标签:call addheader 根据 很多 就是 size and 使用 博客
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: 易某某
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
安装了Fiddler了(用于抓包分析)
谷歌或火狐浏览器
如果是谷歌浏览器,还需要给谷歌浏览器安装一个SwitchyOmega插件,用于代理服务器
有Python的编译环境,一般选择Python3.0及以上
声明:本次爬取腾讯视频里 《最美公里》纪录片的评论。本次爬取使用的浏览器是谷歌浏览器
1、分析评论页面
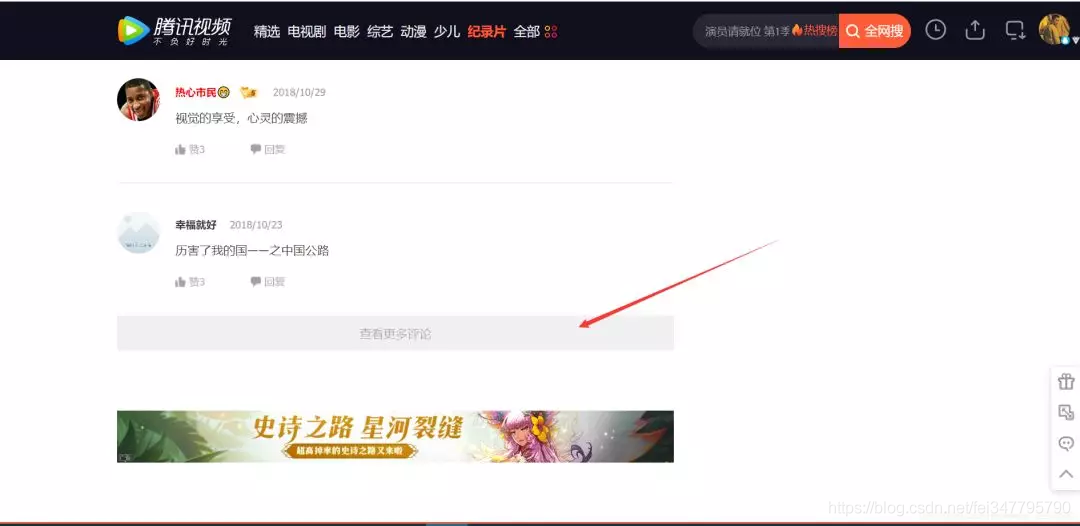
根据上图,我们可以知道:评论使用了Ajax异步刷新技术。这样就不能使用以前分析当前页面找出规律的手段了。因为展示的页面只有部分评论,还有大量的评论没有被刷新出来。
这时,我们应该想到使用抓包来分析评论页面刷新的规律。以后大部分爬虫,都会先使用抓包技术,分析出规律!
2、使用Fiddler进行抓包分析——得出评论网址规律
fiddler如何抓包,这个知识点,需要读者自行去学习,不在本博客讨论范围。
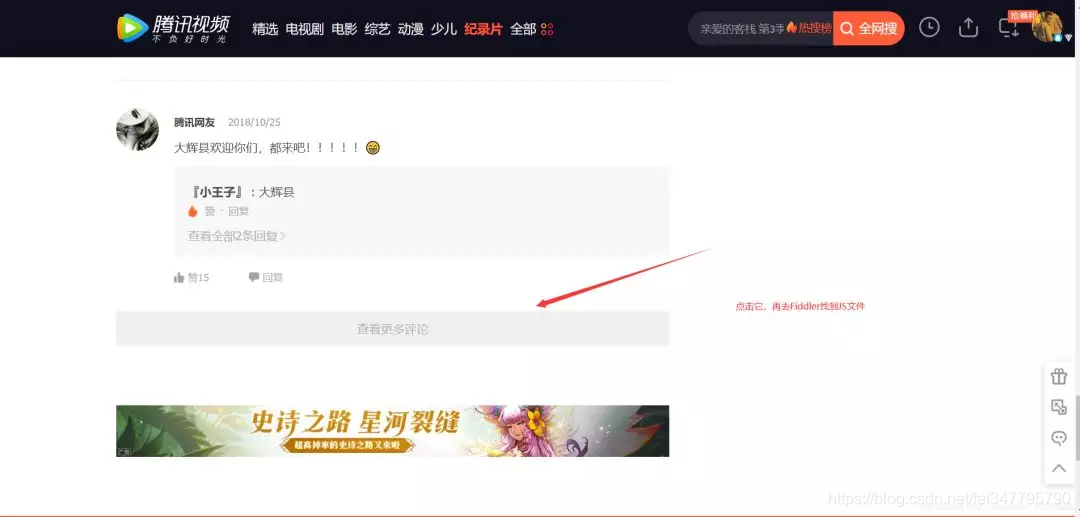
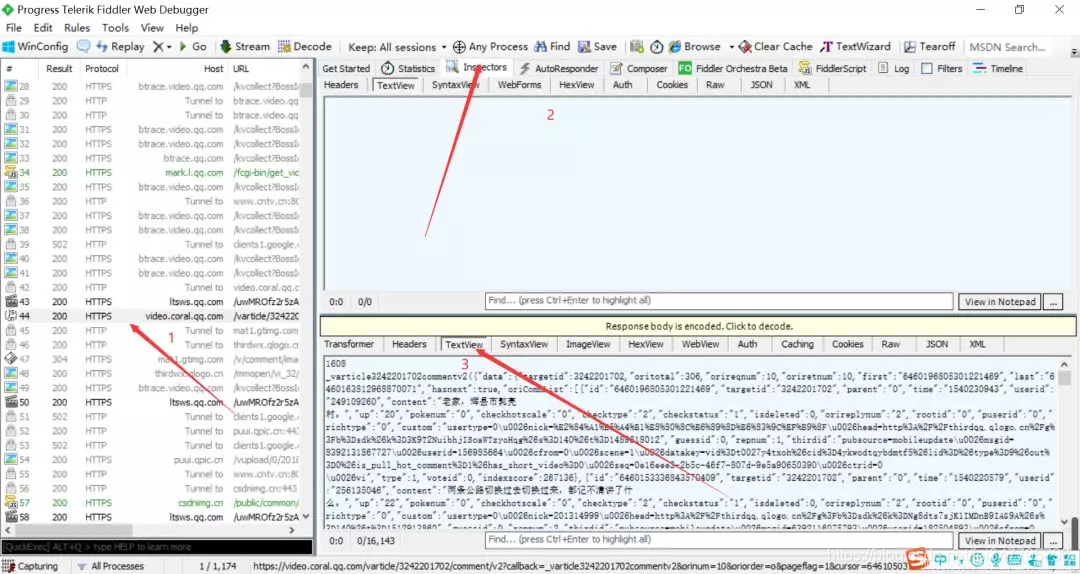
把上面两张图里面的内容对比一下,可以知道这个JS就是评论存放页面。(这需要大家一个一个找,一般Ajax都是在JS里面,所以这也找JS进行对比即可)
我们复制这个JS的url:右击 > copy > Just Url
大家可以重复操作几次,多找几个JS的url,从url得出规律。下图是我刷新了4次得到的JS的url:
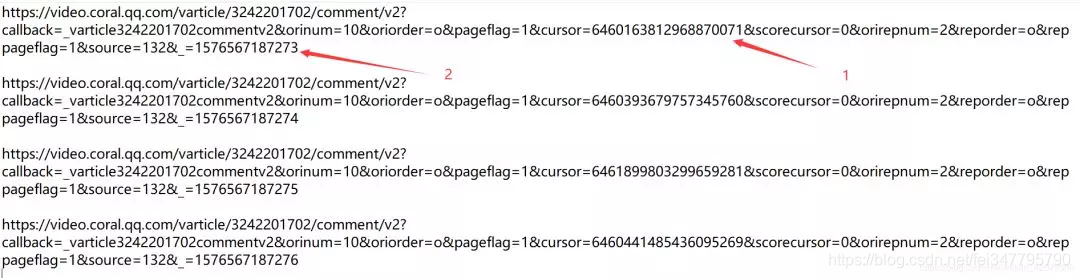
根据上图,我们发现url不同的地方有两处:一是cursor=?;二是_=?。
我们很快就能发现 _=?的规律,它是从1576567187273加1。而cursor=?的规律看不出来。这个时候如何去找到它的规律呢?
百度一下,看前人有没有爬取过这种类型的网站,根据他们的规律和方法,去找出规律;
羊毛出在羊身上。我们需要有的大胆想法——会不会这个cursor=?可以根据上一个JS页面得到呢?这只是很多大胆想法中的一个,我们就一个想法一个想法的试试。
我们就采用第二种方法,去js里面找。复制其中一个url为:
url = https://video.coral.qq.com/varticle/3242201702/comment/v2?callback=_varticle3242201702commentv2&orinum=10&oriorder=o&pageflag=1&cursor=6460163812968870071&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&_=1576567187273
去浏览器里面打开,在里面搜索一下此url的下一个url的cursor=?的值。我们发现一个惊喜!
如下:
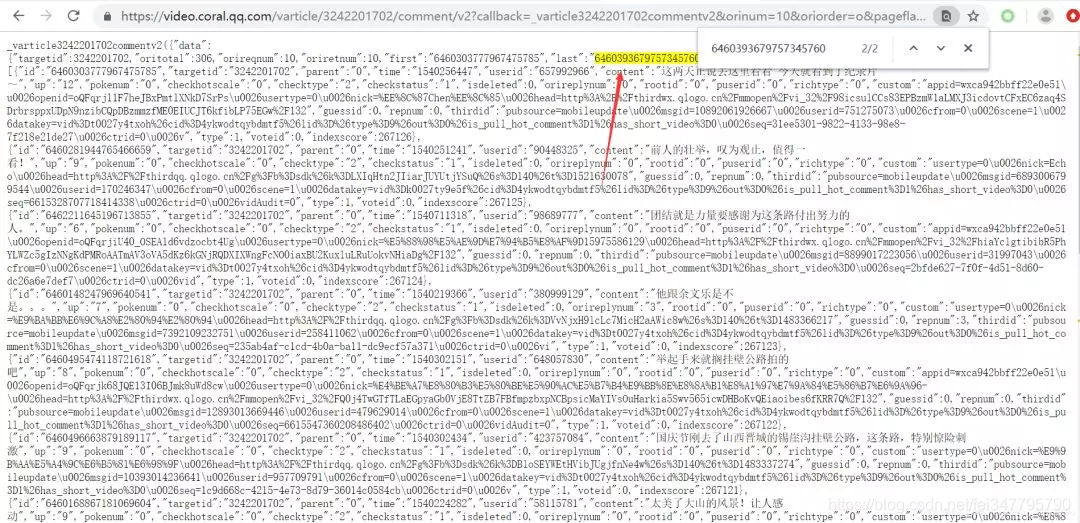
一般情况下,我们还要多试几次,确定我们的想法是正确的。
至此,我们发现了评论的url之间的规律:
_=?从1576567187273加1
cursor=?的值存在上面一个JS中。
1 import re 2 import random 3 import urllib.request 4 ? 5 #构建用户代理 6 uapools=["Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36", 7 "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36", 8 "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:71.0) Gecko/20100101 Firefox/71.0", 9 ] 10 #从用户代理池随机选取一个用户代理 11 def ua(uapools): 12 thisua=random.choice(uapools) 13 #print(thisua) 14 headers=("User-Agent",thisua) 15 opener=urllib.request.build_opener() 16 opener.addheaders=[headers] 17 #设置为全局变量 18 urllib.request.install_opener(opener) 19 ? 20 #获取源码 21 def get_content(page,lastId): 22 url="https://video.coral.qq.com/varticle/3242201702/comment/v2?callback=_varticle3242201702commentv2&orinum=10&oriorder=o&pageflag=1&cursor="+lastId+"&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&_="+str(page) 23 html=urllib.request.urlopen(url).read().decode("utf-8","ignore") 24 return html 25 ? 26 #从源码中获取评论的数据 27 def get_comment(html): 28 pat=‘"content":"(.*?)"‘ 29 rst = re.compile(pat,re.S).findall(html) 30 return rst 31 ? 32 #从源码中获取下一轮刷新页的ID 33 def get_lastId(html): 34 pat=‘"last":"(.*?)"‘ 35 lastId = re.compile(pat,re.S).findall(html)[0] 36 return lastId 37 ? 38 def main(): 39 ua(uapools) 40 #初始页面 41 page=1576567187274 42 #初始待刷新页面ID 43 lastId="6460393679757345760" 44 for i in range(1,6): 45 html = get_content(page,lastId) 46 #获取评论数据 47 commentlist=get_comment(html) 48 print("------第"+str(i)+"轮页面评论------") 49 for j in range(1,len(commentlist)): 50 print("第"+str(j)+"条评论:" +str(commentlist[j])) 51 #获取下一轮刷新页ID 52 lastId=get_lastId(html) 53 page += 1 54 ? 55 main()
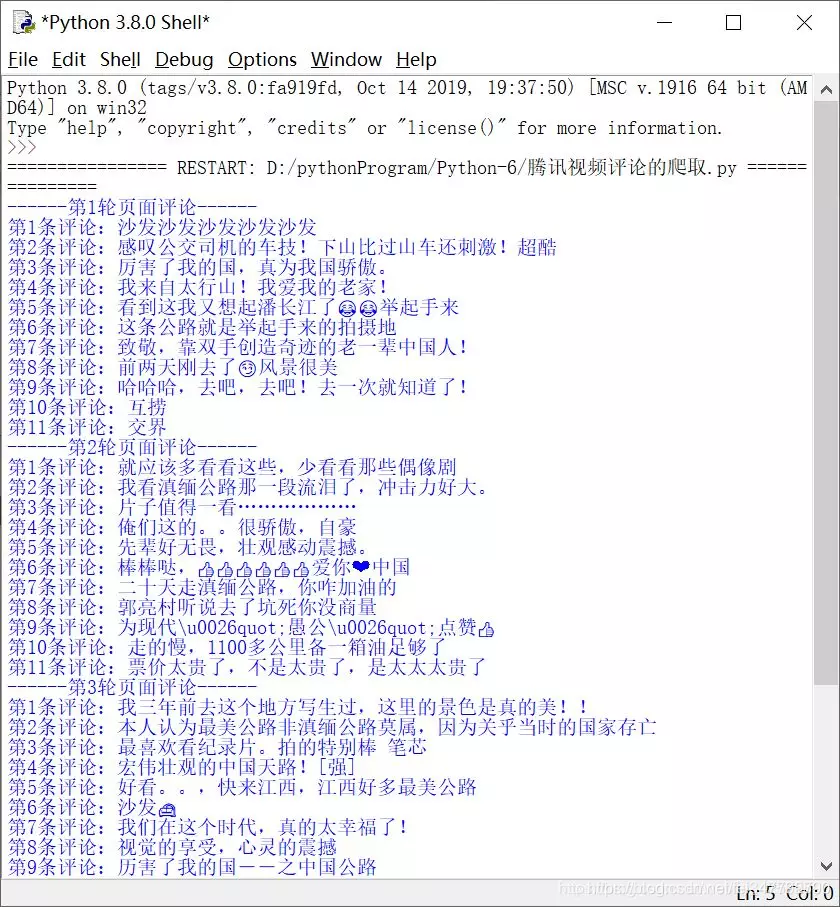
标签:call addheader 根据 很多 就是 size and 使用 博客
原文地址:https://www.cnblogs.com/Qqun821460695/p/12067594.html