标签:png 源代码 hand app host 内容 sam target int
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
51Job一线城市程序员岗位爬虫
2.主题式网络爬虫爬取的内容与数据特征分析
2.1爬取内容:
岗位、公司、薪酬范围、工作经验要求、学历、地区、公司规模、公司类型
2.2数据特征分析:
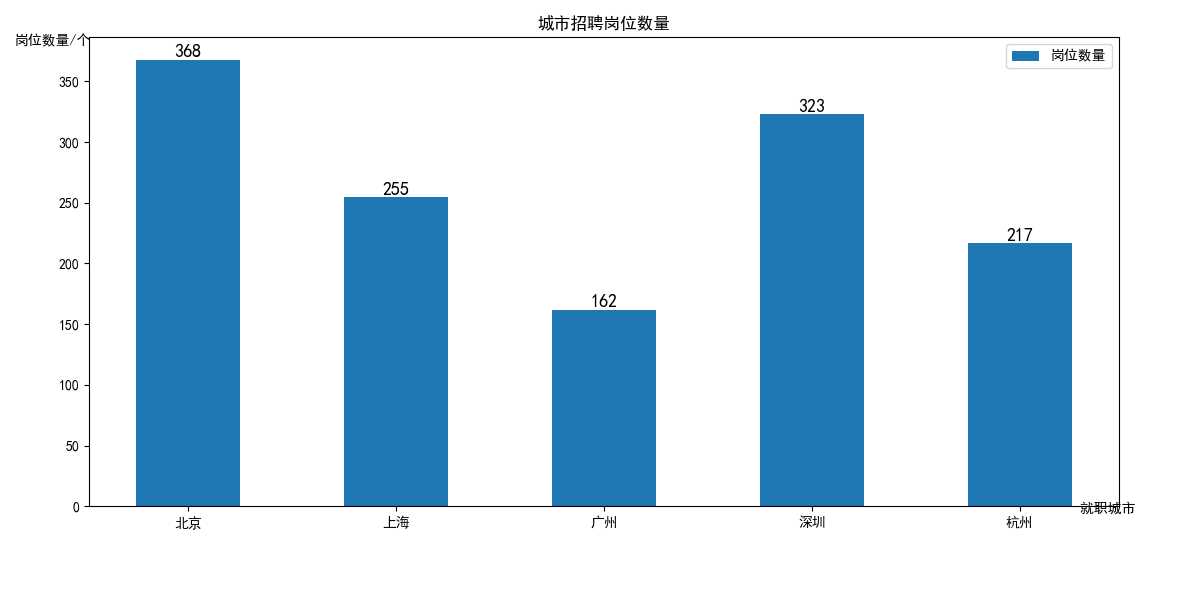
针对就职城市做一个柱状图分析
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
实现思路:
使用requests库爬取数据
使用pymysql进行数据处理
使用matplotlib模块实现数据可视化
技术难点:
模拟浏览器访问招聘网爬取数据
对繁杂的数据进行清洗,获取有效数据
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
页面的结构大体为包含搜索的顶部标题栏、包含筛选条件的职位展示列表、和网站信息的底部栏,我们所需要的数据包含于dw_wp的中间结构
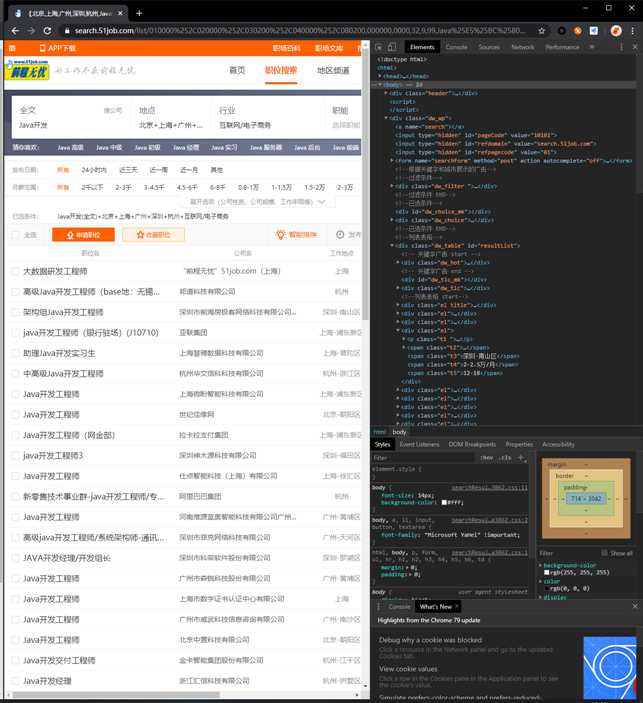
2.Htmls页面解析
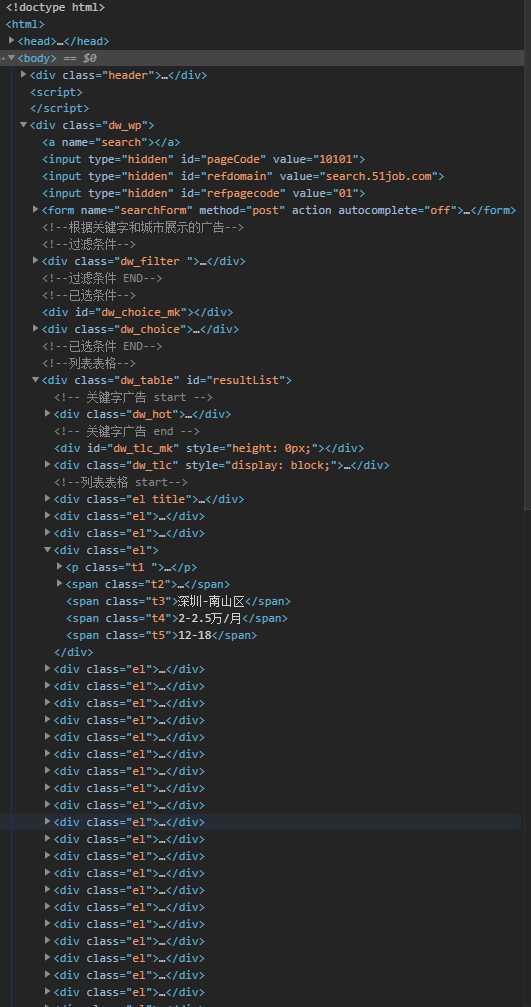
我们所需要的数据包含于dw_wp盒子的dw_table部分,以列表表格形式展示招聘信息,在el标签的子标签以t1~t5提供我们需要的职位、公司名、工作地点、薪资、发布时间的数据,我们针对该结构来构思爬取数据的方法
3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
<html>→<div class="dw_wp">→<div class="el">→<p class="t1"><span class="t2">~<span class="t5">
def sub_page(self, href): try: response = self.response_handler(href) resp = response.text html = etree.HTML(resp) div = html.xpath("//div[@class=‘cn‘]") if len(div) > 0: div = div[0] else: return None wages = div.xpath(".//strong/text()") if len(wages) > 0: wages = str(wages[0]) if wages[-1].endswith("元") or wages.endswith("年") or wages.find("千") != -1: return None min_wage = wages.split("-")[0] min_wage = float(min_wage) * 10000 max_wage = wages.split("-")[1] if max_wage.find("万") != -1: i = max_wage.index("万") max_wage = float(max_wage[0:i]) * 10000 else: return None else: return None title = div.xpath(".//p[@class=‘msg ltype‘]/text()") city = re.sub("\\n|\\t|\\r|\\xa0", "", title[0]) experience = re.sub("\\n|\\t|\\r|\\xa0", "", title[1]) education = re.sub("\\n|\\t|\\r|\\xa0", "", title[2]) post = div.xpath(".//h1/@title")[0] company = div.xpath(".//p[@class=‘cname‘]/a/@title")[0] scale = html.xpath("//div[@class=‘com_tag‘]/p/@title")[1] nature = html.xpath("//div[@class=‘com_tag‘]/p/@title")[0] item = {"min_wages": min_wage, "max_wages": max_wage, "experience": experience, "education": education, "city": city, "post": post, "company": company, "scale": scale, "nature": nature} return item except Exception: return None
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
#导入包 import requests import re from lxml import etree import pymysql import time #模仿浏览器访问目标地址 class crawl(): #标识请求头 def __init__(self): self.headers = { "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/71.0.3578.98 Safari/537.36", "Host": "search.51job.com", "Referer": "https://www.51job.com/", "Upgrade-Insecure-Requests": "1", "Cookie": "guid=667fe7f59e43e367a18efcf690e3d464; " "slife=lowbrowser%3Dnot%26%7C%26lastlogindate%3D20190412%26%7C%26; " "adv=adsnew%3D0%26%7C%26adsnum%3D2004282%26%7C%26adsresume%3D1%26%7C%26adsfrom%3Dhttps%253A" "%252F%252Fsp0.baidu.com%252F9q9JcDHa2gU2pMbgoY3K%252Fadrc.php%253Ft" "%253D06KL00c00fDewkY0gPN900uiAsa4XQKT00000c6R7dC00000v47CS_" ".THLZ_Q5n1VeHksK85HRsnj0snjckgv99UdqsusK15HbLPvFBPWcYnj0snAPWnAn0IHYYn1" "-Dn1DzrDujn1bLfHn3fbPawbc3P10vnRfzf1DLPfK95gTqFhdWpyfqn1ckPHb4nH63nzusThqbpyfqnHm0uHdCIZwsT1CEQLwzmyP-QWRkphqBQhPEUiqYTh7Wui4spZ0Omyw1UMNV5HcsnjfzrjchmyGs5y7cRWKWiDYvHZb4IAD1RgNrNDukmWFFINbzrgwnndF8HjPrUAFHrgI-Uj94HRw7PDkVpjKBNLTEyh42IhFRny-uNvkou79aPBuo5HnvuH0dPA79njfdrynzuywbPycYPvmdPvPBPWDsuj6z0APzm1YdPWT1Ps%2526tpl%253Dtpl_11534_19347_15370%2526l%253D1511462024%2526attach%253Dlocation%25253D%252526linkName%25253D%252525E6%252525A0%25252587%252525E5%25252587%25252586%252525E5%252525A4%252525B4%252525E9%25252583%252525A8-%252525E6%252525A0%25252587%252525E9%252525A2%25252598-%252525E4%252525B8%252525BB%252525E6%252525A0%25252587%252525E9%252525A2%25252598%252526linkText%25253D%252525E3%25252580%25252590%252525E5%25252589%2525258D%252525E7%252525A8%2525258B%252525E6%25252597%252525A0%252525E5%252525BF%252525A751Job%252525E3%25252580%25252591-%25252520%252525E5%252525A5%252525BD%252525E5%252525B7%252525A5%252525E4%252525BD%2525259C%252525E5%252525B0%252525BD%252525E5%2525259C%252525A8%252525E5%25252589%2525258D%252525E7%252525A8%2525258B%252525E6%25252597%252525A0%252525E5%252525BF%252525A7%2521%252526xp%25253Did%2528%25252522m3215991883_canvas%25252522%2529%2525252FDIV%2525255B1%2525255D%2525252FDIV%2525255B1%2525255D%2525252FDIV%2525255B1%2525255D%2525252FDIV%2525255B1%2525255D%2525252FDIV%2525255B1%2525255D%2525252FH2%2525255B1%2525255D%2525252FA%2525255B1%2525255D%252526linkType%25253D%252526checksum%25253D23%2526ie%253Dutf-8%2526f%253D8%2526srcqid%253D3015640922443247634%2526tn%253D50000021_hao_pg%2526wd%253D%2525E5%252589%25258D%2525E7%2525A8%25258B%2525E6%252597%2525A0%2525E5%2525BF%2525A7%2526oq%253D%2525E5%252589%25258D%2525E7%2525A8%25258B%2525E6%252597%2525A0%2525E5%2525BF%2525A7%2526rqlang%253Dcn%2526sc%253DUWd1pgw-pA7EnHc1FMfqnHRdPH0vrHDsnWb4PauW5y99U1Dznzu9m1Y1nWm3P1R4PWTz%2526ssl_sample%253Ds_102%2526H123Tmp%253Dnunew7; track=registertype%3D1; 51job=cuid%3D155474095%26%7C%26cusername%3Dphone_15592190359_201904126833%26%7C%26cpassword%3D%26%7C%26cemail%3D%26%7C%26cemailstatus%3D0%26%7C%26cnickname%3D%26%7C%26ccry%3D.0Kv7MYCl6oSc%26%7C%26cconfirmkey%3D%25241%2524pje29p9d%2524ZK3qb5Vg5.sXKVb3%252Fic9y%252F%26%7C%26cenglish%3D0%26%7C%26to%3Db9207cfd84ebc727453bdbb9b672c3a45cb0791d%26%7C%26; nsearch=jobarea%3D%26%7C%26ord_field%3D%26%7C%26recentSearch0%3D%26%7C%26recentSearch1%3D%26%7C%26recentSearch2%3D%26%7C%26recentSearch3%3D%26%7C%26recentSearch4%3D%26%7C%26collapse_expansion%3D; search=jobarea%7E%60200300%7C%21ord_field%7E%600%7C%21recentSearch0%7E%601%A1%FB%A1%FA200300%2C00%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA%B1%B1%BE%A9%A1%FB%A1%FA2%A1%FB%A1%FA%A1%FB%A1%FA-1%A1%FB%A1%FA1555069299%A1%FB%A1%FA0%A1%FB%A1%FA%A1%FB%A1%FA%7C%21", "Accept-Encoding": "gzip, deflate, br", "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8", } #初始化mysql def connnect(self): conn = pymysql.connect( host=‘127.0.0.1‘, port=3306, user=‘root‘, passwd=‘root‘, db=‘recruit‘, charset=‘utf8‘ ) return conn #接受服务器端返回数据 def response_handler(self, url): response = requests.get(url=url, headers=self.headers) return response #数据转换,将HTML转换成方便处理的数据结构 def parse(self, response): resp = response.content.decode("gbk") html = etree.HTML(resp) href = html.xpath("//p[@class=‘t1 ‘]//a[@target=‘_blank‘]/@href") return href #子页数据清洗 def sub_page(self, href): try: response = self.response_handler(href) resp = response.text #获取页面数据 html = etree.HTML(resp) #解析网页内容 div = html.xpath("//div[@class=‘cn‘]")#对标签进行数据转换 if len(div) > 0: div = div[0] else: return None wages = div.xpath(".//strong/text()") if len(wages) > 0: wages = str(wages[0]) if wages[-1].endswith("元") or wages.endswith("年") or wages.find("千") != -1: return None min_wage = wages.split("-")[0] min_wage = float(min_wage) * 10000 max_wage = wages.split("-")[1] if max_wage.find("万") != -1: i = max_wage.index("万") max_wage = float(max_wage[0:i]) * 10000 else: return None else: return None title = div.xpath(".//p[@class=‘msg ltype‘]/text()") city = re.sub("\\n|\\t|\\r|\\xa0", "", title[0]) experience = re.sub("\\n|\\t|\\r|\\xa0", "", title[1]) education = re.sub("\\n|\\t|\\r|\\xa0", "", title[2]) post = div.xpath(".//h1/@title")[0] company = div.xpath(".//p[@class=‘cname‘]/a/@title")[0] scale = html.xpath("//div[@class=‘com_tag‘]/p/@title")[1] nature = html.xpath("//div[@class=‘com_tag‘]/p/@title")[0] item = {"min_wages": min_wage, "max_wages": max_wage, "experience": experience, "education": education, "city": city, "post": post, "company": company, "scale": scale, "nature": nature} return item except Exception: return None #爬虫主函数 def main(self): url = "https://search.51job.com/list/{},000000,0000,00,9,99,{},2,{}.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=" city_list = ["010000", "020000", "030200", "040000", "080200"]#将爬取的城市数据存入list city_dict = {"010000": "北京", "020000": "上海", "030200": "广州", "040000": "深圳", "080200": "杭州"}#数据存入dict job_list = ["Java", "PHP", "C++", "数据挖掘", "Hadoop", "Python", "前端", "C"] time_start = time.time()#计时 try: for citys in city_list: for job in job_list: for i in range(1, 31): #循环操作 print("正在保存{}市{}岗位第{}页".format(city_dict[citys], job, i)) response = self.response_handler(url.format(citys, job, i)) hrefs = self.parse(response) for href in hrefs: item = self.sub_page(href) if item == None: continue conn = self.connnect() cur = conn.cursor() #存储数据至sql sql = "insert into tbl_qcwy_data(post,min_wages,max_wages,experience,education,city,company,scale,nature) values(%s,%s,%s,%s,%s,%s,%s,%s,%s)" cur.execute(sql, ( item[‘post‘], item[‘min_wages‘], item[‘max_wages‘], item[‘experience‘], item[‘education‘], item[‘city‘], item[‘company‘], item[‘scale‘], item[‘nature‘])) conn.commit() cur.close() conn.close() time_end = time.time() print("共用时{}".format(time_end - time_start)) except Exception: print("异常") if __name__ == ‘__main__‘: c = crawl() c.main()
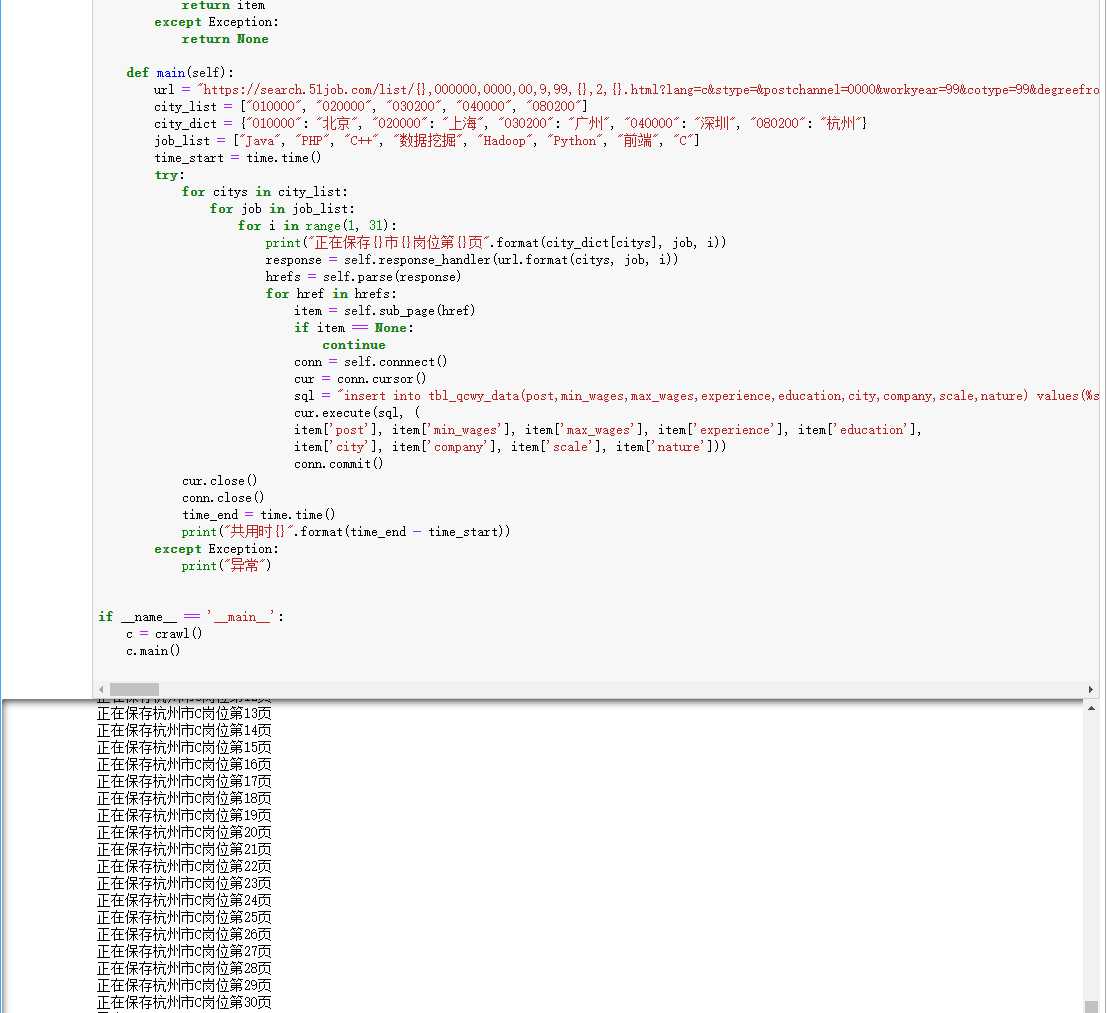
2.对数据进行清洗和处理
def sub_page(self, href): try: response = self.response_handler(href) resp = response.text #获取页面数据 html = etree.HTML(resp) #解析网页内容 div = html.xpath("//div[@class=‘cn‘]")#对标签进行数据转换 if len(div) > 0: div = div[0] else: return None wages = div.xpath(".//strong/text()") if len(wages) > 0: wages = str(wages[0]) if wages[-1].endswith("元") or wages.endswith("年") or wages.find("千") != -1: return None min_wage = wages.split("-")[0] min_wage = float(min_wage) * 10000 max_wage = wages.split("-")[1] if max_wage.find("万") != -1: i = max_wage.index("万") max_wage = float(max_wage[0:i]) * 10000 else: return None else: return None title = div.xpath(".//p[@class=‘msg ltype‘]/text()") city = re.sub("\\n|\\t|\\r|\\xa0", "", title[0]) experience = re.sub("\\n|\\t|\\r|\\xa0", "", title[1]) education = re.sub("\\n|\\t|\\r|\\xa0", "", title[2]) post = div.xpath(".//h1/@title")[0] company = div.xpath(".//p[@class=‘cname‘]/a/@title")[0] scale = html.xpath("//div[@class=‘com_tag‘]/p/@title")[1] nature = html.xpath("//div[@class=‘com_tag‘]/p/@title")[0] item = {"min_wages": min_wage, "max_wages": max_wage, "experience": experience, "education": education, "city": city, "post": post, "company": company, "scale": scale, "nature": nature} return item except Exception: return None
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
# 读取CSV文件 df = pd.read_csv(‘recruit_data.csv‘, encoding=‘utf-8‘, engine=‘python‘) # 工作城市 city_list = [‘北京‘, ‘上海‘, ‘广州‘, ‘深圳‘, ‘杭州‘] # 工作数量 city_number = [len(df[df.post.str.contains(‘北京|北京|北京‘, na=False)])] # 遍历列表 for i in range(len(city_list)): if i != 0: city_number.append(len(df[df.post.str.contains(city_list[i], na=False)])) #数据可视化 plt.figure(figsize=(12, 6)) plt.bar(city_list, city_number, width=0.5, label=‘岗位数量‘) plt.title(‘城市招聘岗位数量‘) plt.legend() plt.xlabel(‘ ‘ * 72 + ‘就职城市‘ + ‘\n‘ * 5, labelpad=10, ha=‘left‘, va=‘center‘) plt.ylabel(‘岗位数量/个‘ + ‘\n‘ * 17, rotation=0) # 进行图标签 for a, b in zip(city_list, city_number): plt.text(a, b + 0.1, ‘%.0f‘ % b, ha=‘center‘, va=‘bottom‘, fontsize=13) plt.show()
5.数据持久化
数据存储于数据库,导出为csv文件保存
6.附完整程序代码
import requests import re from lxml import etree import pymysql import time import pandas as pd import matplotlib.pyplot as plt import matplotlib #模仿浏览器访问目标地址 class crawl(): #标识请求头 def __init__(self): self.headers = { "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/71.0.3578.98 Safari/537.36", "Host": "search.51job.com", "Referer": "https://www.51job.com/", "Upgrade-Insecure-Requests": "1", "Cookie": "guid=667fe7f59e43e367a18efcf690e3d464; " "slife=lowbrowser%3Dnot%26%7C%26lastlogindate%3D20190412%26%7C%26; " "adv=adsnew%3D0%26%7C%26adsnum%3D2004282%26%7C%26adsresume%3D1%26%7C%26adsfrom%3Dhttps%253A" "%252F%252Fsp0.baidu.com%252F9q9JcDHa2gU2pMbgoY3K%252Fadrc.php%253Ft" "%253D06KL00c00fDewkY0gPN900uiAsa4XQKT00000c6R7dC00000v47CS_" ".THLZ_Q5n1VeHksK85HRsnj0snjckgv99UdqsusK15HbLPvFBPWcYnj0snAPWnAn0IHYYn1" "-Dn1DzrDujn1bLfHn3fbPawbc3P10vnRfzf1DLPfK95gTqFhdWpyfqn1ckPHb4nH63nzusThqbpyfqnHm0uHdCIZwsT1CEQLwzmyP-QWRkphqBQhPEUiqYTh7Wui4spZ0Omyw1UMNV5HcsnjfzrjchmyGs5y7cRWKWiDYvHZb4IAD1RgNrNDukmWFFINbzrgwnndF8HjPrUAFHrgI-Uj94HRw7PDkVpjKBNLTEyh42IhFRny-uNvkou79aPBuo5HnvuH0dPA79njfdrynzuywbPycYPvmdPvPBPWDsuj6z0APzm1YdPWT1Ps%2526tpl%253Dtpl_11534_19347_15370%2526l%253D1511462024%2526attach%253Dlocation%25253D%252526linkName%25253D%252525E6%252525A0%25252587%252525E5%25252587%25252586%252525E5%252525A4%252525B4%252525E9%25252583%252525A8-%252525E6%252525A0%25252587%252525E9%252525A2%25252598-%252525E4%252525B8%252525BB%252525E6%252525A0%25252587%252525E9%252525A2%25252598%252526linkText%25253D%252525E3%25252580%25252590%252525E5%25252589%2525258D%252525E7%252525A8%2525258B%252525E6%25252597%252525A0%252525E5%252525BF%252525A751Job%252525E3%25252580%25252591-%25252520%252525E5%252525A5%252525BD%252525E5%252525B7%252525A5%252525E4%252525BD%2525259C%252525E5%252525B0%252525BD%252525E5%2525259C%252525A8%252525E5%25252589%2525258D%252525E7%252525A8%2525258B%252525E6%25252597%252525A0%252525E5%252525BF%252525A7%2521%252526xp%25253Did%2528%25252522m3215991883_canvas%25252522%2529%2525252FDIV%2525255B1%2525255D%2525252FDIV%2525255B1%2525255D%2525252FDIV%2525255B1%2525255D%2525252FDIV%2525255B1%2525255D%2525252FDIV%2525255B1%2525255D%2525252FH2%2525255B1%2525255D%2525252FA%2525255B1%2525255D%252526linkType%25253D%252526checksum%25253D23%2526ie%253Dutf-8%2526f%253D8%2526srcqid%253D3015640922443247634%2526tn%253D50000021_hao_pg%2526wd%253D%2525E5%252589%25258D%2525E7%2525A8%25258B%2525E6%252597%2525A0%2525E5%2525BF%2525A7%2526oq%253D%2525E5%252589%25258D%2525E7%2525A8%25258B%2525E6%252597%2525A0%2525E5%2525BF%2525A7%2526rqlang%253Dcn%2526sc%253DUWd1pgw-pA7EnHc1FMfqnHRdPH0vrHDsnWb4PauW5y99U1Dznzu9m1Y1nWm3P1R4PWTz%2526ssl_sample%253Ds_102%2526H123Tmp%253Dnunew7; track=registertype%3D1; 51job=cuid%3D155474095%26%7C%26cusername%3Dphone_15592190359_201904126833%26%7C%26cpassword%3D%26%7C%26cemail%3D%26%7C%26cemailstatus%3D0%26%7C%26cnickname%3D%26%7C%26ccry%3D.0Kv7MYCl6oSc%26%7C%26cconfirmkey%3D%25241%2524pje29p9d%2524ZK3qb5Vg5.sXKVb3%252Fic9y%252F%26%7C%26cenglish%3D0%26%7C%26to%3Db9207cfd84ebc727453bdbb9b672c3a45cb0791d%26%7C%26; nsearch=jobarea%3D%26%7C%26ord_field%3D%26%7C%26recentSearch0%3D%26%7C%26recentSearch1%3D%26%7C%26recentSearch2%3D%26%7C%26recentSearch3%3D%26%7C%26recentSearch4%3D%26%7C%26collapse_expansion%3D; search=jobarea%7E%60200300%7C%21ord_field%7E%600%7C%21recentSearch0%7E%601%A1%FB%A1%FA200300%2C00%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA%B1%B1%BE%A9%A1%FB%A1%FA2%A1%FB%A1%FA%A1%FB%A1%FA-1%A1%FB%A1%FA1555069299%A1%FB%A1%FA0%A1%FB%A1%FA%A1%FB%A1%FA%7C%21", "Accept-Encoding": "gzip, deflate, br", "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8", } #初始化mysql def connnect(self): conn = pymysql.connect( host=‘127.0.0.1‘, port=3306, user=‘root‘, passwd=‘root‘, db=‘recruit‘, charset=‘utf8‘ ) return conn #接受服务器端返回数据 def response_handler(self, url): response = requests.get(url=url, headers=self.headers) return response #数据转换,将HTML转换成方便处理的数据结构 def parse(self, response): resp = response.content.decode("gbk") html = etree.HTML(resp) href = html.xpath("//p[@class=‘t1 ‘]//a[@target=‘_blank‘]/@href") return href #子页数据清洗 def sub_page(self, href): try: response = self.response_handler(href) resp = response.text #获取页面数据 html = etree.HTML(resp) #解析网页内容 div = html.xpath("//div[@class=‘cn‘]")#对标签进行数据转换 if len(div) > 0: div = div[0] else: return None wages = div.xpath(".//strong/text()") if len(wages) > 0: wages = str(wages[0]) if wages[-1].endswith("元") or wages.endswith("年") or wages.find("千") != -1: return None min_wage = wages.split("-")[0] min_wage = float(min_wage) * 10000 max_wage = wages.split("-")[1] if max_wage.find("万") != -1: i = max_wage.index("万") max_wage = float(max_wage[0:i]) * 10000 else: return None else: return None title = div.xpath(".//p[@class=‘msg ltype‘]/text()") city = re.sub("\\n|\\t|\\r|\\xa0", "", title[0]) experience = re.sub("\\n|\\t|\\r|\\xa0", "", title[1]) education = re.sub("\\n|\\t|\\r|\\xa0", "", title[2]) post = div.xpath(".//h1/@title")[0] company = div.xpath(".//p[@class=‘cname‘]/a/@title")[0] scale = html.xpath("//div[@class=‘com_tag‘]/p/@title")[1] nature = html.xpath("//div[@class=‘com_tag‘]/p/@title")[0] item = {"min_wages": min_wage, "max_wages": max_wage, "experience": experience, "education": education, "city": city, "post": post, "company": company, "scale": scale, "nature": nature} return item except Exception: return None #爬虫主函数 def main(self): url = "https://search.51job.com/list/{},000000,0000,00,9,99,{},2,{}.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=" city_list = ["010000", "020000", "030200", "040000", "080200"]#将爬取的城市数据存入list city_dict = {"010000": "北京", "020000": "上海", "030200": "广州", "040000": "深圳", "080200": "杭州"}#数据存入dict job_list = ["Java", "PHP", "C++", "数据挖掘", "Hadoop", "Python", "前端", "C"] time_start = time.time()#计时 try: for citys in city_list: for job in job_list: for i in range(1, 31): #循环操作 print("正在保存{}市{}岗位第{}页".format(city_dict[citys], job, i)) response = self.response_handler(url.format(citys, job, i)) hrefs = self.parse(response) for href in hrefs: item = self.sub_page(href) if item == None: continue conn = self.connnect() cur = conn.cursor() #存储数据至sql sql = "insert into tbl_qcwy_data(post,min_wages,max_wages,experience,education,city,company,scale,nature) values(%s,%s,%s,%s,%s,%s,%s,%s,%s)" cur.execute(sql, ( item[‘post‘], item[‘min_wages‘], item[‘max_wages‘], item[‘experience‘], item[‘education‘], item[‘city‘], item[‘company‘], item[‘scale‘], item[‘nature‘])) conn.commit() cur.close() conn.close() time_end = time.time() print("共用时{}".format(time_end - time_start)) except Exception: print("异常") if __name__ == ‘__main__‘: c = crawl() c.main() ———————————————————— # 统计各个城市中招聘岗位的数量 font = {‘family‘: ‘SimHei‘} matplotlib.rc(‘font‘, **font) # 读取CSV文件 df = pd.read_csv(‘recruit_data.csv‘, encoding=‘utf-8‘, engine=‘python‘) # 工作城市 city_list = [‘北京‘, ‘上海‘, ‘广州‘, ‘深圳‘, ‘杭州‘] # 工作数量 city_number = [len(df[df.post.str.contains(‘北京|北京|北京‘, na=False)])] # 遍历列表 for i in range(len(city_list)): if i != 0: city_number.append(len(df[df.post.str.contains(city_list[i], na=False)])) #数据可视化 plt.figure(figsize=(12, 6)) plt.bar(city_list, city_number, width=0.5, label=‘岗位数量‘) plt.title(‘城市招聘岗位数量‘) plt.legend() plt.xlabel(‘ ‘ * 72 + ‘就职城市‘ + ‘\n‘ * 5, labelpad=10, ha=‘left‘, va=‘center‘) plt.ylabel(‘岗位数量/个‘ + ‘\n‘ * 17, rotation=0) # 进行图标签 for a, b in zip(city_list, city_number): plt.text(a, b + 0.1, ‘%.0f‘ % b, ha=‘center‘, va=‘bottom‘, fontsize=13) plt.show()
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
经过数据分析和可视化得出在一线城市现在的岗位需求最多JAVA工程师,北京和深圳的就业机会相比其他城市较多,如果能熟练掌握JAVA、Python等主流语言能在这些城市获得更多的就业机会。
大数据开发工程师的岗位需求量与日俱增,学习python进行大数据处理成为满足工作需求的一大助力。
2.对本次程序设计任务完成的情况做一个简单的小结。
饶了很大的弯,尝试了几种方法来尝试爬取招聘网的数据,最后做出的爬虫能实现构思的效果但总体结构和一开始大为不同,有许多可以精进的地方,下次希望尝试使用BeautifulSoup来简化处理数据的部分,针对反爬虫的研究还有许多不明白的部分,在日后的尝试中希望再加深研究,完善成熟一个稳定的爬虫项目。
标签:png 源代码 hand app host 内容 sam target int
原文地址:https://www.cnblogs.com/obororai/p/12064774.html