标签:otl pap plot gzip 价格 try 结束 简单的 cts
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
爬取毒APP鞋类的产品信息
2.主题式网络爬虫爬取的内容与数据特征分析
2.1爬取的内容:商品ID,鞋子的款式,商品发布日期,商品详细地址等
2.2数据特征分析
分析了商品的品牌名,可以查看产品的图片,商品分类列表,商品编号,商品的发售日期,商品的款式颜色,以及价格等信息
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
3.1实现思路:
创建一个DuApp的类,定义_init_()方法用来处理每一的请求,sellDate_list_url()方法用来构建该商品的发售日期,brand_list_url()方法构建商品品类列列表,product _detail_url()方法构建商品详情,getTime获取具体时间精确到某年某月某日,有的是直接某个季节,text_save()方法保存数据到csv文件中,data_write将数据写入新文件。Filename为写入CSV文件的途径
3.2技术难点:
Import pymongo导入模块;为了连接MongoDB,需要使用PyMongo库里面的MongoClient传入MongoDB的IP及端口,第一个参数为地址host,第二个为默认端口,不用给其传输数据,默认就是27017。设置回送地址127.0.0.1,用来测试,爬取到的
User-Agent:是一个特殊字符串头,是服务器可识别用户的操作系统及浏览器,我这里写了可以识别360浏览器,谷歌浏览器,和微信小程序的代码。
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
每页30项数据,共计181页,数据项10840,不存在应拖动滚动条而动态加载的数据项,即div,通过右键查看网页源代码分析需要提取的数据是否存在动态生成的数据,任意查看一个数据项中与原网页中的数据对比后,发现所需要爬取的数据都是静态的。
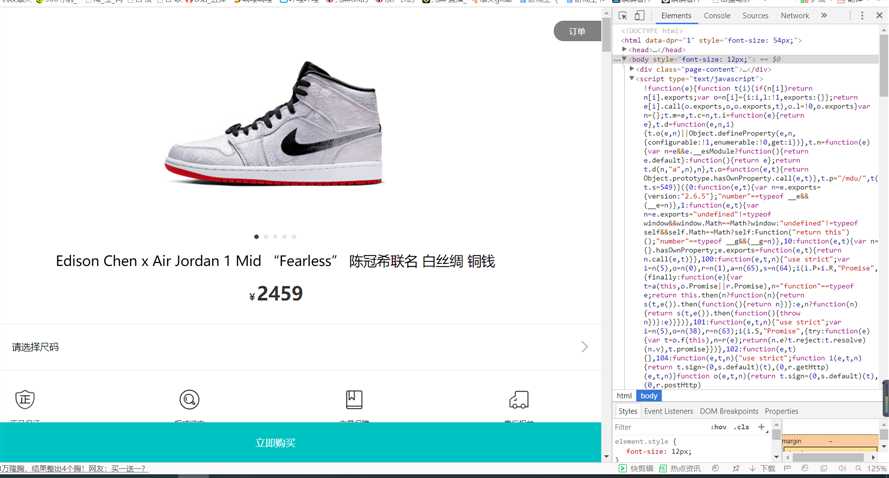
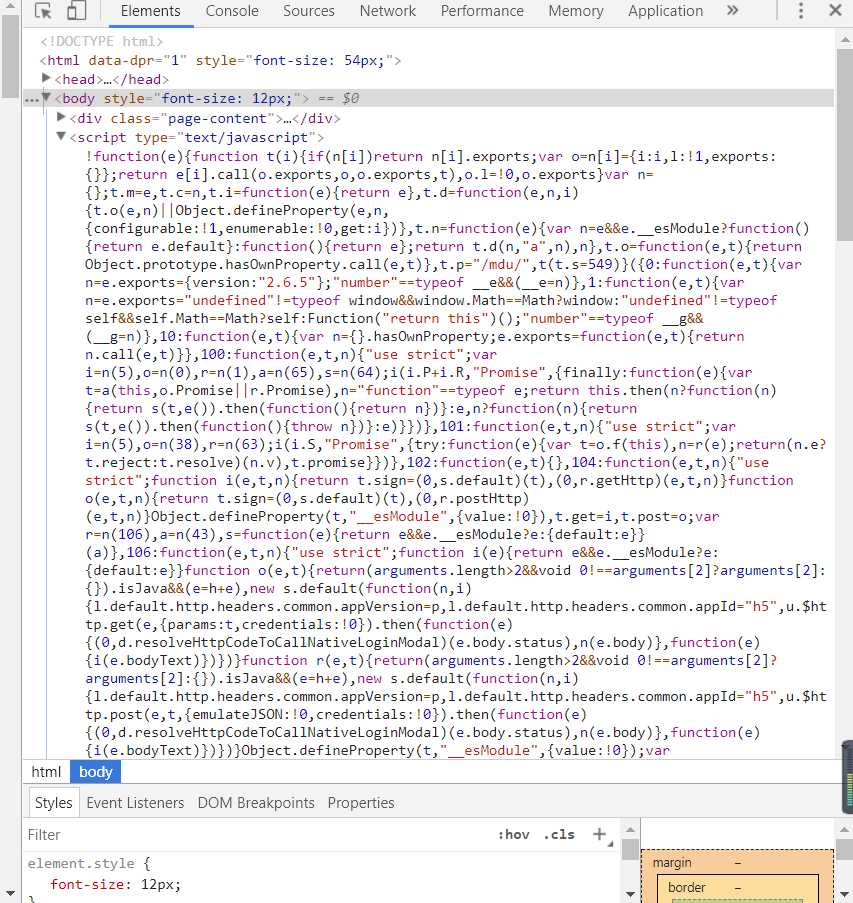
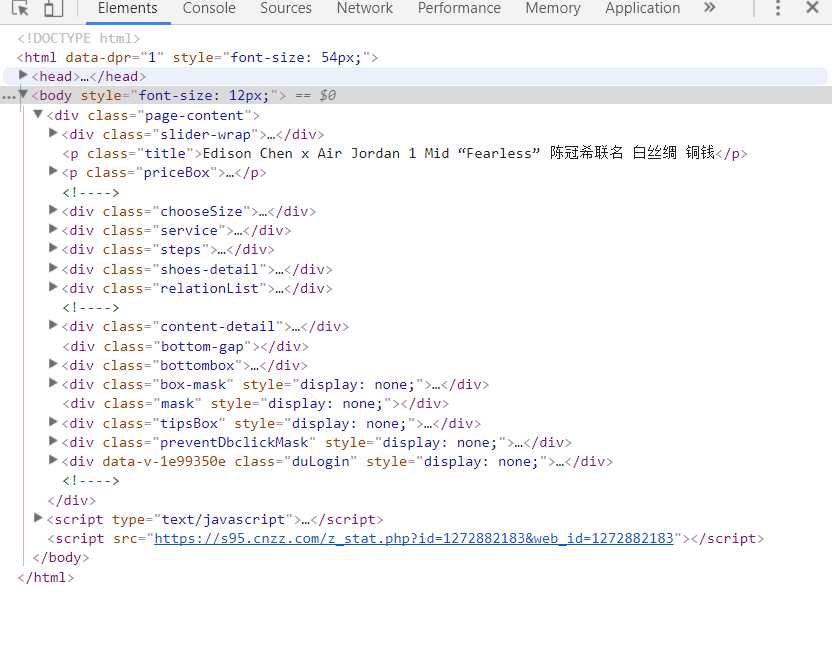
2.Htmls页面解析
要爬取的是网页中的部分信息,如:商品编号,商品的品牌、颜色、款式、发售日期等信息
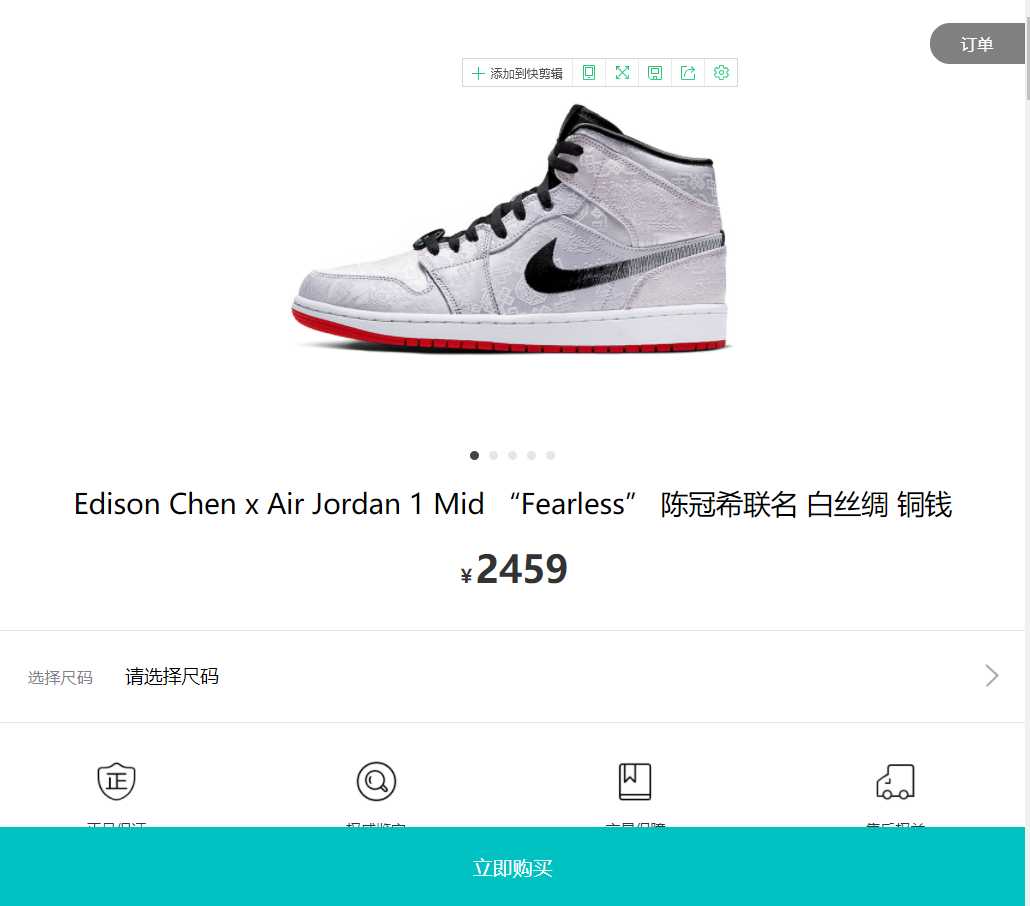
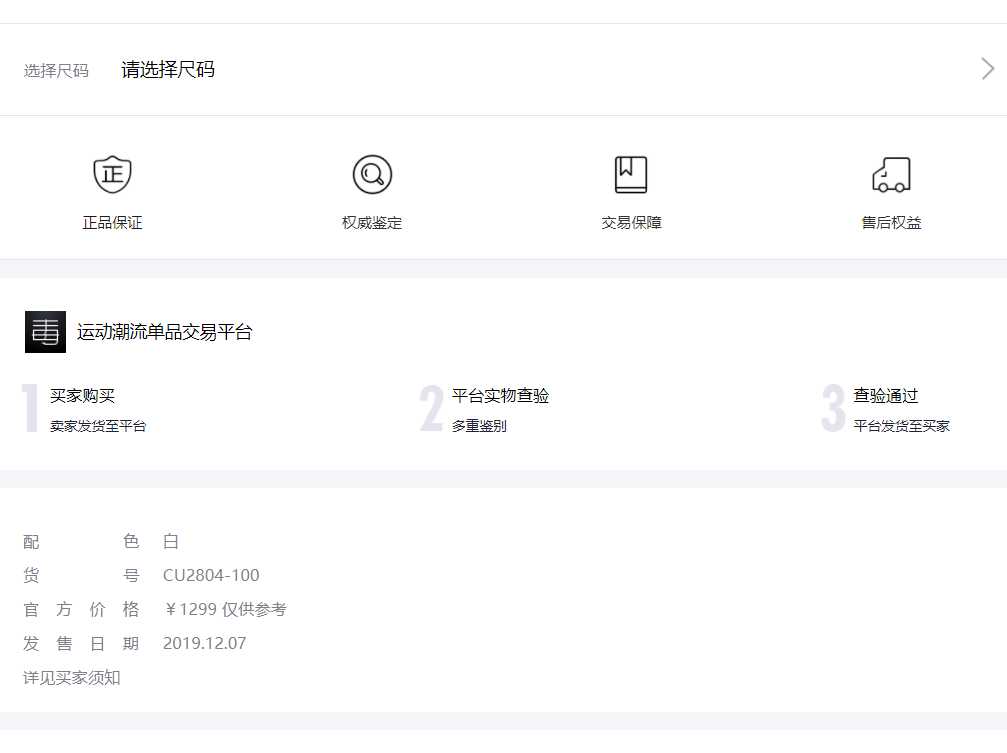
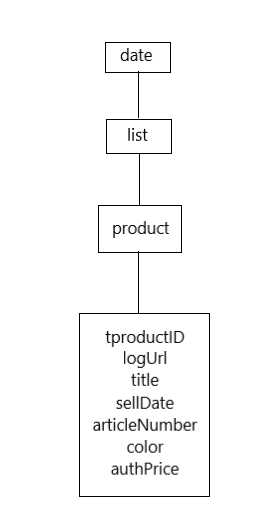
3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
# !/usr/bin/env python
# -*- encoding: utf-8 -*-
import execjs
import requests
import json
import re
import time
import datetime
import arrow
import os
import xlwt
import pymongo
class DuApp(object):
def __init__(self):
# 数据库
self.conn = pymongo.MongoClient(host=‘127.0.0.1‘, port=27017)
self.db = self.conn.Duapp
# 选择集合
self.collection = self.db.DuappPro
self.headers = {
‘Host‘: "app.poizon.com",
‘User-Agent‘: "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)"
" Chrome/53.0.2785.143 Safari/537.36 MicroMessenger/7.0.4.501 NetType/WIFI "
"MiniProgramEnv/Windows WindowsWechat",
‘appid‘: "wxapp",
‘appversion‘: "4.4.0",
‘content-type‘: "application/x-www-form-urlencoded",
‘Accept-Encoding‘: "gzip, deflate",
‘Accept‘: "*/*",
}
self.img_path = ‘image‘
def get_brand_list_url(self, lastId, tabId):
"""
构建商品品类列表
:param lastId: 起始页
:param tabId: 分类id
:return:
"""
with open(‘sign.js‘, ‘r‘, encoding=‘utf-8‘)as f:
all_ = f.read()
ctx = execjs.compile(all_)
sign = ctx.call(‘getSign‘,
‘lastId{}limit20tabId{}19bc545a393a25177083d4a748807cc0‘.format(lastId, tabId))
brand_list_url = ‘https://app.poizon.com/api/v1/h5/index/fire/shoppingTab?‘ ‘tabId={}&limit=20&lastId={}&sign={}‘.format(tabId, lastId, sign)
return brand_list_url
def get_product_detail_url(self, productId):
"""
构建商品详情url
:param productId: 商品id
:return:
"""
with open(‘sign.js‘, ‘r‘, encoding=‘utf-8‘)as f:
all_ = f.read()
ctx = execjs.compile(all_)
sign = ctx.call(‘getSign‘,
‘productId{}productSourceNamewx19bc545a393a25177083d4a748807cc0‘.format(productId))
product_detail_url = ‘https://app.poizon.com/api/v1/h5/index/fire/flow/product/detail?‘ ‘productId={}&productSourceName=wx&sign={}‘.format(productId, sign)
return product_detail_url
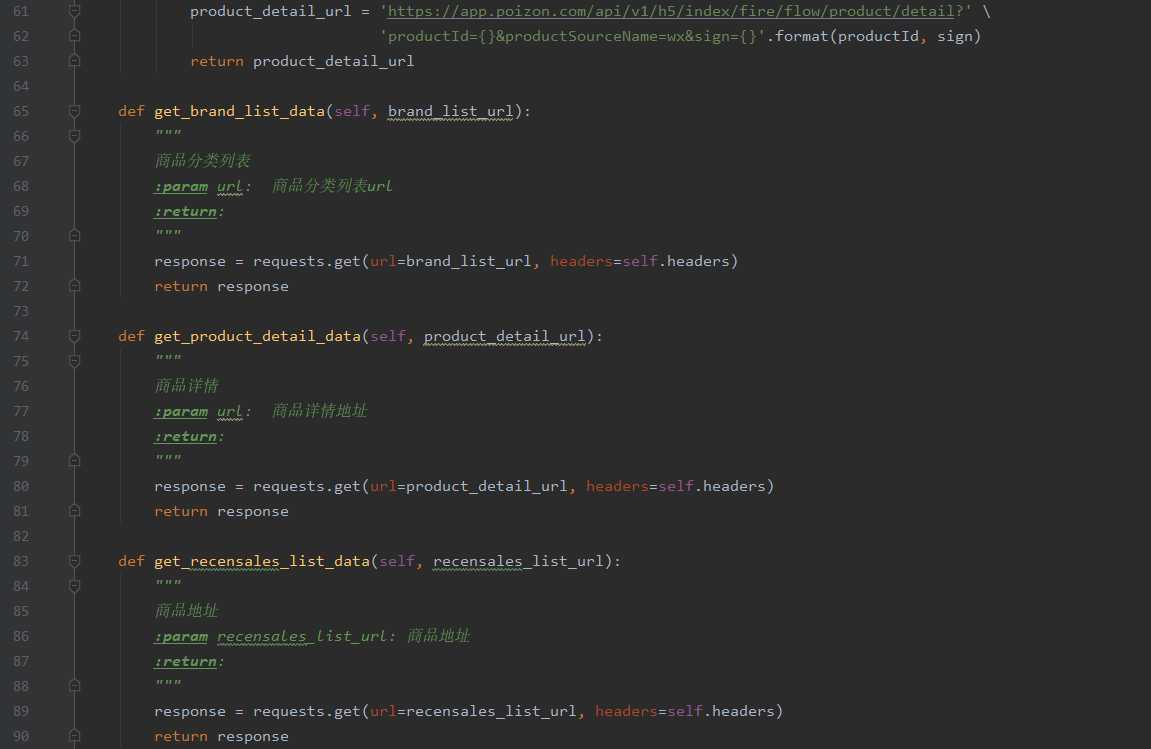
def get_brand_list_data(self, brand_list_url):
"""
商品分类列表
:param url: 商品分类列表url
:return:
"""
response = requests.get(url=brand_list_url, headers=self.headers)
return response
def get_product_detail_data(self, product_detail_url):
"""
商品详情
:param url: 商品详情地址
:return:
"""
response = requests.get(url=product_detail_url, headers=self.headers)
return response
def get_recensales_list_data(self, recensales_list_url):
"""
商品地址
:param recensales_list_url: 商品地址
:return:
"""
response = requests.get(url=recensales_list_url, headers=self.headers)
return response
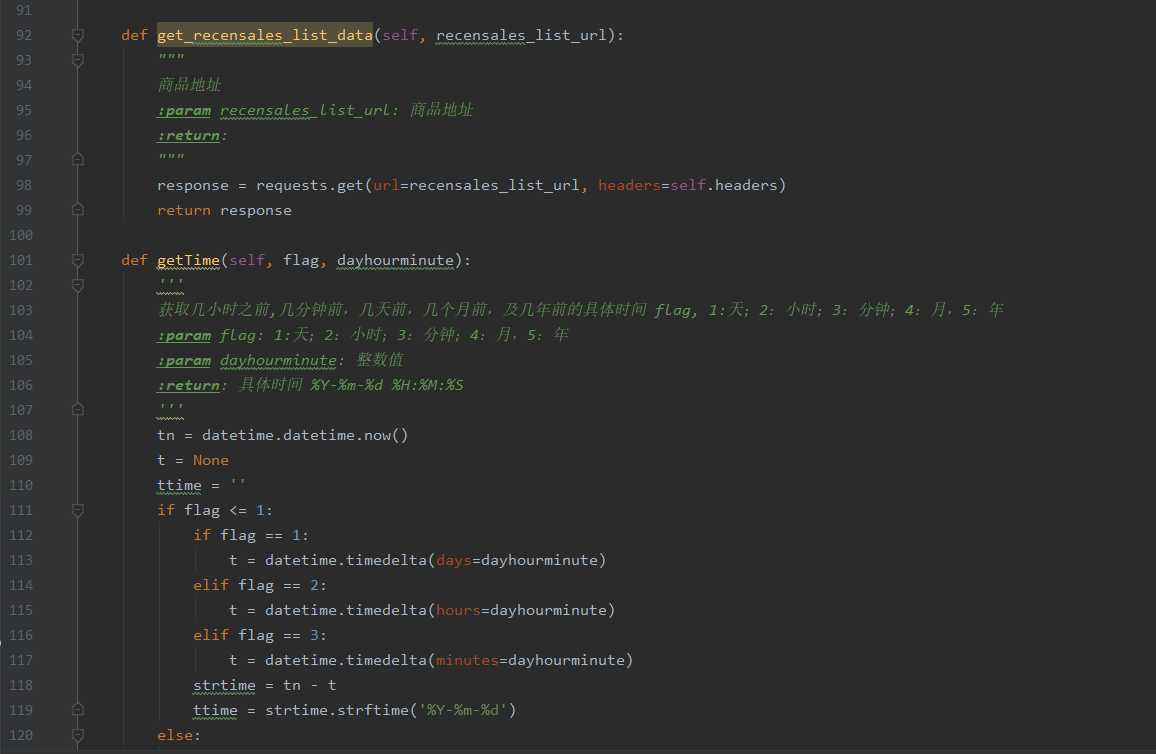
def get_recensales_list_data(self, recensales_list_url):
"""
商品地址
:param recensales_list_url: 商品地址
:return:
"""
response = requests.get(url=recensales_list_url, headers=self.headers)
return response
def getTime(self, flag, dayhourminute):
‘‘‘
获取几小时之前,几分钟前,几天前,几个月前,及几年前的具体时间 flag, 1:天;2:小时;3:分钟;4:月,5:年
:param flag: 1:天;2:小时;3:分钟;4:月,5:年
:param dayhourminute: 整数值
:return: 具体时间 %Y-%m-%d %H:%M:%S
‘‘‘
tn = datetime.datetime.now()
t = None
ttime = ‘‘
if flag <= 1:
if flag == 1:
t = datetime.timedelta(days=dayhourminute)
elif flag == 2:
t = datetime.timedelta(hours=dayhourminute)
elif flag == 3:
t = datetime.timedelta(minutes=dayhourminute)
strtime = tn - t
ttime = strtime.strftime(‘%Y-%m-%d‘)
else:
dt = arrow.now()
if flag == 4:
ttime = dt.shift(months=-dayhourminute).format("YYYY-MM-DD")
elif flag == 5:
ttime = str(int(
datetime.datetime.now().strftime(
"%Y")) - dayhourminute) + "-" + datetime.datetime.now().strftime(
"%m-%d")
return ttime
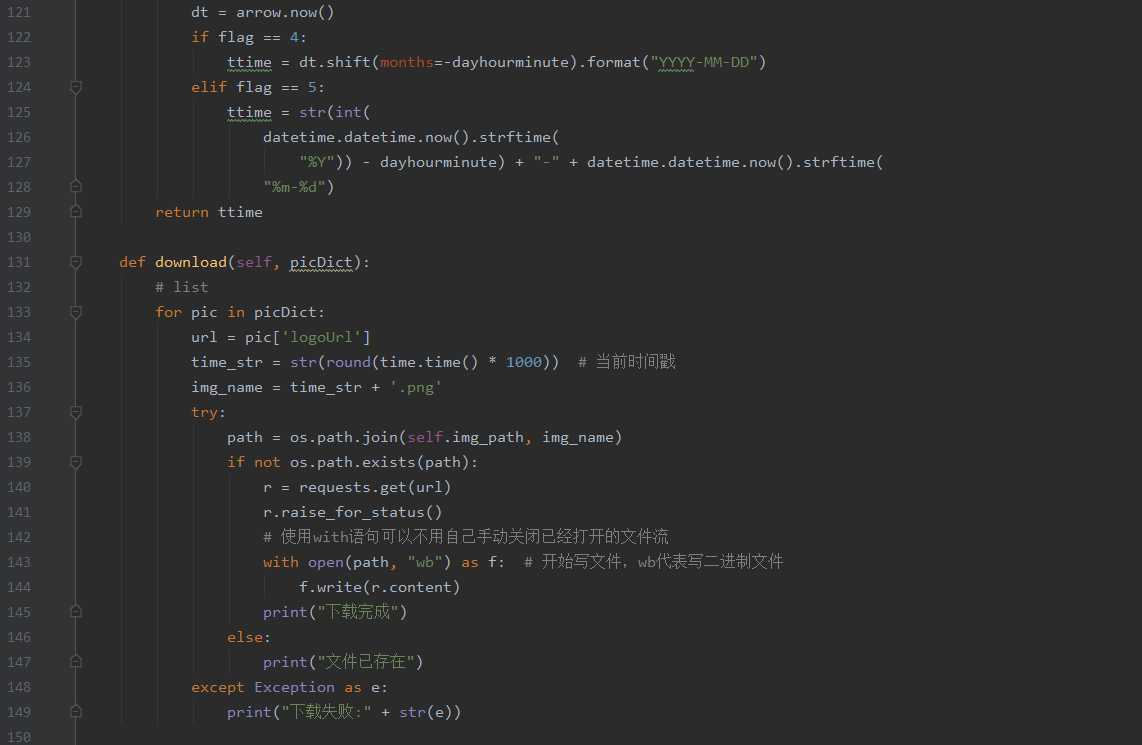
def download(self, picDict):
# list
for pic in picDict:
url = pic[‘logoUrl‘]
time_str = str(round(time.time() * 1000)) # 当前时间戳
img_name = time_str + ‘.png‘
try:
path = os.path.join(self.img_path, img_name)
if not os.path.exists(path):
r = requests.get(url)
r.raise_for_status()
# 使用with语句可以不用自己手动关闭已经打开的文件流
with open(path, "wb") as f: # 开始写文件,wb代表写二进制文件
f.write(r.content)
print("下载完成")
else:
print("文件已存在")
except Exception as e:
print("下载失败:" + str(e))
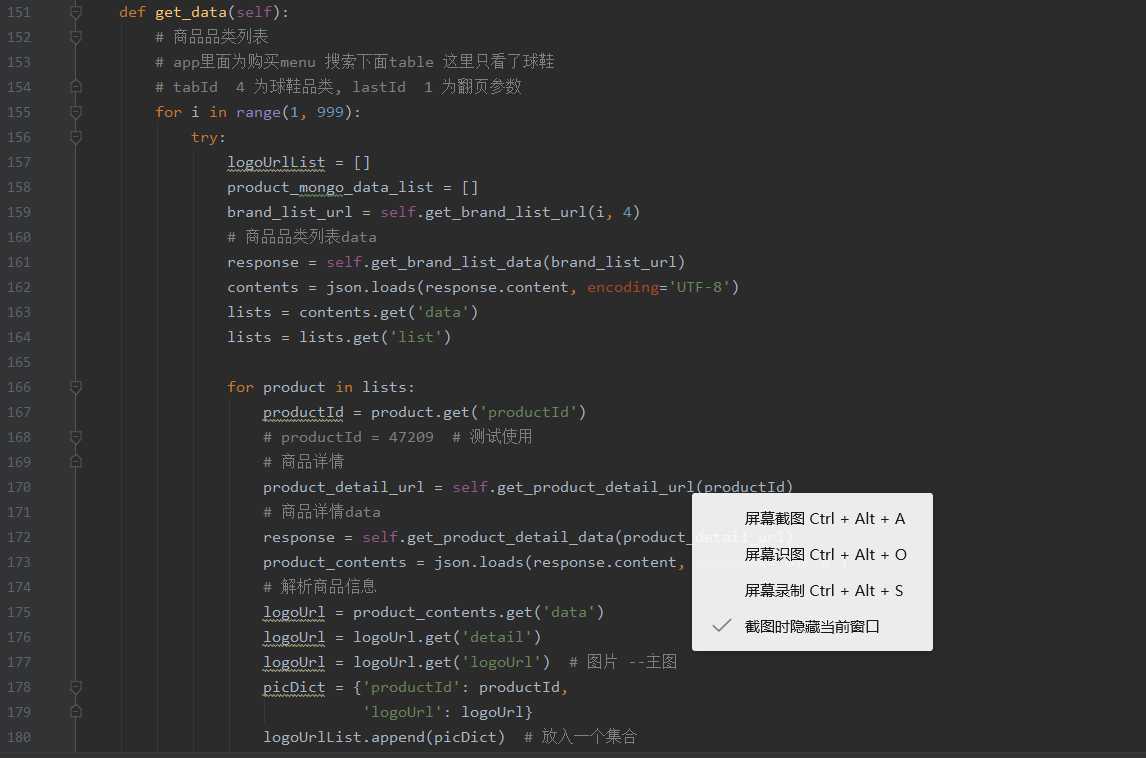
def get_data(self):
# 商品品类列表
# app里面为购买menu 搜索下面table 这里只看了球鞋
# tabId 4 为球鞋品类, lastId 1 为翻页参数
for i in range(1, 999):
try:
logoUrlList = []
product_mongo_data_list = []
brand_list_url = self.get_brand_list_url(i, 4)
# 商品品类列表data
response = self.get_brand_list_data(brand_list_url)
contents = json.loads(response.content, encoding=‘UTF-8‘)
lists = contents.get(‘data‘)
lists = lists.get(‘list‘)
for product in lists:
productId = product.get(‘productId‘)
# productId = 47209 # 测试使用
# 商品详情
product_detail_url = self.get_product_detail_url(productId)
# 商品详情data
response = self.get_product_detail_data(product_detail_url)
product_contents = json.loads(response.content, encoding=‘UTF-8‘)
# 解析商品信息
logoUrl = product_contents.get(‘data‘)
logoUrl = logoUrl.get(‘detail‘)
logoUrl = logoUrl.get(‘logoUrl‘) # 图片 --主图
picDict = {‘productId‘: productId,
‘logoUrl‘: logoUrl}
logoUrlList.append(picDict) # 放入一个集合
title = product_contents.get(‘data‘)
title = title.get(‘detail‘)
title = title.get(‘title‘) # 标题
sellDate = product_contents.get(‘data‘)
sellDate = sellDate.get(‘detail‘)
sellDate = sellDate.get(‘sellDate‘) # 发售日期
articleNumber = product_contents.get(‘data‘)
articleNumber = articleNumber.get(‘detail‘)
articleNumber = articleNumber.get(‘articleNumber‘) # 编号
color = product_contents.get(‘data‘)
color = color.get(‘detail‘)
color = color.get(‘color‘) # 颜色说明
authPrice = product_contents.get(‘data‘)
authPrice = authPrice.get(‘detail‘)
authPrice = authPrice.get(‘authPrice‘) # 价格
imageAndText = product_contents.get(‘data‘)
imageAndText = imageAndText.get(‘detail‘)
imageAndText = imageAndText.get(‘imageAndText‘) # 详情页
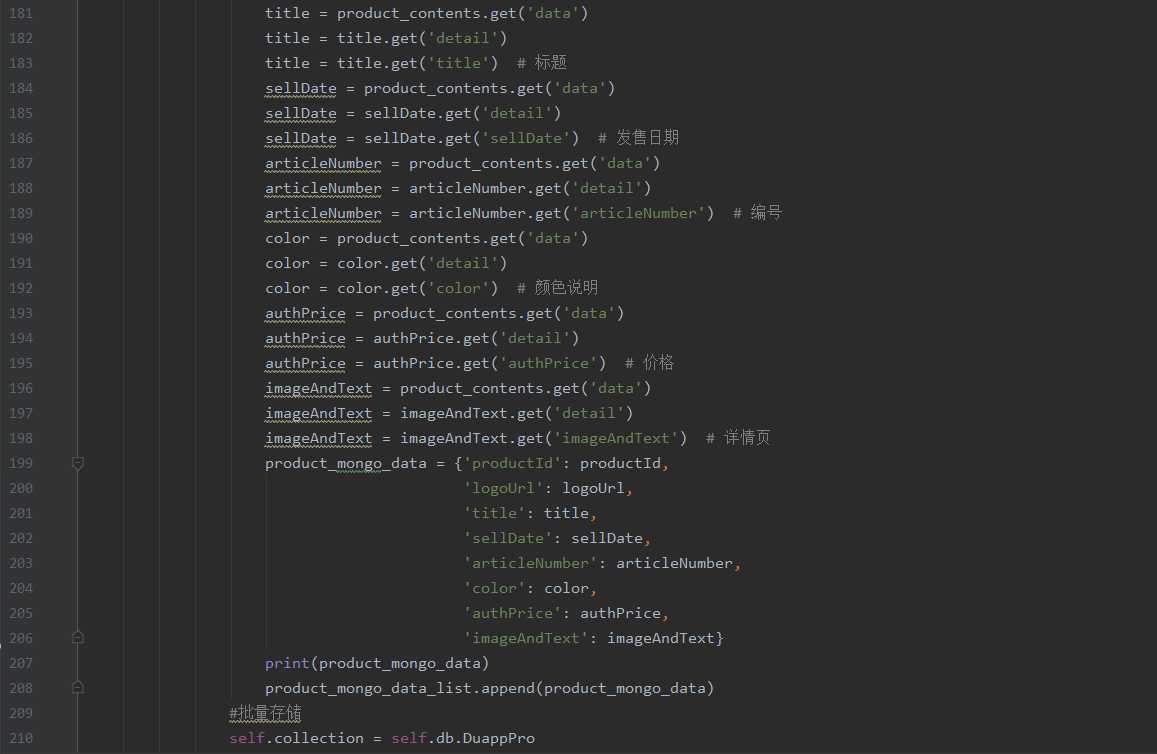
product_mongo_data = {‘productId‘: productId,
‘logoUrl‘: logoUrl,
‘title‘: title,
‘sellDate‘: sellDate,
‘articleNumber‘: articleNumber,
‘color‘: color,
‘authPrice‘: authPrice,
‘imageAndText‘: imageAndText}
print(product_mongo_data)
product_mongo_data_list.append(product_mongo_data)
#批量存储
self.collection = self.db.DuappPro
self.collection.insert_many(product_mongo_data_list)
# 购买数据
self.get_res(product_mongo_data)
except Exception as e:
print(e)
print("something error")
# 没有数据或者遇到异常,结束
break
def text_save(self, filename, data): # filename为写入CSV文件的路径,data为要写入数据列表.
file = open(filename, ‘w+‘, encoding=‘utf-8‘)
for i in range(len(data)):
s = str(data[i]).replace(‘[‘, ‘‘).replace(‘]‘, ‘‘) # 去除[],这两行按数据不同,可以选择
s = s.replace("‘", ‘‘).replace(‘,‘, ‘‘) + ‘\n‘ # 去除单引号,逗号,每行末尾追加换行符
file.write(s)
file.close()
print("保存文件成功")
# 将数据写入新文件
def data_write(self, file_path, datas):
f = xlwt.Workbook()
sheet1 = f.add_sheet(u‘sheet1‘, cell_overwrite_ok=True) # 创建sheet
# 将数据写入第 i 行,第 j 列
i = 0
for data in datas:
for j in range(len(data)):
sheet1.write(i, j, data[j])
i = i + 1
f.save(file_path) # 保存文件
def text_save(self,filename, data): # filename为写入CSV文件的路径,data为要写入数据列表.
file = open(filename, ‘w+‘,encoding=‘utf-8‘)
for i in range(len(data)):
s = str(data[i]).replace(‘[‘, ‘‘).replace(‘]‘, ‘‘) # 去除[],这两行按数据不同,可以选择
s = s.replace("‘", ‘‘).replace(‘,‘, ‘‘) + ‘\n‘ # 去除单引号,逗号,每行末尾追加换行符
file.write(s)
file.close()
print("保存文件成功")
# 将数据写入新文件
def data_write(self,file_path, datas):
f = xlwt.Workbook()
sheet1 = f.add_sheet(u‘sheet1‘, cell_overwrite_ok=True) # 创建sheet
# 将数据写入第 i 行,第 j 列
i = 0
for data in datas:
for j in range(len(data)):
sheet1.write(i, j, data[j])
i = i + 1
f.save(file_path) # 保存文件
if __name__ == ‘__main__‘:
duapp = DuApp()
duapp.get_data()
# duapp.text_save(‘duapp.txt‘,product_mongo_data_list)
# duapp.data_write(‘duapp.xlsx‘,product_mongo_data_list)
# res_mongo_data_list=duapp.get_res(product_mongo_data_list)
# 下载图片
# duapp.download(logoUrlList)
截图
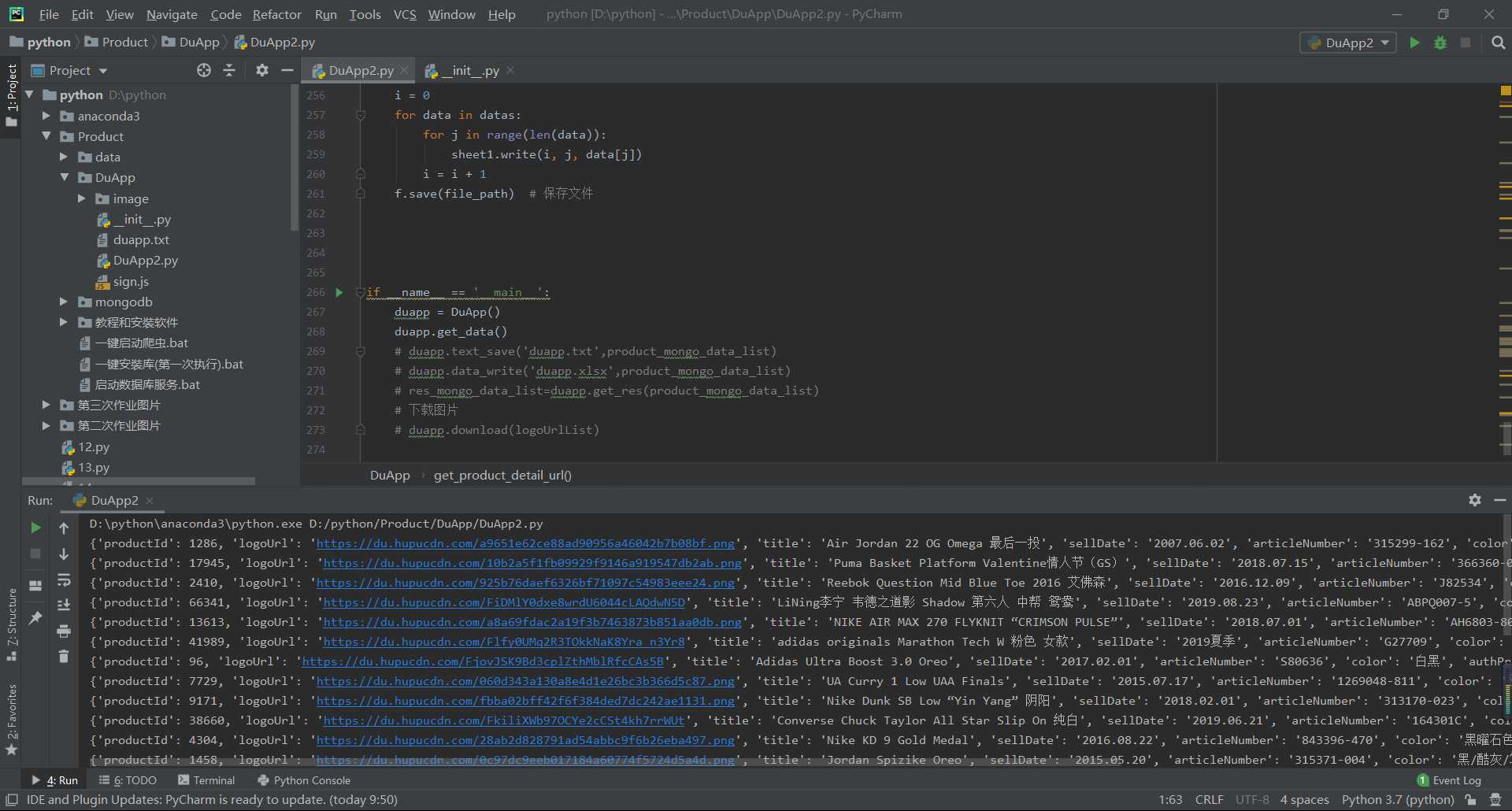
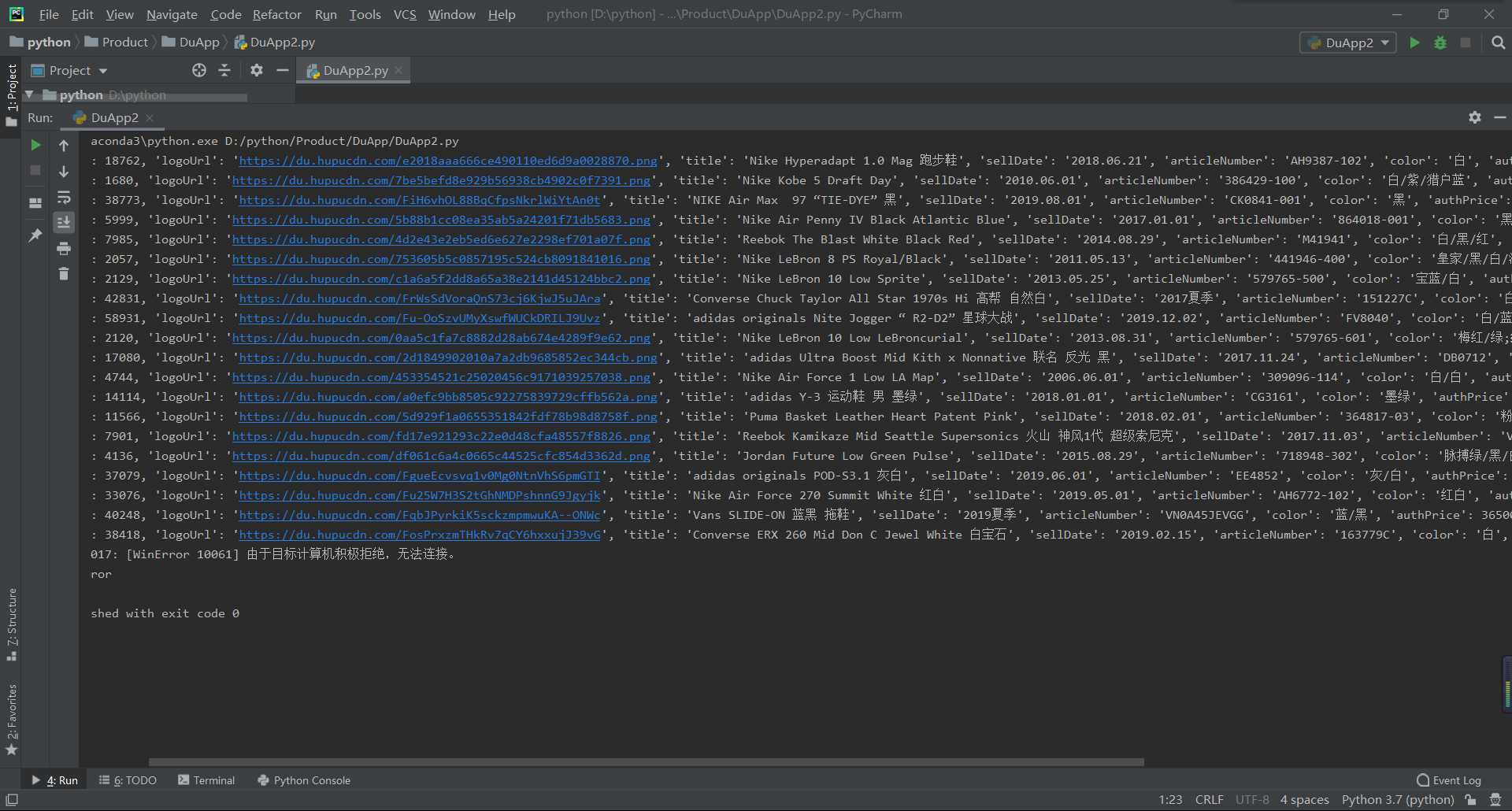
2.对数据进行清洗和处理
2.1对数据进行加载,导入本地数据文件
import pandas as pd df =pd.DataFrame(pd.read_csv(‘C:/Users/lenovo/Desktop/DuappPro.csv‘)) df.head()

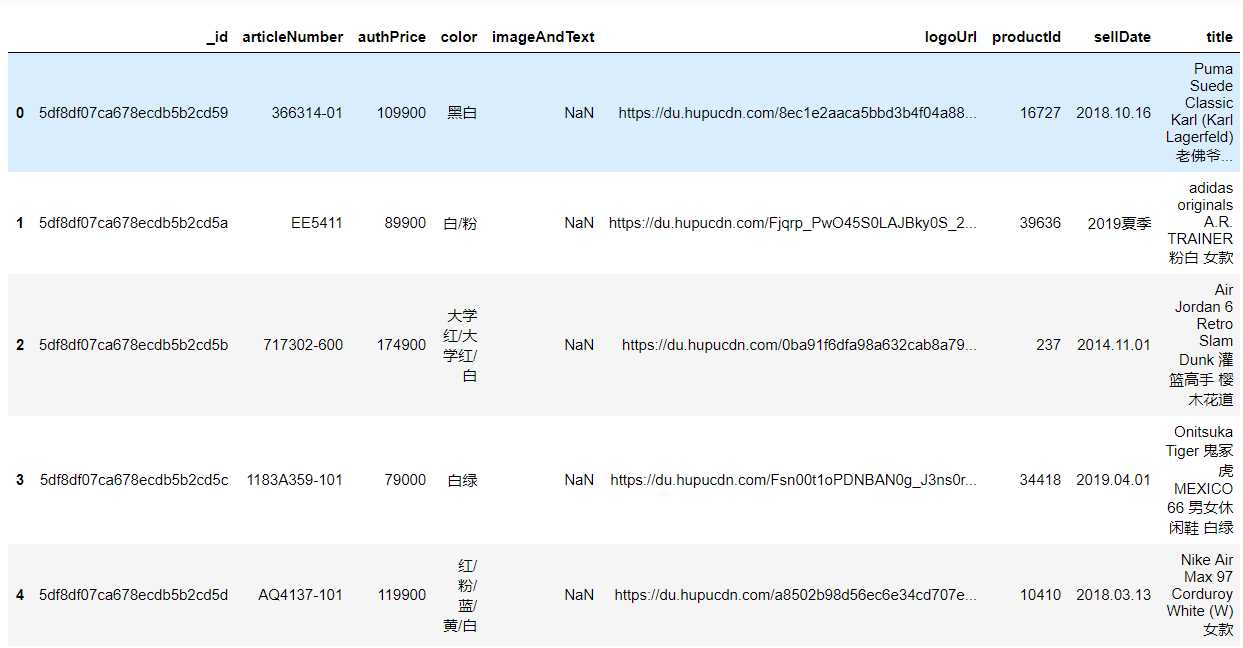
2.2删除无效的数据列
df.drop(‘logoUrl‘,axis=1,inplace=True) df.head()
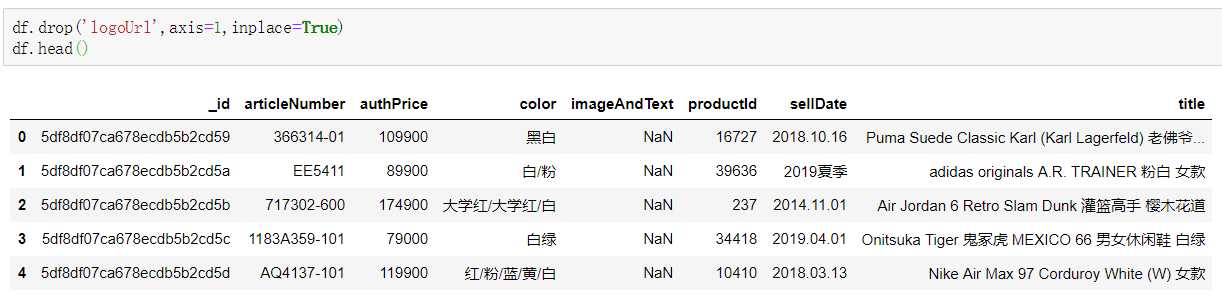
2.3对数据进行重复值处理
df.duplicated()


删除重复的数据值
df = df.drop_duplicates() df.head()
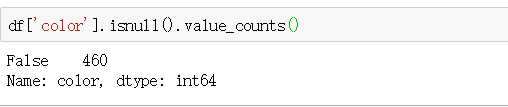
数据的空值与缺失值处理
df[‘color‘].isnull().value_counts()
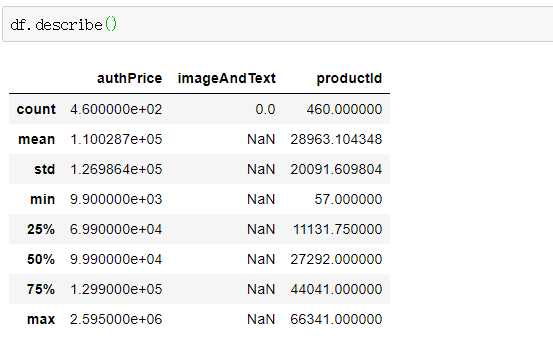
数据的异常值处理
df.describe()
3.文本分析(可选):jieba分词、wordcloud可视化
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
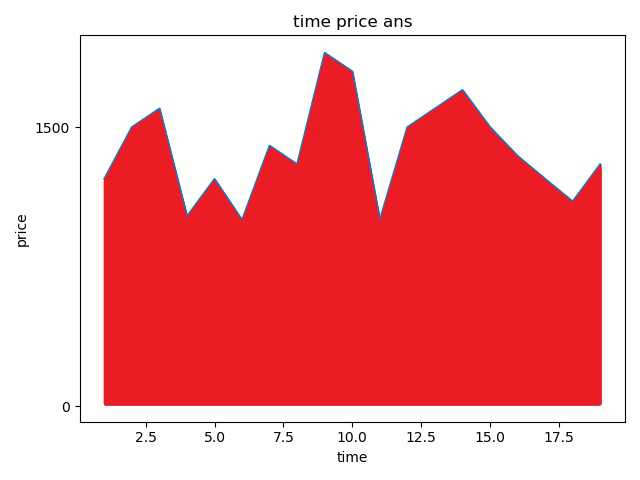
4.1查看adidas这几年的价格
def matplotlibAns(self): # matplotlib中有可用的模块,这里使用pyplot模块 data = self.collection.find({‘title‘: {‘$regex‘: ‘adidas‘}}) year = [2010, 2012, 2014, 2016] price = [20, 40, 60, 100] for du in data: time.append(du[‘sellDate‘]) price.append(du[‘authPrice‘]) #生成图表 pyplot.plot(year, price) #设置横坐标为time,纵坐标为price,标题为time price ans pyplot.xlabel(‘time‘) pyplot.ylabel(‘price‘) pyplot.title(‘time price ans‘) #设置纵坐标刻度 pyplot.yticks([0, 150000, 250000, 750000, 900000]) #设置填充选项:参数分别对应横坐标,纵坐标,纵坐标填充起始值,填充红色 pyplot.fill_between(time, price, 10, color = ‘red‘) #显示图表 pyplot.show()
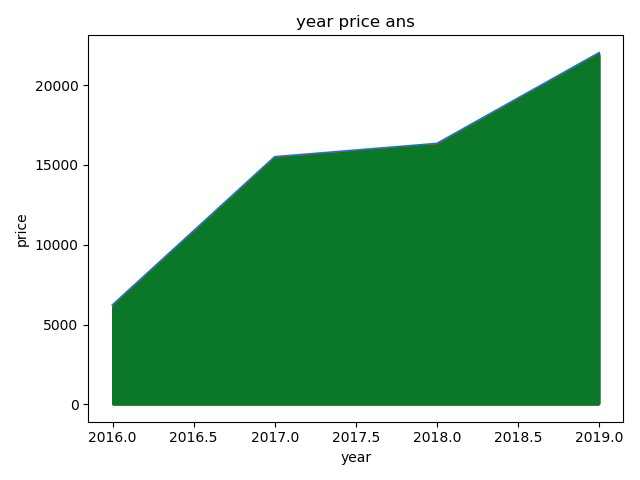
4. 查看毒App每年发布鞋子数量的走势
def matplotlibYear(self):
pipeline=[{$project:{year:{$substr:["$date",0,4]},"daily_count":1}},
{$group:{_id:"$year",year_count:{$sum:"$daily_count"}}}]
data=self.collection.aggregate(pipeline)
year = []
people = []
for x in data:
year.append(x[‘_id‘])
people.append(x[‘year_count‘])
# 生成图表
pyplot.plot(year, people)
# 设置横坐标为year,纵坐标为population,标题为Population year correspondence
pyplot.xlabel(‘year‘)
pyplot.ylabel(‘price‘)
pyplot.title(‘year price ans‘)
# 设置纵坐标刻度
pyplot.yticks([0, 5000, 10000, 15000, 20000, 25000, 30000])
# 设置填充选项:参数分别对应横坐标,纵坐标,纵坐标填充起始值,填充绿色
pyplot.fill_between(year, people, 10, color=‘red‘)
# 显示图表
pyplot.show()
5.数据持久化
6.附完整程序代码
# !/usr/bin/env python
# -*- encoding: utf-8 -*-
import execjs
import requests
import json
import re
import time
import datetime
import arrow
import os
import xlwt
import pymongo
class DuApp(object):
def __init__(self):
# 数据库
self.conn = pymongo.MongoClient(host=‘127.0.0.1‘, port=27017)
self.db = self.conn.Duapp
# 选择集合
self.collection = self.db.DuappPro
self.headers = {
‘Host‘: "app.poizon.com",
‘User-Agent‘: "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)"
" Chrome/53.0.2785.143 Safari/537.36 MicroMessenger/7.0.4.501 NetType/WIFI "
"MiniProgramEnv/Windows WindowsWechat",
‘appid‘: "wxapp",
‘appversion‘: "4.4.0",
‘content-type‘: "application/x-www-form-urlencoded",
‘Accept-Encoding‘: "gzip, deflate",
‘Accept‘: "*/*",
}
self.img_path = ‘image‘
def get_recensales_list_url(self, lastId, productId):
"""
构建最近购买记录url
:param lastId: 起始页
:param productId: 商品id
:return:
"""
with open(‘sign.js‘, ‘r‘, encoding=‘utf-8‘)as f:
all_ = f.read()
ctx = execjs.compile(all_)
sign = ctx.call(‘getSign‘,
‘lastId{}limit20productId{}sourceAppapp19bc545a393a25177083d4a748807cc0‘.format(
lastId,
productId))
recensales_list_url = ‘https://app.poizon.com/api/v1/h5/product/fire/recentSoldList?‘ ‘productId={}&lastId={}&limit=20&sourceApp=app&sign={}‘.format(productId,
lastId,
sign)
return recensales_list_url
def get_brand_list_url(self, lastId, tabId):
"""
构建商品品类列表
:param lastId: 起始页
:param tabId: 分类id
:return:
"""
with open(‘sign.js‘, ‘r‘, encoding=‘utf-8‘)as f:
all_ = f.read()
ctx = execjs.compile(all_)
sign = ctx.call(‘getSign‘,
‘lastId{}limit20tabId{}19bc545a393a25177083d4a748807cc0‘.format(lastId, tabId))
brand_list_url = ‘https://app.poizon.com/api/v1/h5/index/fire/shoppingTab?‘ ‘tabId={}&limit=20&lastId={}&sign={}‘.format(tabId, lastId, sign)
return brand_list_url
def get_product_detail_url(self, productId):
"""
构建商品详情url
:param productId: 商品id
:return:
"""
with open(‘sign.js‘, ‘r‘, encoding=‘utf-8‘)as f:
all_ = f.read()
ctx = execjs.compile(all_)
sign = ctx.call(‘getSign‘,
‘productId{}productSourceNamewx19bc545a393a25177083d4a748807cc0‘.format(productId))
product_detail_url = ‘https://app.poizon.com/api/v1/h5/index/fire/flow/product/detail?‘ ‘productId={}&productSourceName=wx&sign={}‘.format(productId, sign)
return product_detail_url
def get_brand_list_data(self, brand_list_url):
"""
商品分类列表
:param url: 商品分类列表url
:return:
"""
response = requests.get(url=brand_list_url, headers=self.headers)
return response
def get_product_detail_data(self, product_detail_url):
"""
商品详情
:param url: 商品详情地址
:return:
"""
response = requests.get(url=product_detail_url, headers=self.headers)
return response
def get_recensales_list_data(self, recensales_list_url):
"""
商品地址
:param recensales_list_url: 商品地址
:return:
"""
response = requests.get(url=recensales_list_url, headers=self.headers)
return response
def get_recensales_list_data(self, recensales_list_url):
"""
商品地址
:param recensales_list_url: 商品地址
:return:
"""
response = requests.get(url=recensales_list_url, headers=self.headers)
return response
def getTime(self, flag, dayhourminute):
‘‘‘
获取几小时之前,几分钟前,几天前,几个月前,及几年前的具体时间 flag, 1:天;2:小时;3:分钟;4:月,5:年
:param flag: 1:天;2:小时;3:分钟;4:月,5:年
:param dayhourminute: 整数值
:return: 具体时间 %Y-%m-%d %H:%M:%S
‘‘‘
tn = datetime.datetime.now()
t = None
ttime = ‘‘
if flag <= 1:
if flag == 1:
t = datetime.timedelta(days=dayhourminute)
elif flag == 2:
t = datetime.timedelta(hours=dayhourminute)
elif flag == 3:
t = datetime.timedelta(minutes=dayhourminute)
strtime = tn - t
ttime = strtime.strftime(‘%Y-%m-%d‘)
else:
dt = arrow.now()
if flag == 4:
ttime = dt.shift(months=-dayhourminute).format("YYYY-MM-DD")
elif flag == 5:
ttime = str(int(
datetime.datetime.now().strftime(
"%Y")) - dayhourminute) + "-" + datetime.datetime.now().strftime(
"%m-%d")
return ttime
def download(self, picDict):
# list
for pic in picDict:
url = pic[‘logoUrl‘]
time_str = str(round(time.time() * 1000)) # 当前时间戳
img_name = time_str + ‘.png‘
try:
path = os.path.join(self.img_path, img_name)
if not os.path.exists(path):
r = requests.get(url)
r.raise_for_status()
# 使用with语句可以不用自己手动关闭已经打开的文件流
with open(path, "wb") as f: # 开始写文件,wb代表写二进制文件
f.write(r.content)
print("下载完成")
else:
print("文件已存在")
except Exception as e:
print("下载失败:" + str(e))
def get_data(self):
# 商品品类列表
# app里面为购买menu 搜索下面table 这里只看了球鞋
# tabId 4 为球鞋品类, lastId 1 为翻页参数
for i in range(1, 999):
try:
logoUrlList = []
product_mongo_data_list = []
brand_list_url = self.get_brand_list_url(i, 4)
# 商品品类列表data
response = self.get_brand_list_data(brand_list_url)
contents = json.loads(response.content, encoding=‘UTF-8‘)
lists = contents.get(‘data‘)
lists = lists.get(‘list‘)
for product in lists:
productId = product.get(‘productId‘)
# productId = 47209 # 测试使用
# 商品详情
product_detail_url = self.get_product_detail_url(productId)
# 商品详情data
response = self.get_product_detail_data(product_detail_url)
product_contents = json.loads(response.content, encoding=‘UTF-8‘)
# 解析商品信息
logoUrl = product_contents.get(‘data‘)
logoUrl = logoUrl.get(‘detail‘)
logoUrl = logoUrl.get(‘logoUrl‘) # 图片 --主图
picDict = {‘productId‘: productId,
‘logoUrl‘: logoUrl}
logoUrlList.append(picDict) # 放入一个集合
title = product_contents.get(‘data‘)
title = title.get(‘detail‘)
title = title.get(‘title‘) # 标题
sellDate = product_contents.get(‘data‘)
sellDate = sellDate.get(‘detail‘)
sellDate = sellDate.get(‘sellDate‘) # 发售日期
articleNumber = product_contents.get(‘data‘)
articleNumber = articleNumber.get(‘detail‘)
articleNumber = articleNumber.get(‘articleNumber‘) # 编号
color = product_contents.get(‘data‘)
color = color.get(‘detail‘)
color = color.get(‘color‘) # 颜色说明
authPrice = product_contents.get(‘data‘)
authPrice = authPrice.get(‘detail‘)
authPrice = authPrice.get(‘authPrice‘) # 价格
imageAndText = product_contents.get(‘data‘)
imageAndText = imageAndText.get(‘detail‘)
imageAndText = imageAndText.get(‘imageAndText‘) # 详情页
product_mongo_data = {‘productId‘: productId,
‘logoUrl‘: logoUrl,
‘title‘: title,
‘sellDate‘: sellDate,
‘articleNumber‘: articleNumber,
‘color‘: color,
‘authPrice‘: authPrice,
‘imageAndText‘: imageAndText}
print(product_mongo_data)
product_mongo_data_list.append(product_mongo_data)
#批量存储
self.collection = self.db.DuappPro
self.collection.insert_many(product_mongo_data_list)
# 购买数据
self.get_res(product_mongo_data)
except Exception as e:
print(e)
print("something error")
# 没有数据或者遇到异常,结束
break
def text_save(self, filename, data): # filename为写入CSV文件的路径,data为要写入数据列表.
file = open(filename, ‘w+‘, encoding=‘utf-8‘)
for i in range(len(data)):
s = str(data[i]).replace(‘[‘, ‘‘).replace(‘]‘, ‘‘) # 去除[],这两行按数据不同,可以选择
s = s.replace("‘", ‘‘).replace(‘,‘, ‘‘) + ‘\n‘ # 去除单引号,逗号,每行末尾追加换行符
file.write(s)
file.close()
print("保存文件成功")
# 将数据写入新文件
def data_write(self, file_path, datas):
f = xlwt.Workbook()
sheet1 = f.add_sheet(u‘sheet1‘, cell_overwrite_ok=True) # 创建sheet
# 将数据写入第 i 行,第 j 列
i = 0
for data in datas:
for j in range(len(data)):
sheet1.write(i, j, data[j])
i = i + 1
f.save(file_path) # 保存文件
def get_res(self,list):
product_mongo_data_list=[]
for d in list:
for a in d:
productId=a[‘productId‘]
# 最近购买
recensales_list_url = self.get_recensales_list_url(0, productId)
# 最近购买data
response = self.get_recensales_list_data(recensales_list_url)
recensales_contents = json.loads(response.content, encoding=‘UTF-8‘)
lists = recensales_contents.get(‘data‘)
lists = lists.get(‘list‘)
for ecensales in lists:
avatar = ecensales.get(‘avatar‘)
userName = ecensales.get(‘userName‘)
sizeDesc = ecensales.get(‘sizeDesc‘)
formatTime = ecensales.get(‘formatTime‘)
# 处理时间
realTime = ‘‘
try:
if ‘刚刚‘ in formatTime:
tn = datetime.datetime.now()
realTime = tn.strftime(‘%Y-%m-%d %H:%M:%S‘)
elif ‘分钟‘ in formatTime:
formatTime = formatTime.replace(‘分钟前‘, ‘‘) # 替换 转换为购买时间,当前时间减formatTime
realTime = self.getTime(3, int(formatTime))
elif ‘小时前‘ in formatTime:
formatTime = formatTime.replace(‘小时前‘, ‘‘) # 替换 转换为购买时间,当前时间减formatTime
realTime = self.getTime(2, int(formatTime))
elif ‘天前‘ in formatTime:
formatTime = formatTime.replace(‘天前‘, ‘‘) # 替换 转换为购买时间,当前时间减formatTime
realTime = self.getTime(1, int(formatTime))
elif ‘月‘ in formatTime and ‘日‘ in formatTime and ‘年‘ not in formatTime:
# 在前面拼接当前年份 如:2019年
formatTime = str(datetime.datetime.now().year) + ‘年‘ + formatTime
realTime = datetime.datetime.strptime(formatTime, ‘%Y-%m-%d‘)
elif ‘年‘ in formatTime and ‘月‘ in formatTime and ‘日‘ in formatTime:
realTime = datetime.datetime.strptime(formatTime, ‘%Y-%m-%d‘)
else:
# 不符合上面的格式,就默認為當前日期
tn = datetime.datetime.now()
realTime = tn.strftime(‘%Y-%m-%d %H:%M:%S‘)
except:
tn = datetime.datetime.now()
realTime = tn.strftime(‘%Y-%m-%d %H:%M:%S‘)
price = ecensales.get(‘price‘)
ecensale_mongo_data = {‘productId‘: productId,
‘avatar‘: avatar,
‘userName‘: userName,
‘sizeDesc‘: sizeDesc,
‘formatTime‘: realTime,
‘price‘: price}
print(ecensale_mongo_data)
product_mongo_data_list.append(ecensale_mongo_data)
self.collection = self.db.DuappRes
#批量存储
self.collection.insert_many(product_mongo_data_list)
return product_mongo_data_list
def text_save(self,filename, data): # filename为写入CSV文件的路径,data为要写入数据列表.
file = open(filename, ‘w+‘,encoding=‘utf-8‘)
for i in range(len(data)):
s = str(data[i]).replace(‘[‘, ‘‘).replace(‘]‘, ‘‘) # 去除[],这两行按数据不同,可以选择
s = s.replace("‘", ‘‘).replace(‘,‘, ‘‘) + ‘\n‘ # 去除单引号,逗号,每行末尾追加换行符
file.write(s)
file.close()
print("保存文件成功")
# 将数据写入新文件
def data_write(self,file_path, datas):
f = xlwt.Workbook()
sheet1 = f.add_sheet(u‘sheet1‘, cell_overwrite_ok=True) # 创建sheet
# 将数据写入第 i 行,第 j 列
i = 0
for data in datas:
for j in range(len(data)):
sheet1.write(i, j, data[j])
i = i + 1
f.save(file_path) # 保存文件
if __name__ == ‘__main__‘:
duapp = DuApp()
duapp.get_data()
# duapp.text_save(‘duapp.txt‘,product_mongo_data_list)
# duapp.data_write(‘duapp.xlsx‘,product_mongo_data_list)
# res_mongo_data_list=duapp.get_res(product_mongo_data_list)
# 下载图片
# duapp.download(logoUrlList)
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
答:(1)Nike品牌鞋子的销量有明显的季节性差异,6、7月的时候销量都是该年最低,年末的时候都是最高,Nike销量最高的一年是10年的时候
(2)消费者对鞋购买热情有增无减,一年比一年高,但17年这年增涨速度最慢,17到18年增涨速度最快。
2.对本次程序设计任务完成的情况做一个简单的小结。
答::学习爬虫真的不是轻松的事,得循序渐进,一步一步慢慢来。要创建回送地址,还要连接操作,pip install PyExecjs这串代码也不能忘了;爬取信息自然要连接网页的数据库,这里就要学会用创建选择集合self.collection,要连接的地址host,user—Agent:使服务器可以识别用户使用的操作系统及版本、浏览器、CPU等。爬取到信息后要返回appversion。对我难度最大的还是各种信息的收集,每次解析网站,都要按F12开发者按钮这个按键,这样就能定位到所需要的信息。还有就是如何用代码获取到前面找到的那个标签,首先你观察你要找到的标签,是什么标签,是否有 c id 这样的属性,因为 id 这个属性作为筛选条件的话,查找到的干扰项极少,运气好的话,基本上可以一击必中,解决了我很多麻烦。
标签:otl pap plot gzip 价格 try 结束 简单的 cts
原文地址:https://www.cnblogs.com/chenjunfan/p/12070640.html