标签:过程 keep nstat ssi col str 切换 基础 nta
在本文中,将对“牛市”和“熊市”两个独立机制下的市场收益进行模拟。隐马尔可夫模型识别处于特定状态的概率。
在概述了模拟数据的过程之后,将隐马尔可夫模型应用于美国股票数据,以确定基本机制。
市场体制
将隐马尔可夫模型应用于状态检测是棘手的,因为该问题实际上是无监督学习的一种形式。也就是说,没有“基础事实”或标记数据可在其上“训练”模型。 是否有两个,三个,四个或更多个“真正的”隐藏市场机制?
这些问题的答案在很大程度上取决于要建模的资产类别,时间范围的选择以及所使用数据的性质。
模拟数据
在本节中,从独立的高斯分布中生成模拟的收益率数据,每个分布都代表“看涨”或“看涨”的市场机制。看涨收益来自均值正且方差低的高斯分布,而看跌收益来自均值略为负但方差较高的高斯分布。
第一个任务是安装depmixS4和quantmod库,然后将它们导入R。
install.packages(‘depmixS4‘)
install.packages(‘quantmod‘)
library(‘depmixS4‘)
library(‘quantmod‘)
set.seed(1)在牛市分布N(0.1,0.1)N(0.1,0.1)而空头市场分布为N(−0.05,0.2)N(−0.05,0.2)。通过以下代码设置参数:
# Create the parameters for the bull and
# bear market returns distributions
Nk_lower <- 50
Nk_upper <- 150
bull_mean <- 0.1
bull_var <- 0.1
bear_mean <- -0.05
bear_var <- 0.2# Create the list of durations (in days) for each regime
days <- replicate(5, sample(Nk_lower:Nk_upper, 1))第kk个周期的收益是随机抽取的:
# Create the various bull and bear markets returns
market_bull_1 <- rnorm( days[1], bull_mean, bull_var )
market_bear_2 <- rnorm( days[2], bear_mean, bear_var )
market_bull_3 <- rnorm( days[3], bull_mean, bull_var )
market_bear_4 <- rnorm( days[4], bear_mean, bear_var )
market_bull_5 <- rnorm( days[5], bull_mean, bull_var )创建真实状态
# Create the list of true regime states and full returns list
true_regimes <- c( rep(1,days[1]), rep(2,days[2]), rep(1,days[3]), rep(2,days[4]), rep(1,days[5]))
returns <- c( market_bull_1, market_bear_2, market_bull_3, market_bear_4, market_bull_5)绘制收益图可显示切换之间均值和方差的明显变化:
plot(returns, type="l", xlab=‘‘, ylab="Returns") 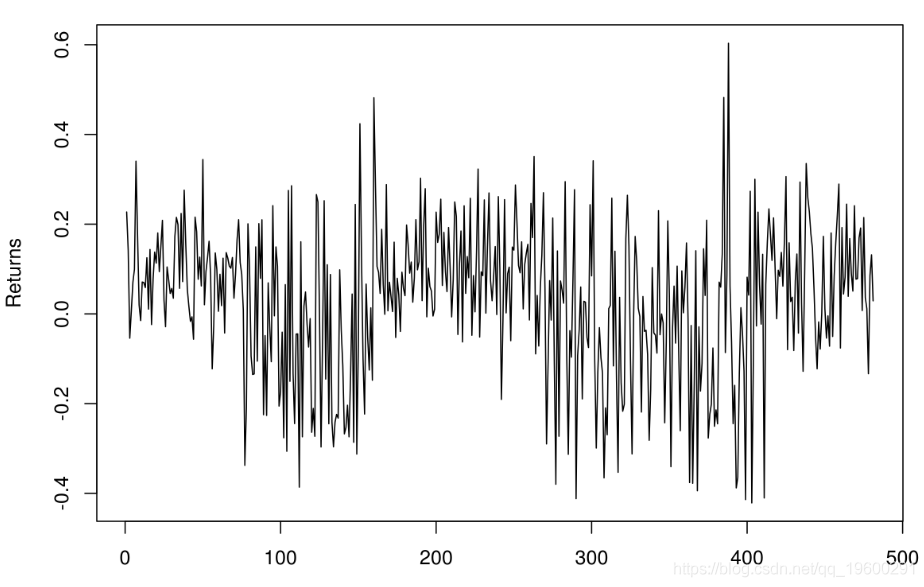
在此阶段,可以使用Expectation Maximization算法指定隐马尔可夫模型并进行拟合:
# Create and fit the Hidden Markov Model
hmm <- depmix(returns ~ 1, family = gaussian(), nstates = 2, data=data.frame(returns=returns))
hmmfit <- fit(hmm, verbose = FALSE)在模型拟合之后,可以绘制处于特定状态的后验概率。post_probs包含后验概率。
# Output both the true regimes and the
# posterior probabilities of the regimes
post_probs <- posterior(hmmfit)
layout(1:2)
plot(post_probs$state, type=‘s‘, main=‘True Regimes‘, xlab=‘‘, ylab=‘Regime‘)
matplot(post_probs[,-1], type=‘l‘, main=‘Regime Posterior Probabilities‘, ylab=‘Probability‘)
legend(x=‘topright‘, c(‘Bull‘,‘Bear‘), fill=1:2, bty=‘n‘)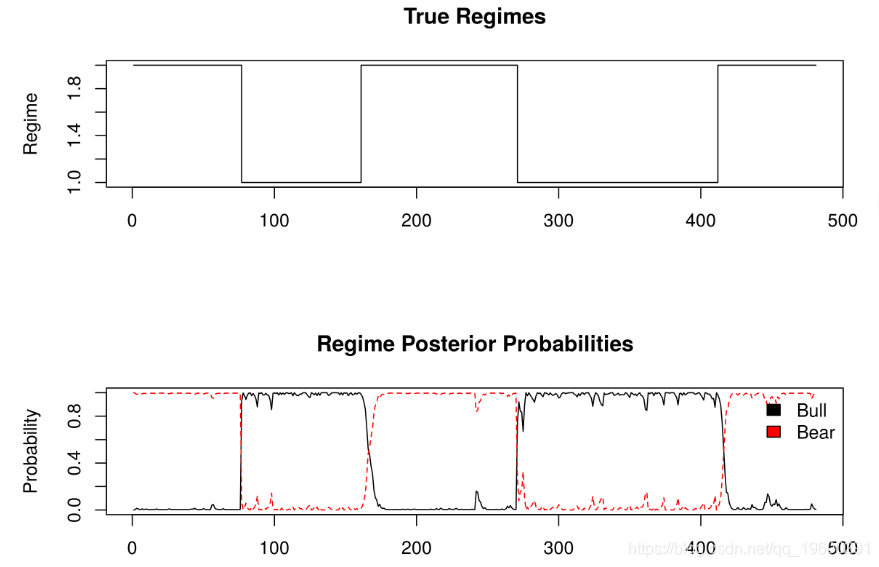
在本节中,将执行两个单独的建模任务。第一种将使HMM具有两个机制状态以拟合S&P500收益率,而第二个将利用三个状态。比较两个模型之间的结果。
使用quantmod库下载:
# Obtain S&P500 data from 2004 onwards and
# create the returns stream from this
getSymbols( "^GSPC", from="2004-01-01" )
gspcRets = diff( log( Cl( GSPC ) ) )
returns = as.numeric(gspcRets)gspcRets时间序列显示2008和2011时期:plot(gspcRets)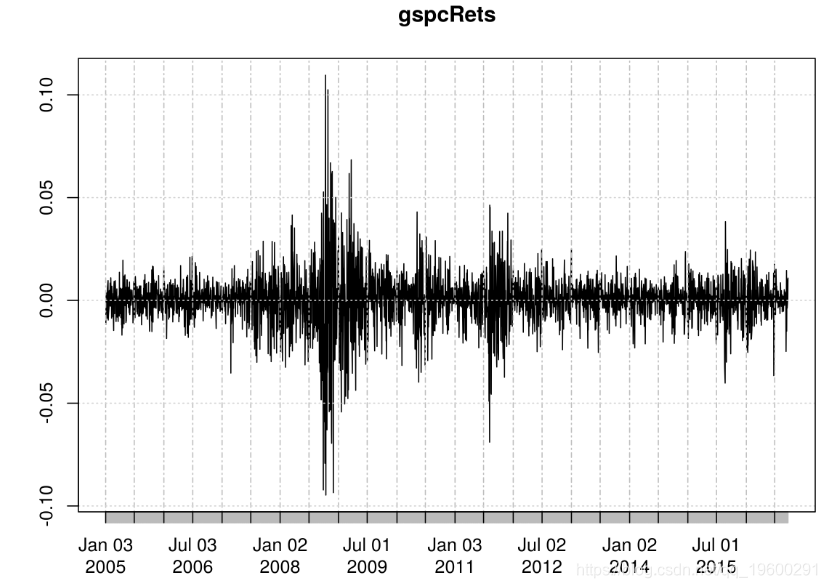
使用EM算法拟合隐马尔可夫模型。每种方案的收益率和后验概率作图:
# Fit a Hidden Markov Model with two states
# to the S&P500 returns stream
hmm <- depmix(returns ~ 1, family = gaussian(), nstates = 2, data=data.frame(returns=returns))
hmmfit <- fit(hmm, verbose = FALSE)
post_probs <- posterior(hmmfit)
# Plot the returns stream and the posterior
# probabilities of the separate regimes
layout(1:2)
plot(returns, type=‘l‘, main=‘Regime Detection‘, xlab=‘‘, ylab=‘Returns‘)
matplot(post_probs[,-1], type=‘l‘, main=‘Regime Posterior Probabilities‘, ylab=‘Probability‘)
legend(x=‘bottomleft‘, c(‘Regime #1‘,‘Regime #2‘), fill=1:2, bty=‘n‘)
请注意,在2004年和2007年期间,市场较为平静,因此在此期间,隐马尔可夫模型第二种机制的可能性较高。然而,在2007年至2009年之间,由于次贷危机。
市场在2010年变得较为平静,但在2011年又出现了更多动荡,这导致HMM再次给第一类机制带来了较高的后验概率。2011年之后,市场再次趋于平静,HMM始终给第二种机制以高概率。2015年,市场再次变得更加混乱,这反映在HMM机制之间的切换增加。
# Fit a Hidden Markov Model with three states
# to the S&P500 returns stream
hmm <- depmix(returns ~ 1, family = gaussian(), nstates = 3, data=data.frame(returns=returns))
hmmfit <- fit(hmm, verbose = FALSE)
post_probs <- posterior(hmmfit)
# Plot the returns stream and the posterior
# probabilities of the separate regimes
layout(1:2)
plot(returns, type=‘l‘, main=‘Regime Detection‘, xlab=‘‘, ylab=‘Returns‘)
matplot(post_probs[,-1], type=‘l‘, main=‘Regime Posterior Probabilities‘, ylab=‘Probability‘)
legend(x=‘bottomleft‘, c(‘Regime #1‘,‘Regime #2‘, ‘Regime #3‘), fill=1:3, bty=‘n‘)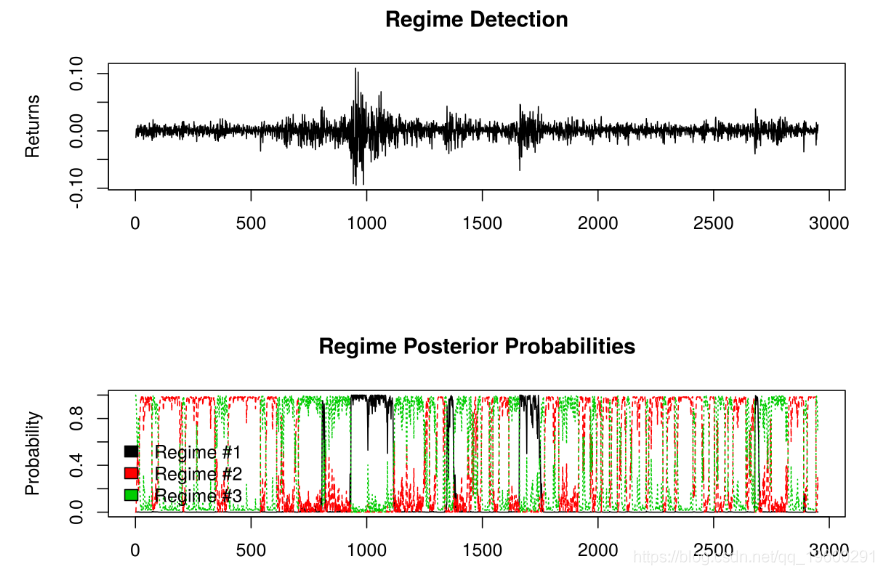
数据的长度使后验概率图难以解释。由于该模型被迫考虑三个单独的机制,因此在2004-2007年的平静时期导致了机制2和机制3之间的转换。但是,在2008、2010和2011年的动荡时期,机制1主导着后验概率,表明高度波动状态。在2011年之后,模型恢复为在机制2和机制3之间切换。
标签:过程 keep nstat ssi col str 切换 基础 nta
原文地址:https://www.cnblogs.com/tecdat/p/12072609.html