zip‘, ‘/usr/lib64/python2.6‘, ‘/usr/lib64/python2.6/plat-linux2‘, ‘/usr/lib64/python2.6/lib-tk‘, ‘/usr/lib64/python2.6/lib-old‘, ‘/usr/lib64/python2.6/lib-dynload‘, ‘/usr/lib64/python2.6/site-packages‘, ‘/usr/lib64/python2.6/site-packages/gst-0.10‘, ‘/usr/lib64/python2.6/site-packages/gtk-2.0‘, ‘/usr/lib64/python2.6/site-packages/webkit-1.0‘, ‘/usr/lib/python2.6/site-packages‘, ‘/usr/lib/python2.6/site-packages/setuptools-36.0.1-py2.6.egg‘]
>>> sys.path.append(‘/home/python‘)返回的是一个列表,可以使用列表的额append()方法添加搜索路径,这个方法将目录追加到搜索路径的尾部。
名称空间是名称(标识符)到对象的映射,向名称空间添加名称的操作过程涉及绑定标识符到指定对象的操作(以及给对象的引用计数加1)。改变一个名字的绑定叫重新绑定,删除一个名字叫做解除绑定。在执行期间有两个或三个活动的名称空间:局部名称空间、全局名称空间和内建名称空间。Python解释器首先加载内建名称空间,它由__builtins__模块中的名字构成,随后加载执行模块的全局名称空间,它会在模块开始执行后变成活动名称空间。
注:__builtins__模块包含内建名称空间中内建名字的集合。
1 >>> dir(__builtins__) 2 [‘ArithmeticError‘, ‘AssertionError‘, ‘AttributeError‘, ‘BaseException‘, ‘BufferError‘, ‘BytesWarning‘, ‘DeprecationWarning‘, ‘EOFError‘, ‘Ellipsis‘, ‘EnvironmentError‘, ‘Exception‘, ‘False‘, ‘FloatingPointError‘, ‘FutureWarning‘, ‘GeneratorExit‘, ‘IOError‘, ‘ImportError‘, ‘ImportWarning‘, ‘IndentationError‘, ‘IndexError‘, ‘KeyError‘, ‘KeyboardInterrupt‘, ‘LookupError‘, ‘MemoryError‘, ‘NameError‘, ‘None‘, ‘NotImplemented‘, ‘NotImplementedError‘, ‘OSError‘, ‘OverflowError‘, ‘PendingDeprecationWarning‘, ‘ReferenceError‘, ‘RuntimeError‘, ‘RuntimeWarning‘, ‘StandardError‘, ‘StopIteration‘, ‘SyntaxError‘, ‘SyntaxWarning‘, ‘SystemError‘, ‘SystemExit‘, ‘TabError‘, ‘True‘, ‘TypeError‘, ‘UnboundLocalError‘, ‘UnicodeDecodeError‘, ‘UnicodeEncodeError‘, ‘UnicodeError‘, ‘UnicodeTranslateError‘, ‘UnicodeWarning‘, ‘UserWarning‘, ‘ValueError‘, ‘Warning‘, ‘ZeroDivisionError‘, ‘_‘, ‘__debug__‘, ‘__doc__‘, ‘__import__‘, ‘__name__‘, ‘__package__‘, ‘abs‘, ‘all‘, ‘any‘, ‘apply‘, ‘basestring‘, ‘bin‘, ‘bool‘, ‘buffer‘, ‘bytearray‘, ‘bytes‘, ‘callable‘, ‘chr‘, ‘classmethod‘, ‘cmp‘, ‘coerce‘, ‘compile‘, ‘complex‘, ‘copyright‘, ‘credits‘, ‘delattr‘, ‘dict‘, ‘dir‘, ‘divmod‘, ‘enumerate‘, ‘eval‘, ‘execfile‘, ‘exit‘, ‘file‘, ‘filter‘, ‘float‘, ‘format‘, ‘frozenset‘, ‘getattr‘, ‘globals‘, ‘hasattr‘, ‘hash‘, ‘help‘, ‘hex‘, ‘id‘, ‘input‘, ‘int‘, ‘intern‘, ‘isinstance‘, ‘issubclass‘, ‘iter‘, ‘len‘, ‘license‘, ‘list‘, ‘locals‘, ‘long‘, ‘map‘, ‘max‘, ‘min‘, ‘next‘, ‘object‘, ‘oct‘, ‘open‘, ‘ord‘, ‘pow‘, ‘print‘, ‘property‘, ‘quit‘, ‘range‘, ‘raw_input‘, ‘reduce‘, ‘reload‘, ‘repr‘, ‘reversed‘, ‘round‘, ‘set‘, ‘setattr‘, ‘slice‘, ‘sorted‘, ‘staticmethod‘, ‘str‘, ‘sum‘, ‘super‘, ‘tuple‘, ‘type‘, ‘unichr‘, ‘unicode‘, ‘vars‘, ‘xrange‘, ‘zip‘]
1.3.1 名称空间与变量作用域比较
名称空间是纯粹意义上的名字和对象间的映射关系,而作用域还指出了从用户代码的哪些物理位置可以访问到这些名字。下图为名称空间和变量作用域之间的关系。
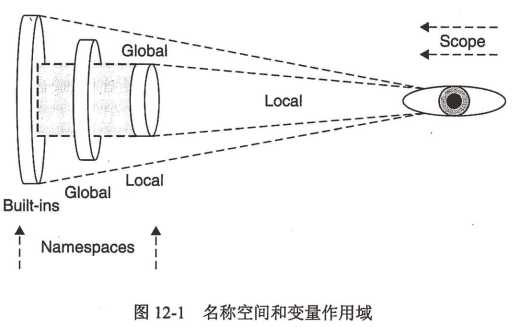
每个名称空间是一个自我包含的单元,但从作用域的角度来看,所有局部名称空间的名称都在局部作用范围内,局部范围以外的所有名称都在全局作用范围内。局部名称空间和作用域会随板书调用而不断变化,而全局名称空间是不变的。
访问一个属性时,解释器必须在三个名称空间中的一个找到它。首先从局部名称空间中查找,如果没有找到,解释器继续查找全局名称空间,如果没找到,将在内建名称空间中查找,如果也失败了,会返回NameError异常。
局部名称空间中找到的名字会隐藏全局或内建名称空间的对应对象。
1 >>> def foo(): 2 ... bar = 200 3 ... print ‘in foo(), bar is ‘, bar 4 ... 5 >>> bar = 100 6 >>> print ‘in __main__, bar is ‘, bar 7 in __main__, bar is 100 8 >>> foo() 9 in foo(), bar is 200
1.3.3 无限制的名称空间
Python可以在任何需要放置数据的地方获得一个名称空间,可以在任何时候给函数添加属性(使用句点属性标识)。
1 >>> class myClass(object): 2 ... pass 3 ... 4 >>> mc = myClass() 5 >>> mc.x = 100 6 >>> mc.y = 200 7 >>> mc.version = 0.1 8 >>> mc.completed = False
使用import语句导入模块,语法如下:
1 import module1 2 import module2 3 … 4 import module
也可以写在一行:
1 import module1[, module2[, …, moduleN]]
推荐所有的模块在Python模块的开头部分导入,而且最好按照这样的顺序:
使用from-import在你的模块里导入指定的模块属性,也就是把指定名称导入到当前作用域。语法如下:
1 from module import name1[, name2, [, …, nameN]]
从一个模块导入许多属性时,import行会越来越长,直到自动换行,而且需要使用一个\。不提倡使用from module import *语句,应该使用Python的标准分组机制(圆括号)来创建更合理的多行导入语句:
1 from module import (name1, name2, …, nameN)
有时候导入的模块或是模块属性名称已经在程序中使用了,或者不想使用导入的名字。一个普遍的解决方法是把模块赋值给一个变量:
1 >>> import longmodulename 2 >>> short = longmodulename 3 >>> del longmodulename
使用扩展的import,可以在导入的同时指定局部绑定名称。
1 import longmodulename as shortmodulename 2 from module import longname as shortname
加载模块会导致这个模块被“执行”,也就是导入模块的顶层代码将直接被执行。这通常包括设定全局变量以及类和函数的声明,如果有检查__name__的操作,那么它也会被执行。
一个模块只被加载一次,无论它被导入多少次。这可以阻止多重导入时代码被多次执行。
调用from-import可以把名字导入当前的名称空间中去,而不需要使用属性/句点属性标识来访问模块的标识符,例如,你需要访问模块module中的var名字是这样被导入的:
1 from module import var
我们使用单个var就可以访问到它自身。
只从模块导入名字的另一个副作用是那些名字会成为局部名称空间的一部分。这可能导致覆盖一个已经存在的具有相同名字的对象,而且对这些变量的改变只影响它的局部拷贝而不是导入模块的原始名称空间,也就是说,绑定只是局部的而不是整个名称空间。
1 # imptee.py 2 foo = ‘abc‘ 3 def show(): 4 print ‘foo from imptee:‘, foo 5 # impter.py 6 from imptee import foo, show 7 show() 8 foo = 123 9 print ‘foo from impter:‘, foo 10 show() 11 执行impter.py的结果 12 [root@localhost python]# python impter.py 13 foo from imptee: abc 14 foo from impter: 123 15 foo from imptee: abc 16 #修改impter.py如下: 17 import imptee 18 imptee.show() 19 imptee.foo = 123 20 print ‘foo from impter:‘, imptee.foo 21 imptee.show() 22 执行impter.py的结果: 23 [root@localhost python]# python impter.py 24 foo from imptee: abc 25 foo from impter: 123 26 foo from imptee: 123
1.6 模块内建函数
系统为模块提供了一些功能上的支持。
__import__()作为实际上导入模块的函数,import语句是调用__import__()函数完成的它的工作,语法如下:
1 __import__(module_name[, globals[, locals[, fromlist]]])
module_name变量是导入模块的名称,globals是包含当前全局符号表的名字的字典,locals是包含局部符号表的名字的字典,fromlist是一个使用from-import语句所导入符号的列表。
globals、locals和fromlist参数都是可选的,默认为globals()、locals()和[]。
调用import sys语句可以使用下面的语句完成:
1 >>> sys = __import__(‘sys‘)
globals()和locals()内建函数分别返回调用者全局和局部名称空间的字典。在一个函数内部,局部名称空间代表可以在函数执行时候定义的所有名字,locals()函数返回的就是包含这些名字的字典。globals()会返回函数可访问的全局名字。
在全局名称空间下,globals()和locals()返回相同的字典,因为这是局部名称空间就是全局空间。
1 def foo(): 2 print ‘calling foo()‘ 3 astring = ‘bar‘ 4 anint = 12 5 print "foo()‘s globals().keys()", globals().keys() 6 print "foo()‘s locals()", locals().keys() 7 8 print "__main__‘s globals():", globals().keys() 9 print "__main__‘s locals():", locals().keys() 10 foo() 11 [root@localhost python]# python import_test.py 12 __main__‘s globals(): [‘__builtins__‘, ‘__file__‘, ‘__package__‘, ‘__name__‘, ‘foo‘, ‘__doc__‘] 13 __main__‘s locals(): [‘__builtins__‘, ‘__file__‘, ‘__package__‘, ‘__name__‘, ‘foo‘, ‘__doc__‘] 14 calling foo() 15 foo()‘s globals().keys() [‘__builtins__‘, ‘__file__‘, ‘__package__‘, ‘__name__‘, ‘foo‘, ‘__doc__‘] 16 foo()‘s locals() [‘anint‘, ‘astring‘]
reload()内建函数可以重新导入一个已经导入的模块。语法如下:
1 reload(module)
module是你想要重新导入的模块,使用reload()的时候有一些标准,首先模块必须是全部导入(不是使用from-import),而且它必须被成功导入。另外reload()函数的参数必须是模块自身而不是包含模块名的字符串,也就是reload(sys)而不是reload(‘sys’)。
包是一个有层次的文件目录结构,它定义了一个由模块和子包组成的Python应用程序执行环境。主要用于解决以下问题:
假设包的例子有如下的目录结构:

Phone是最顶层的包,Voicedta等是它的子包。我们可以这样导入包:
1 import Phone.Mobile.Analog 2 Phone.Mobile.Analog.dial()
此外,我们还可以引用更多的子包:
1 form Phone.Mobile import Analog 2 Analog.dial(‘555-1212’)
事实上,可以一直沿子包的树状结构导入:
1 from Phone.Mobile.Analog import dial 2 dial(‘555-1212’)
包同样支持from-import all语句。
1 from package.module import *
在导入子包和真正的标准库模块发生冲突时,包模块会把名字相同的标准库模块隐藏掉,它首先在包内执行相对导入,隐藏掉标准库模块。从Python2.7开始,绝对导入功能成为了默认功能。import语句总是绝对导入的。
相对导入只适用于from-import语句,语法的第一部分是一个句点,指示一个相对的导入操作。之后的其他附加据点代表当前from起始查找位置后的一个级别。
例如上面的包结构中:
1 from Phone.Mobile.Analog import dial 2 from .Analog import dial 3 from ..common_util import setup 4 from ..Fax import G3.dial
当python解释器在标准模式下启动时,一些模块会被解释器自动导入,用于系统相关操作,唯一一个影响你的是__builtin__模块,它会正常的被载入,这和__builtins__模块相同。
sys.modules变量包含一个由当前载入(完整且成功导入)到解释器的模块组成的字典,模块名作为键,它们的位置作为值。
1 >>> import sys 2 >>> sys.modules.keys() 3 [‘copy_reg‘, ‘sre_compile‘, ‘locale‘, ‘_sre‘, ‘functools‘, ‘encodings‘, ‘site‘, ‘__builtin__‘, ‘sysconfig‘, ‘operator‘, ‘__main__‘, ‘types‘, ‘encodings.encodings‘, ‘encodings.gbk‘, ‘abc‘, ‘_weakrefset‘, ‘encodings._codecs_cn‘, ‘errno‘, ‘encodings.codecs‘, ‘sre_constants‘, ‘re‘, ‘_abcoll‘, ‘ntpath‘, ‘_codecs‘, ‘encodings._multibytecodec‘, ‘nt‘, ‘_warnings‘, ‘genericpath‘, ‘stat‘, ‘zipimport‘, ‘encodings.__builtin__‘, ‘warnings‘, ‘UserDict‘, ‘_multibytecodec‘, ‘sys‘, ‘codecs‘, ‘os.path‘, ‘_functools‘, ‘_codecs_cn‘, ‘_locale‘, ‘signal‘, ‘traceback‘, ‘linecache‘, ‘encodings.aliases‘, ‘exceptions‘, ‘sre_parse‘, ‘os‘, ‘_weakref‘] 4 >>>
1.8.2 阻止属性导入
如果不想某个模块属性被“from module import *“导入,可给不想导入的属性名称加上一个下划线(_),不过如果你导入了整个模块或者你显示的导入某个属性(例如import foo._bar),这个隐藏数据的办法就不起作用了。
python的模块文件默认是ASCLL码,只要在python模块头部加入一个额外的编码指示说明就可以让导入者使用指定的编码解析你的模块,编码对应的Unicode字符串。一个UTF-8编码的文件可以这样指示:
1 #!/usr/bin/env python 2 # -*- coding:UTF-8 -*-
标签:解释器 指示 and pen 加载 检查 font overflow lex
原文地址:https://www.cnblogs.com/mrlayfolk/p/12064142.html