标签:概率分布 flow 一个 png str col 语言 rop 结果
import tensorflow as tf # 1. sparse_softmax_cross_entropy_with_logits样例。 # 假设词汇表的大小为3, 语料包含两个单词"2 0" word_labels = tf.constant([2, 0]) # 假设模型对两个单词预测时,产生的logit分别是[2.0, -1.0, 3.0]和[1.0, 0.0, -0.5] predict_logits = tf.constant([[2.0, -1.0, 3.0], [1.0, 0.0, -0.5]]) # 使用sparse_softmax_cross_entropy_with_logits计算交叉熵。 loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=word_labels, logits=predict_logits) # 运行程序,计算loss的结果是[0.32656264, 0.46436879], 这对应两个预测的 # perplexity损失。 sess = tf.Session() print(sess.run(loss))
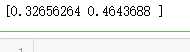
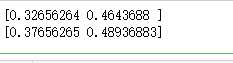
# 2. softmax_cross_entropy_with_logits样例。 # softmax_cross_entropy_with_logits与上面的函数相似,但是需要将预测目标以 # 概率分布的形式给出。 word_prob_distribution = tf.constant([[0.0, 0.0, 1.0], [1.0, 0.0, 0.0]]) loss = tf.nn.softmax_cross_entropy_with_logits(labels=word_prob_distribution, logits=predict_logits) # 运行结果与上面相同:[ 0.32656264, 0.46436879] print(sess.run(loss)) # label smoothing:将正确数据的概率设为一个比1.0略小的值,将错误数据的概率 # 设为比0.0略大的值,这样可以避免模型与数据过拟合,在某些时候可以提高训练效果。 word_prob_smooth = tf.constant([[0.01, 0.01, 0.98], [0.98, 0.01, 0.01]]) loss = tf.nn.softmax_cross_entropy_with_logits(labels=word_prob_smooth, logits=predict_logits) # 运行结果:[ 0.37656265, 0.48936883] print(sess.run(loss)) sess.close()
吴裕雄--天生自然 pythonTensorFlow自然语言处理:交叉熵损失函数
标签:概率分布 flow 一个 png str col 语言 rop 结果
原文地址:https://www.cnblogs.com/tszr/p/12068018.html