标签:fetch none port commit rank int mic sub odi
Python高级应用程序设计任务要求
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
穷游网香港旅游攻略中的景点爬取
2.主题式网络爬虫爬取的内容与数据特征分析
内容:主要爬取穷游网香港旅游攻略景点排名前100的旅游景点的信息,以及对应的景点评论信息。
数据特征分析:对所有的评论做了词云、对景点的评分做了可视化和柱状图
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
实现思路:首先通过分析此网站得知数据的传输通过ajax实现,其中景点信息固定url为“https://place.qyer.com/poi.php?action=list_json”,通过修改data参数实现翻页。创建一个ScenicInfo 类定义param_info和insert实现对数据的抓取和保存。景点评论信息是通过url拼接来实现,创建一个Comments类定义param_comments发起请求获得json数据,insert方法插入数据库
技术难点:在爬取过程中没有出现反爬。
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
每页15项数据,爬取了64页,一共960项数据。通过chrome抓包调试发现所有得数据都是通过ajax动态发送只需修改post参数几个。
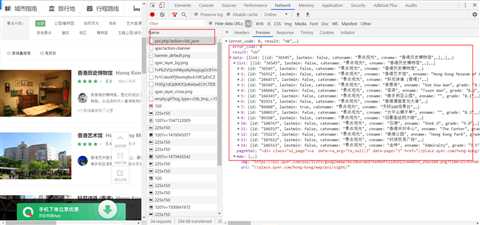
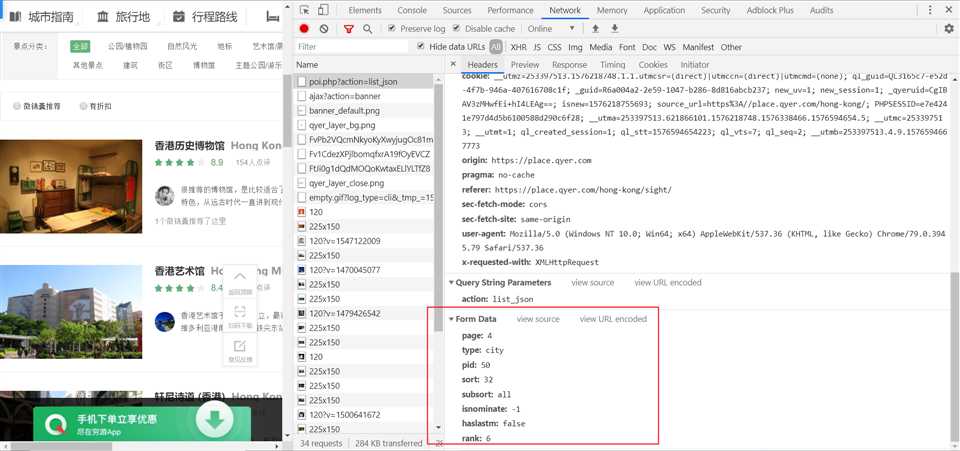
2.Htmls页面解析
红框中的数据为爬取字段
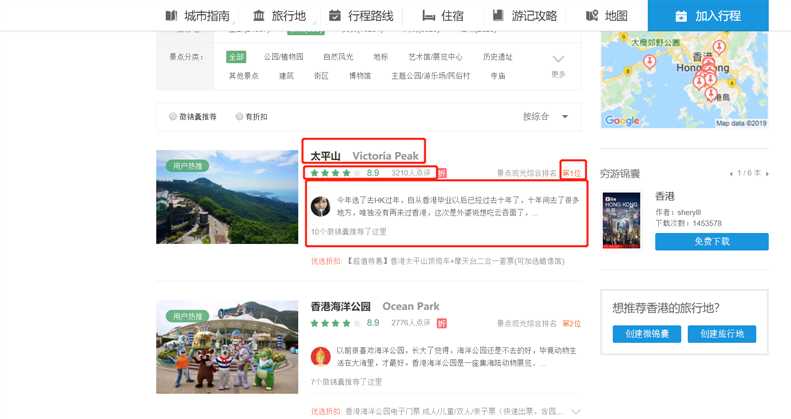
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
1、景点信息的采集与爬取
1 # 景点信息的采集与爬取 2 import pymysql 3 import requests 4 5 # 定义类名和设置默认参数 6 class ScenicInfo(object): 7 def __init__(self): 8 # 要获取的url 9 self.url = ‘https://place.qyer.com/poi.php?action=list_json‘ 10 # 设置请求头 11 self.headers = { 12 ‘user-agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36‘, 13 ‘referer‘: ‘https://place.qyer.com/hong-kong/sight/‘ 14 } 15 # 对数据进行清洗和处理 16 def param_info(self, form_data): 17 # 通过request发起请求 18 resp = requests.post(self.url, form_data, headers=self.headers) 19 # 获得返回json数据解析 20 data = resp.json()[‘data‘][‘list‘] 21 # 遍历返回的数据,将数据插入数据库 22 for index in data: 23 print(index[‘id‘], index[‘cnname‘], index[‘rank‘], index[‘grade‘], index[‘url‘], index[‘commentCount‘]) 24 # 执行操作数据库的方法 25 self.insert(index[‘id‘], index[‘cnname‘], index[‘rank‘], index[‘grade‘], index[‘url‘], 26 index[‘commentCount‘]) 27 28 def run(self): 29 # 通过遍历来改变post的参数,来实现翻页 30 for page in range(1, 65): 31 print(‘当前正在采集第%s页!‘ % str(page)) 32 form_data = { 33 ‘page‘: page, 34 ‘type‘: ‘city‘, 35 ‘pid‘: ‘50‘, 36 ‘sort‘: ‘32‘, 37 ‘subsort‘: ‘all‘, 38 ‘isnominate‘: ‘-1‘, 39 ‘haslastm‘: ‘false‘, 40 ‘rank‘: ‘6‘, 41 } 42 # 将带着参数传入这个方法,然后发起请求 43 self.param_info(form_data) 44 # 数据持久化 45 def insert(*details): 46 # 连接数据库 47 db = pymysql.connect("localhost", "root", "root", "honk") 48 # 获得游标 49 cursor = db.cursor() 50 # 设置sql语句 51 sql = "insert into scenic (cid,name,rank,grade,url,comment_count)value(%s,%s,%s,%s,%s,%s)" 52 # 执行sql语句 53 try: 54 cursor.execute(sql, details) 55 db.commit() 56 print(‘插入数据成功‘) 57 except Exception as e: 58 db.rollback() 59 print("插入数据失败", e) 60 db.close() 61 62 if __name__ == ‘__main__‘: 63 scenicInfo = ScenicInfo() 64 scenicInfo.run()
2、景点评论信息的采集与爬取
1 # 景点评论的采集和爬取 2 import re 3 4 import redis 5 import requests 6 7 import pymysql 8 from redis import StrictRedis 9 10 # 定义类名和设置默认参数 11 class Comments(object): 12 def __init__(self): 13 self.r = StrictRedis(host=‘localhost‘, port=6379, db=0, decode_responses=True) 14 # 设置请求头 15 self.headers = { 16 ‘user-agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36‘ 17 } 18 # 获取评论信息 19 def param_comments(self, code): 20 page = 1 21 # 要获取的url 22 url = ‘https://place.qyer.com/poi.php?action=comment&page={}&order=5&poiid={}&starLevel=all‘.format(page, code) 23 print(url) 24 # 通过request发起请求 25 resp = requests.post(url, headers=self.headers) 26 # 获得返回json数据分析 27 data = resp.json()[‘data‘][‘lists‘] 28 # 判断数据是否为空 29 if len(data) != 0: 30 # 通过正则匹配的title 31 try: 32 total = resp.json()[‘data‘][‘pagehtml‘] 33 total_page = re.findall(‘title="(.*?)"‘, total)[0].replace(‘...‘, ‘‘) 34 35 except Exception as e: 36 total_page = 1 37 38 print(‘当前总页数:%s‘ % total_page) 39 # 判断有多少页,若返回的信息是下一页就设置为1,否则就用抓取到的页数 40 if total_page == ‘下一页‘: 41 total_page = 1 42 for page in range(1, int(total_page) + 1): 43 print("当前总共%s页,正在采集第%s页!" % (total_page, page)) 44 # 对数据进行清洗和处理 45 url = ‘https://place.qyer.com/poi.php?action=comment&page={}&order=5&poiid={}&starLevel=all‘.format( 46 page, 47 code) 48 # 通过request发起请求 49 resp = requests.post(url, headers=self.headers) 50 # 获得返回json数据分析 51 data = resp.json()[‘data‘][‘lists‘] 52 # 遍历返回的数据,将数据插入数据库 53 for index in data: 54 name = index[‘userinfo‘][‘name‘] 55 starlevel = index[‘starlevel‘] 56 content = index[‘content‘] 57 date = index[‘date‘] 58 print(code, name, starlevel, content, date) 59 # 将带着参数传入这个方法,然后发起请求 60 self.insert(code, name, starlevel, content, date) 61 # 数据持久化 62 def insert(self, *details): 63 # 连接数据库 64 db = pymysql.connect("localhost", "root", "root", "honk") 65 # 获得游标 66 cursor = db.cursor() 67 # 设置sql语句 68 sql = "insert into comments (sid,name,starlevel,content,date)value(%s,%s,%s,%s,%s)" 69 # 执行sql语句 70 try: 71 cursor.execute(sql, details) 72 db.commit() 73 print(‘插入数据成功‘) 74 except Exception as e: 75 db.rollback() 76 print("插入数据失败", e) 77 db.close() 78 # 设置死循环,从缓存里面拿到景点的code然后拼接成url 79 def run(self): 80 while True: 81 code = self.r.lpop(‘h_code‘) 82 83 if code is None: 84 print("当前url请求结束!") 85 break 86 87 self.param_comments(code) 88 89 90 if __name__ == ‘__main__‘: 91 comments = Comments() 92 comments.run()
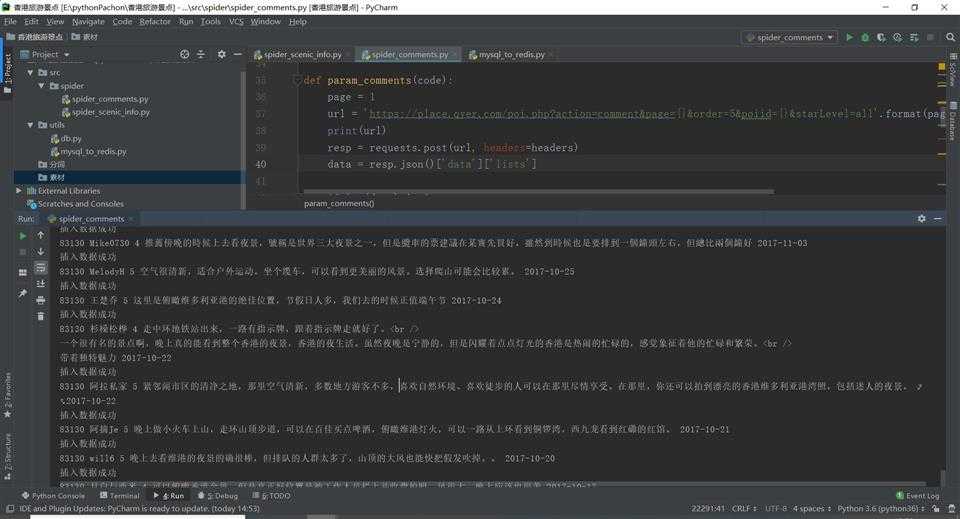
2.对数据进行清洗和处理
1、对景点信息数据进行清洗和处理
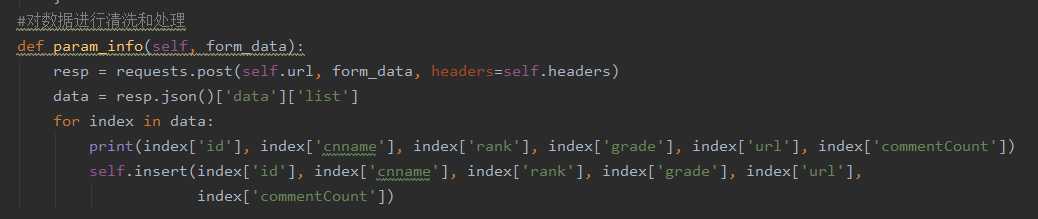
2、对景点评论数据进行清洗和处理
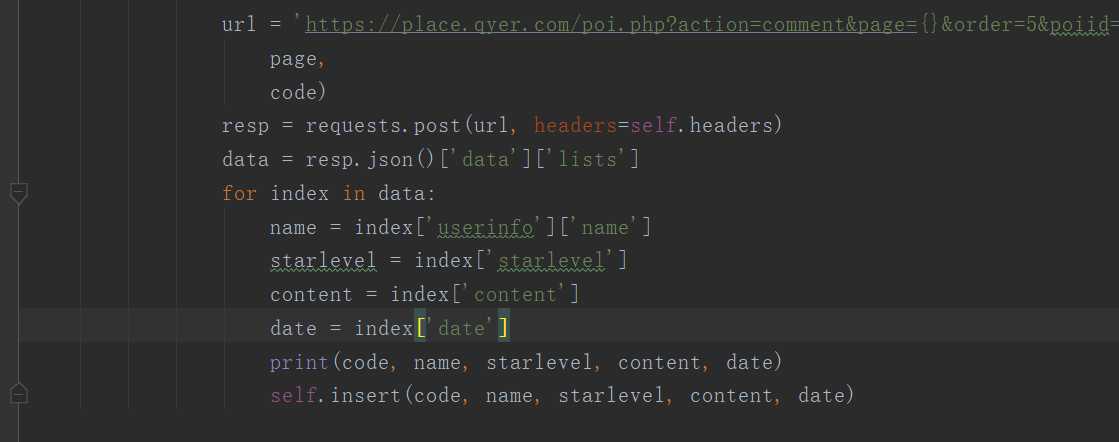
3.文本分析(可选):jieba分词、wordcloud可视化
1 from wordcloud import WordCloud 2 import matplotlib.pyplot as plt 3 import jieba 4 5 # 生成词云 6 def create_word_cloud(filename): 7 text = open("{}.txt".format(filename), encoding=‘utf-8‘).read() 8 # 结巴分词 9 wordlist = jieba.cut(text, cut_all=True) 10 wl = " ".join(wordlist) 11 12 # 设置词云 13 wc = WordCloud( 14 # 设置背景颜色 15 background_color="white", 16 # 设置最大显示的词云数 17 max_words=2000, 18 # 这种字体都在电脑字体中,一般路径 19 font_path=‘C:\Windows\Fonts\simfang.ttf‘, 20 height=1200, 21 width=1600, 22 # 设置字体最大值 23 max_font_size=100, 24 # 设置有多少种随机生成状态,即有多少种配色方案 25 random_state=30, 26 ) 27 28 myword = wc.generate(wl) # 生成词云 29 # 展示词云图 30 plt.imshow(myword) 31 plt.axis("off") 32 plt.show() 33 wc.to_file(‘comments.png‘) # 把词云保存下来 34 35 if __name__ == ‘__main__‘: 36 create_word_cloud(‘comments‘)

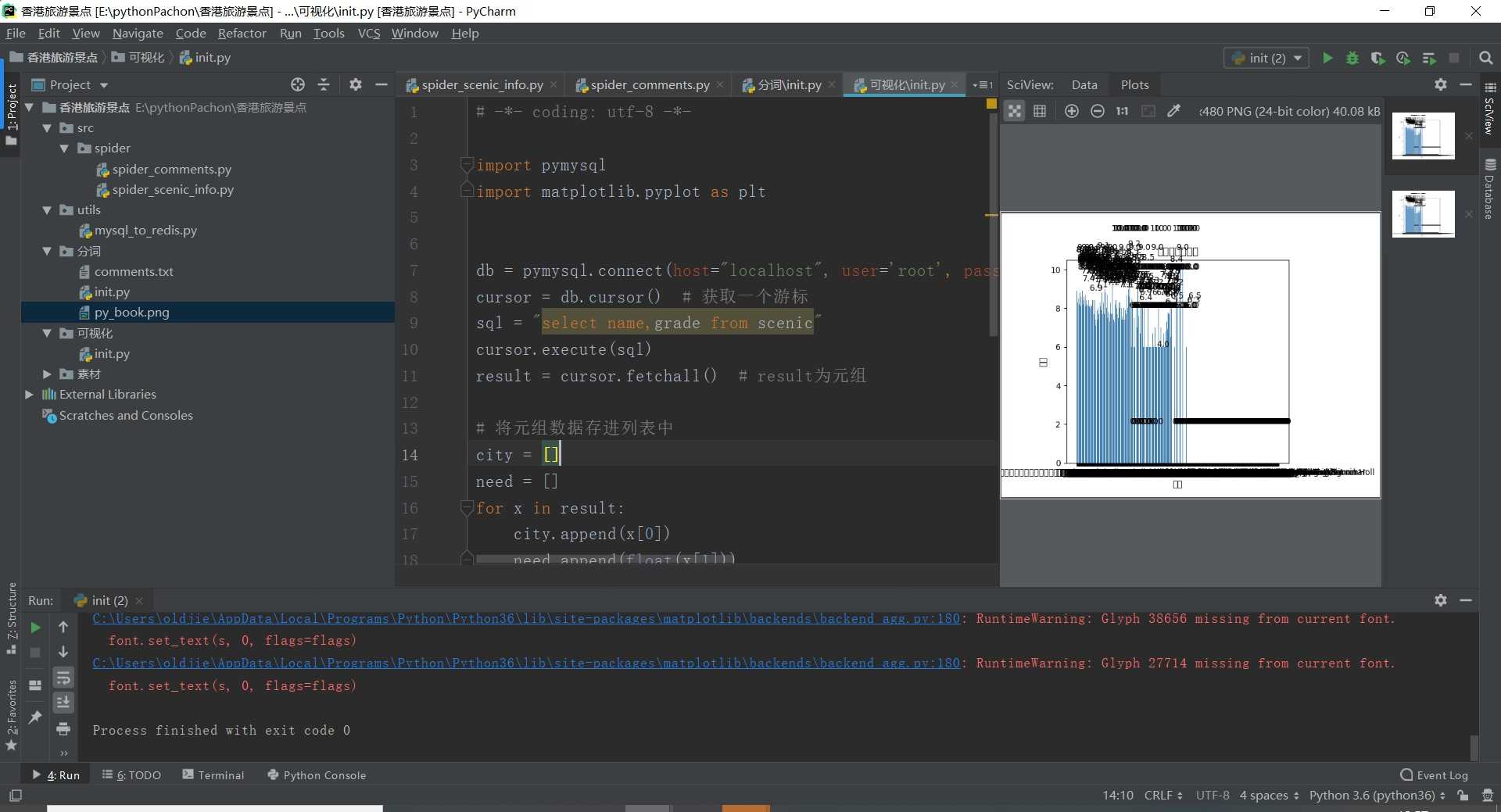
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
1 import pymysql 2 import matplotlib.pyplot as plt 3 4 db = pymysql.connect(host="localhost", user=‘root‘, passwd="root", port=3306, db="honk", charset=‘utf8‘) 5 cursor = db.cursor() # 获取一个游标 6 sql = "select name,grade from scenic" 7 cursor.execute(sql) 8 result = cursor.fetchall() # result为元组 9 10 # 将元组数据存进列表中 11 city = [] 12 need = [] 13 for x in result: 14 city.append(x[0]) 15 need.append(float(x[1])) 16 17 # 直方图 18 plt.bar(range(len(need)), need, color=‘steelblue‘, tick_label=city) 19 plt.xlabel("景点") 20 plt.ylabel("评分") 21 plt.title("城市职位需求图") 22 for x, y in enumerate(need): 23 plt.text(x - 2, y + 2, ‘%s‘ % y) 24 plt.show() 25 cursor.close() # 关闭游标 26 db.close() # 关闭数据库
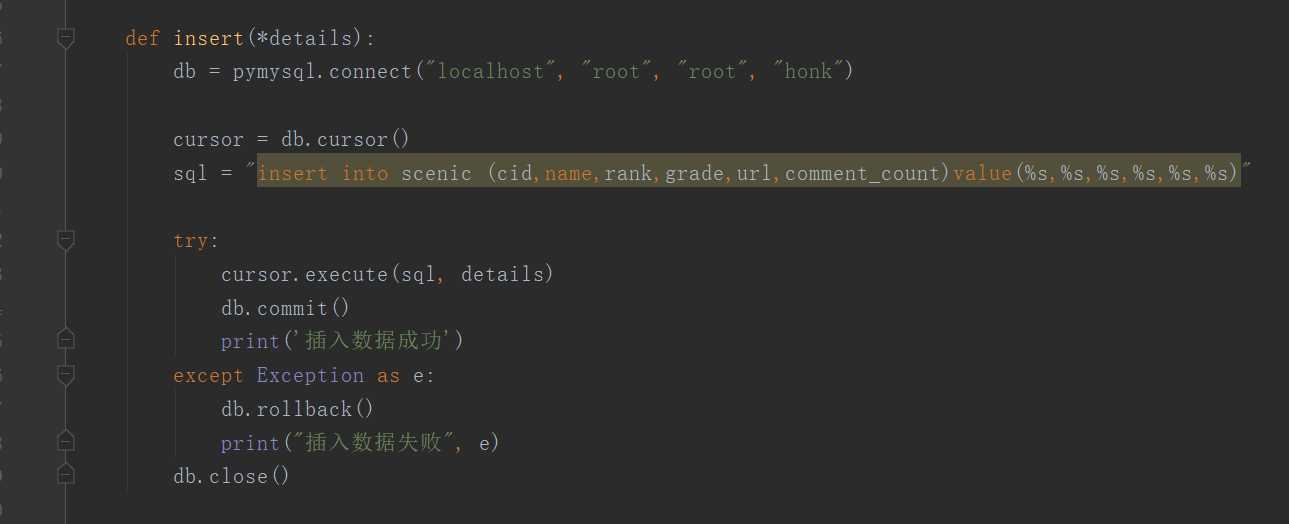
5.数据持久化
1、景点信息数据持久化
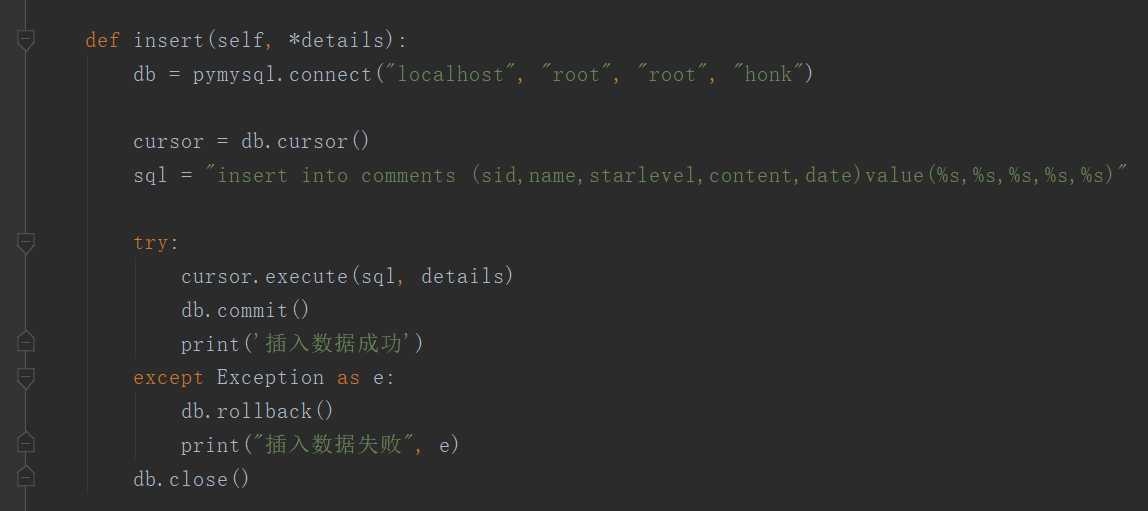
2、景点评论信息数据持久化
6.附完整程序代码
1 # 景点评论的采集和爬取 2 import re 3 4 import redis 5 import requests 6 7 import pymysql 8 from redis import StrictRedis 9 10 # 定义类名和设置默认参数 11 class Comments(object): 12 def __init__(self): 13 self.r = StrictRedis(host=‘localhost‘, port=6379, db=0, decode_responses=True) 14 # 设置请求头 15 self.headers = { 16 ‘user-agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36‘ 17 } 18 # 获取评论信息 19 def param_comments(self, code): 20 page = 1 21 # 要获取的url 22 url = ‘https://place.qyer.com/poi.php?action=comment&page={}&order=5&poiid={}&starLevel=all‘.format(page, code) 23 print(url) 24 # 通过request发起请求 25 resp = requests.post(url, headers=self.headers) 26 # 获得返回json数据分析 27 data = resp.json()[‘data‘][‘lists‘] 28 # 判断数据是否为空 29 if len(data) != 0: 30 # 通过正则匹配的title 31 try: 32 total = resp.json()[‘data‘][‘pagehtml‘] 33 total_page = re.findall(‘title="(.*?)"‘, total)[0].replace(‘...‘, ‘‘) 34 35 except Exception as e: 36 total_page = 1 37 38 print(‘当前总页数:%s‘ % total_page) 39 # 判断有多少页,若返回的信息是下一页就设置为1,否则就用抓取到的页数 40 if total_page == ‘下一页‘: 41 total_page = 1 42 for page in range(1, int(total_page) + 1): 43 print("当前总共%s页,正在采集第%s页!" % (total_page, page)) 44 # 对数据进行清洗和处理 45 url = ‘https://place.qyer.com/poi.php?action=comment&page={}&order=5&poiid={}&starLevel=all‘.format( 46 page, 47 code) 48 # 通过request发起请求 49 resp = requests.post(url, headers=self.headers) 50 # 获得返回json数据分析 51 data = resp.json()[‘data‘][‘lists‘] 52 # 遍历返回的数据,将数据插入数据库 53 for index in data: 54 name = index[‘userinfo‘][‘name‘] 55 starlevel = index[‘starlevel‘] 56 content = index[‘content‘] 57 date = index[‘date‘] 58 print(code, name, starlevel, content, date) 59 # 将带着参数传入这个方法,然后发起请求 60 self.insert(code, name, starlevel, content, date) 61 # 数据持久化 62 def insert(self, *details): 63 # 连接数据库 64 db = pymysql.connect("localhost", "root", "root", "honk") 65 # 获得游标 66 cursor = db.cursor() 67 # 设置sql语句 68 sql = "insert into comments (sid,name,starlevel,content,date)value(%s,%s,%s,%s,%s)" 69 # 执行sql语句 70 try: 71 cursor.execute(sql, details) 72 db.commit() 73 print(‘插入数据成功‘) 74 except Exception as e: 75 db.rollback() 76 print("插入数据失败", e) 77 db.close() 78 # 设置死循环,从缓存里面拿到景点的code然后拼接成url 79 def run(self): 80 while True: 81 code = self.r.lpop(‘h_code‘) 82 83 if code is None: 84 print("当前url请求结束!") 85 break 86 87 self.param_comments(code) 88 90 if __name__ == ‘__main__‘: 91 comments = Comments() 92 comments.run() 93 94 # 景点信息的采集与爬取 95 import pymysql 96 import requests 97 98 # 定义类名和设置默认参数 99 class ScenicInfo(object): 100 def __init__(self): 101 # 要获取的url 102 self.url = ‘https://place.qyer.com/poi.php?action=list_json‘ 103 # 设置请求头 104 self.headers = { 105 ‘user-agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36‘, 106 ‘referer‘: ‘https://place.qyer.com/hong-kong/sight/‘ 107 } 108 # 对数据进行清洗和处理 109 def param_info(self, form_data): 110 # 通过request发起请求 111 resp = requests.post(self.url, form_data, headers=self.headers) 112 # 获得返回json数据解析 113 data = resp.json()[‘data‘][‘list‘] 114 # 遍历返回的数据,将数据插入数据库 115 for index in data: 116 print(index[‘id‘], index[‘cnname‘], index[‘rank‘], index[‘grade‘], index[‘url‘], index[‘commentCount‘]) 117 # 执行操作数据库的方法 118 self.insert(index[‘id‘], index[‘cnname‘], index[‘rank‘], index[‘grade‘], index[‘url‘], 119 index[‘commentCount‘]) 120 121 def run(self): 122 # 通过遍历来改变post的参数,来实现翻页 123 for page in range(1, 65): 124 print(‘当前正在采集第%s页!‘ % str(page)) 125 form_data = { 126 ‘page‘: page, 127 ‘type‘: ‘city‘, 128 ‘pid‘: ‘50‘, 129 ‘sort‘: ‘32‘, 130 ‘subsort‘: ‘all‘, 131 ‘isnominate‘: ‘-1‘, 132 ‘haslastm‘: ‘false‘, 133 ‘rank‘: ‘6‘, 134 } 135 # 将带着参数传入这个方法,然后发起请求 136 self.param_info(form_data) 137 # 数据持久化 138 def insert(*details): 139 # 连接数据库 140 db = pymysql.connect("localhost", "root", "root", "honk") 141 # 获得游标 142 cursor = db.cursor() 143 # 设置sql语句 144 sql = "insert into scenic (cid,name,rank,grade,url,comment_count)value(%s,%s,%s,%s,%s,%s)" 145 # 执行sql语句 146 try: 147 cursor.execute(sql, details) 148 db.commit() 149 print(‘插入数据成功‘) 150 except Exception as e: 151 db.rollback() 152 print("插入数据失败", e) 153 db.close() 154 155 if __name__ == ‘__main__‘: 156 scenicInfo = ScenicInfo() 157 scenicInfo.run() 158 159 from wordcloud import WordCloud 160 import matplotlib.pyplot as plt 161 import jieba 162 163 # 生成词云 164 def create_word_cloud(filename): 165 text = open("{}.txt".format(filename), encoding=‘utf-8‘).read() 166 # 结巴分词 167 wordlist = jieba.cut(text, cut_all=True) 168 wl = " ".join(wordlist) 169 170 # 设置词云 171 wc = WordCloud( 172 # 设置背景颜色 173 background_color="white", 174 # 设置最大显示的词云数 175 max_words=2000, 176 # 这种字体都在电脑字体中,一般路径 177 font_path=‘C:\Windows\Fonts\simfang.ttf‘, 178 height=1200, 179 width=1600, 180 # 设置字体最大值 181 max_font_size=100, 182 # 设置有多少种随机生成状态,即有多少种配色方案 183 random_state=30, 184 ) 185 # 生成词云 186 myword = wc.generate(wl) 187 # 展示词云图 188 plt.imshow(myword) 189 plt.axis("off") 190 plt.show() 191 # 把词云保存下来 192 wc.to_file(‘comments.png‘) 193 194 if __name__ == ‘__main__‘: 195 create_word_cloud(‘comments‘) 196 198 import pymysql 199 import matplotlib.pyplot as plt 200 201 db = pymysql.connect(host="localhost", user=‘root‘, passwd="root", port=3306, db="honk", charset=‘utf8‘) 202 # 获取一个游标 203 cursor = db.cursor() 204 sql = "select name,grade from scenic" 205 cursor.execute(sql) 206 # result为元组 207 result = cursor.fetchall() 208 209 # 将元组数据存进列表中 210 city = [] 211 need = [] 212 for x in result: 213 city.append(x[0]) 214 need.append(float(x[1])) 215 216 # 直方图 217 plt.bar(range(len(need)), need, color=‘steelblue‘, tick_label=city) 218 plt.xlabel("景点") 219 plt.ylabel("评分") 220 plt.title("城市职位需求图") 221 for x, y in enumerate(need): 222 plt.text(x - 2, y + 2, ‘%s‘ % y) 223 plt.show() 224 # 关闭游标 225 cursor.close() 226 # 关闭数据库 227 db.close() 228 229 import json, redis 230 231 # 连接数据库 232 def my_db(table_name): 233 import pymysql 234 coon = pymysql.connect( 235 user=‘root‘, passwd=‘root‘, host=‘127.0.0.1‘, port=3306, 236 db=‘honk‘, charset=‘utf8‘ 237 ) 238 # 建立游标,指定cursor类型返回的是字典 239 cur = coon.cursor(cursor=pymysql.cursors.DictCursor) 240 # cur = coon.cursor() 241 sql = ‘select cid from %s ;‘ % table_name 242 data = cur.execute(sql) 243 # 关闭数据库连接 244 cur.close() 245 coon.close() 246 return cur.fetchall() 247 248 # 对景点urlcode进行去重 249 def removal_set(all_date): 250 comments_code = set() 251 for date in all_date: 252 print(date) 253 key = date.get(‘sid‘) 254 comments_code.add(key) 255 print(key) 256 return comments_code 257 258 # 将code的值添加到缓存里 259 def add_redis(comments_code): 260 r = redis.Redis(host=‘127.0.0.1‘, password=‘‘, db=0) # 端口号默认6379 261 for data in comments_code: 262 r.lpush(‘h_code‘, data["cid"]) 263 print(‘添加完毕!‘) 264 265 # 从缓存里面获取code 266 def get_redis(): 267 r = redis.Redis(host=‘127.0.0.1‘, password=‘‘, db=0) # 端口号默认6379 268 r.lpop(‘h_code‘) 269 270 # 删除code 271 def del_redis(): 272 r = redis.Redis(host=‘127.0.0.1‘, password=‘‘, db=0) # 端口号默认6379 273 r.delete(‘h_code‘) 274 print("key删除成功!") 275 277 if __name__ == ‘__main__‘: 278 all_data = my_db(‘scenic‘) 279 280 # comments_code = removal_set(all_data) 281 282 add_redis(all_data) 283 # del_redis() 284 # get_redis()
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
1、太平山的景点综合排名为第一名
2、多数人来香港都会到维多利亚港、太平山和海洋公园
3、来香港旅游的人还是很多的。
2.对本次程序设计任务完成的情况做一个简单的小结。
答:这次的程序设计任务对我来说是一个新的挑战也是一项难度较高的任务,从原有的课本到书店查看相关书籍到关于python语言和网络爬虫的网课学习 ,由最开始的编程小白渐渐地学会了如何去写代码如何去一步步解决问题。最开始一直害怕的是网站反爬问题,不过幸好后来没有遇到这个问题。历时一个多月我终于完成了这份艰巨的任务,这次的挑战,让我学习和看到了新的不一样的东西,收获了许多新的知识。希望自己以后能够继续进步继续努力。
标签:fetch none port commit rank int mic sub odi
原文地址:https://www.cnblogs.com/ll55/p/12057621.html