标签:分类 contain 提取 nim blog 技术 process lis 对象
XPath与正则都是用于数据的提取,二者的区别是:
所以,如果你可以根据自己的需要进行选择。
请自行学习,效果如下:

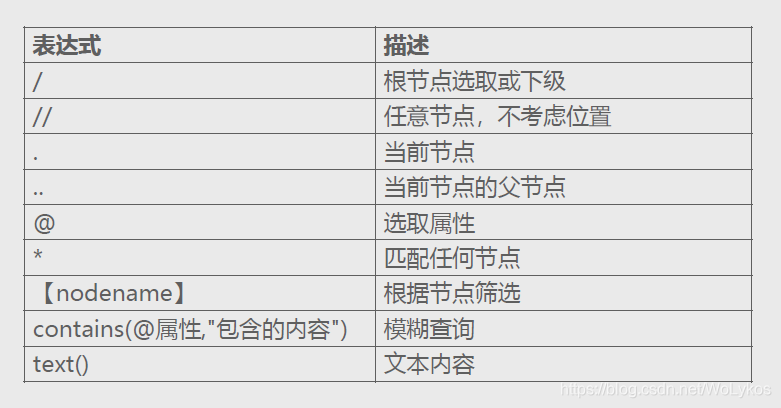
注意:
XPath的索引从1开始。
一级分类:
//h3[@class="classify_c_h3"]/a/text()

二级分类:
//div[@class="classify_list"]/span/a/text()

模糊查询:
//div[contains(@class,"classify_list")]/span/a/text()

import lxml.etree as le
with open('edu.html', 'r', encoding='utf-8') as f:
html = f.read()
# print(html)
# 转换为XPath对象
html_x = le.HTML(html)
# print(html_x)
# 匹配一二级分类的父标签
div_x_s = html_x.xpath('//div[@class="classify_cList"]') # 直接从HTML中取则不用加.
data_s = []
for div_x in div_x_s:
# 一级分类
category1 = div_x.xpath('./h3/a/text()')[0] # 记得加.
# 二级分类
category2_s = div_x.xpath('./div/span/a/text()') # 表示从当前节点进行筛选
data_s.append(
dict(
category1=category1,
category2_s=category2_s
)
)
print(data_s)
for data in data_s:
print(data.get('category1'))
for category2 in data.get('category2_s'):
print(' ', category2)Python爬虫基础——XPath语法的学习与lxml模块的使用
标签:分类 contain 提取 nim blog 技术 process lis 对象
原文地址:https://www.cnblogs.com/WoLykos/p/12072119.html