标签:信息 表格 nts self scribe 概述 code from img
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
网易云歌曲排行榜歌曲时长
2.主题式网络爬虫爬取的内容与数据特征分析
主要是爬取网易云里面的歌名,歌手和歌曲时长。
对网易云歌曲的时长做一个可视化表格。
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
实现思路:利用requests的get方法访问网站。
用xpath方法解析网页原码。
技术难点:需要下载最新版本的谷歌,还需要安装谷歌的驱动否则运行不出来。
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
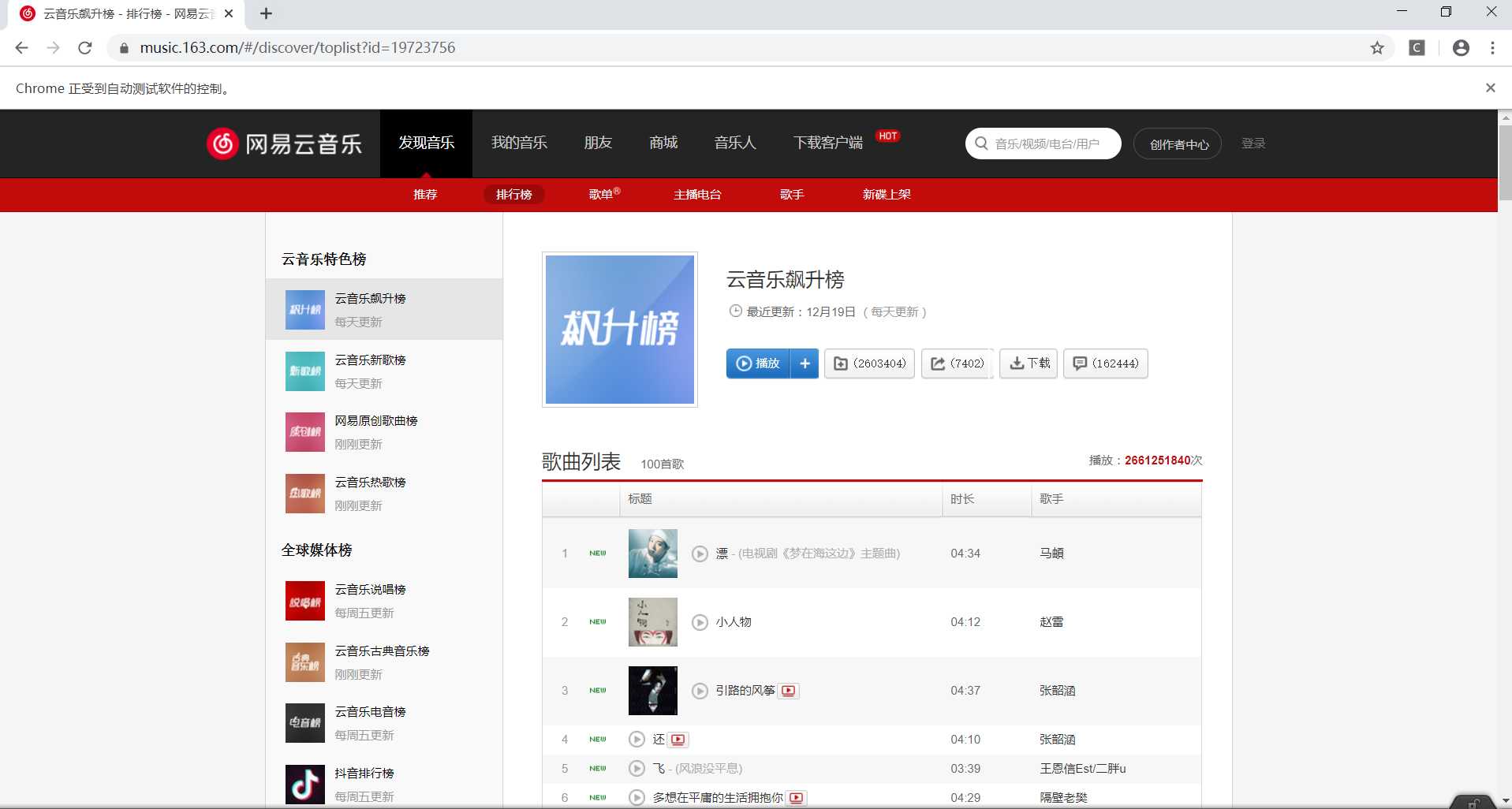
2.Htmls页面解析
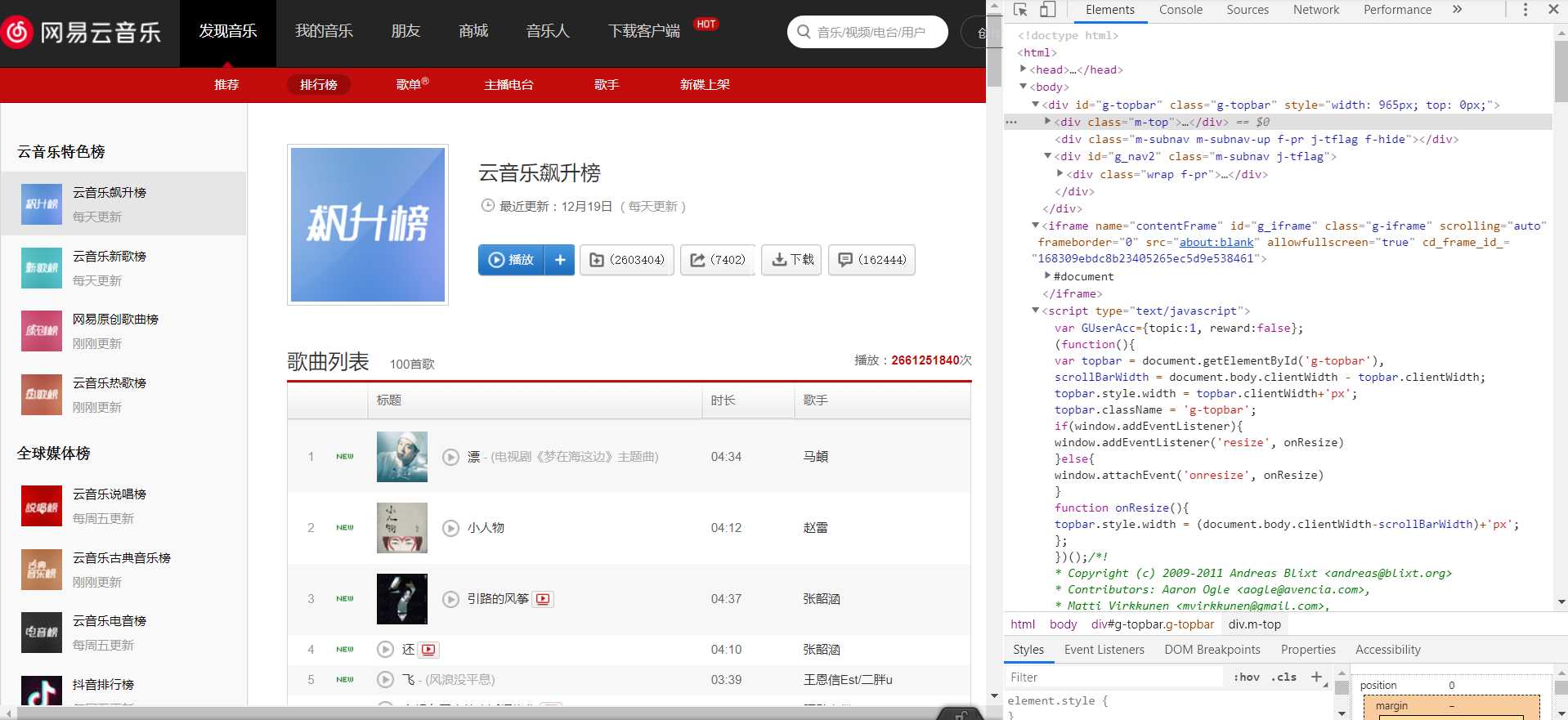
3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
根据F12中的数据查找到相应位置并requests.get(),再利用正则找到正确的数据并保存起来
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
爬取的代码如下:
from lxml import etree from selenium import webdriver import pandas as pd class WangyiMusic(): # 请求的地址 云音乐飙升榜 url = "https://music.163.com/#/discover/toplist?id=19723756" def __init__(self): #选择浏览器驱动 chromedriver.exe self.browser = webdriver.Chrome(executable_path="D:\python\chromedriver.exe") if self.get_HTML(): self.parse_HTML() #由于页面的歌曲信息都存放在页面的ifram里面,所以采用Selenium进入子页面获得源码 def get_HTML(self): #使用get方法访问网站 self.browser.get(self.url) self.browser.switch_to_frame(‘contentFrame‘) iframe = self.browser.page_source return iframe #用xpath方法解析网页原码 def parse_HTML(self): iframe = self.get_HTML() html = etree.HTML(iframe) try: #获取排名 num = html.xpath(‘//td/div/span[@class = "num"]/text()‘) #获取歌名 song = html.xpath(‘//td//div/span[@class="txt"]/a/b/@title‘) #获取歌手 singer = html.xpath(‘//td/div[@class = "text"]/@title‘) #获取歌曲时长 time = html.xpath(‘//td[@class = " s-fc3"]/span[@class = "u-dur "]/text()‘) #DataFrame列名 columns_list = [‘歌名‘,‘歌手‘,‘时长‘] #将歌名、歌手和时长用zip函数转换成一个列表数据类型 data = list(zip(song,singer,time)) #用排名做行索引 index_list = num #转换成DataFram数据 dataFrame = pd.DataFrame(data,index = index_list,columns = columns_list) #避免多次运行爬取,将数据存入csv文件中,做后续的数据分析 dataFrame.to_csv(".wangyiMusic.csv") return dataFrame except Exception as e: print(‘解析失败!‘,e.args) object = WangyiMusic() print(object.parse_HTML())
运行结果如下:

2.对数据进行清洗和处理
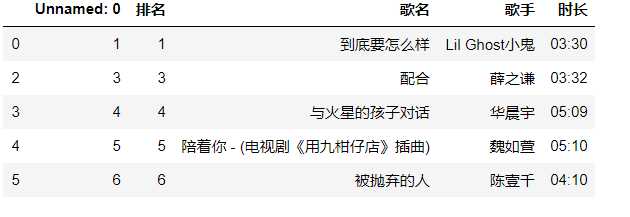
#输出网易云数据文件的前5行 data=pd.DataFrame(pd.read_csv(‘./wangyiMusic.csv‘)) data.head()
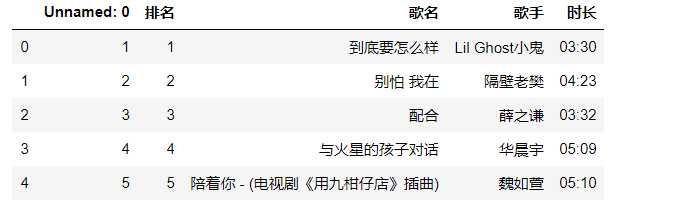
#删除无效列 data.drop(1,axis=0,inplace=True) data.head()
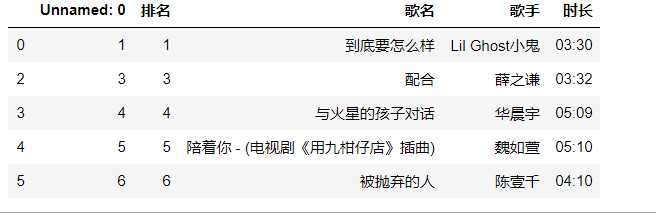
#查找重复值 data.duplicated()
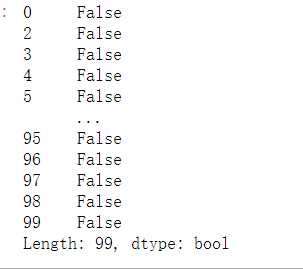
#删除重复值 data=data.drop_duplicates() data.head()
#空值处理 data[‘歌名‘].isnull().value_counts()

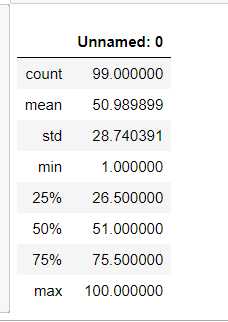
#异常值处理 data.describe()
3.文本分析(可选):jieba分词、wordcloud可视化
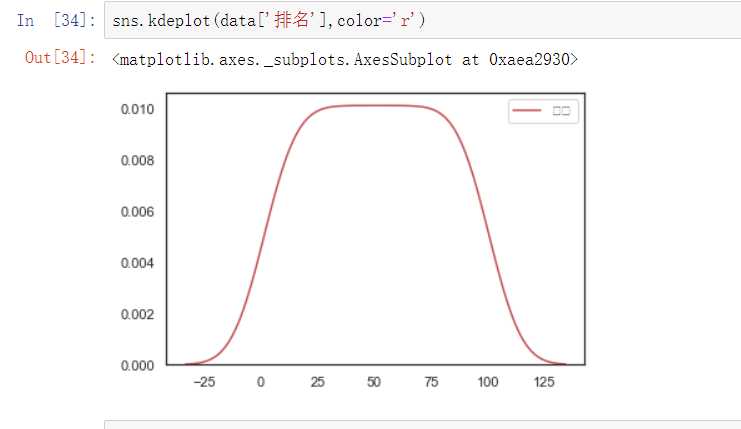
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
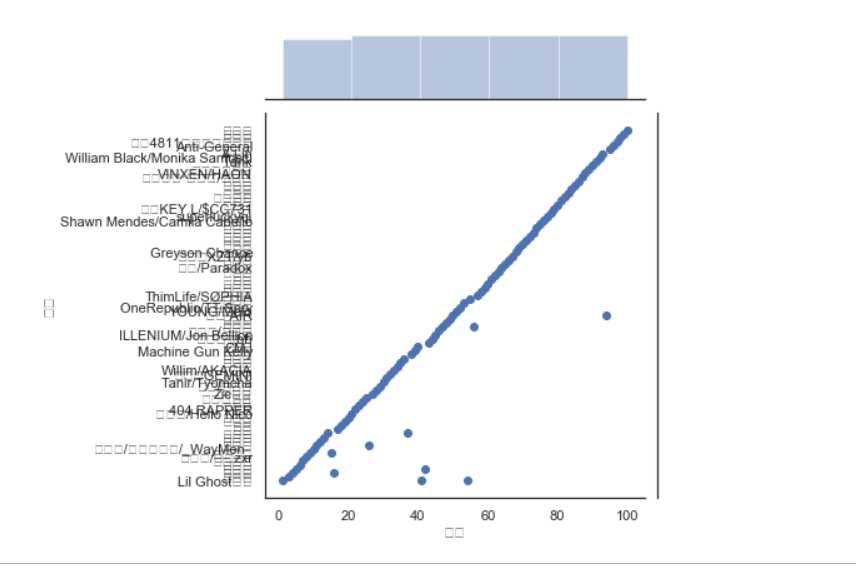
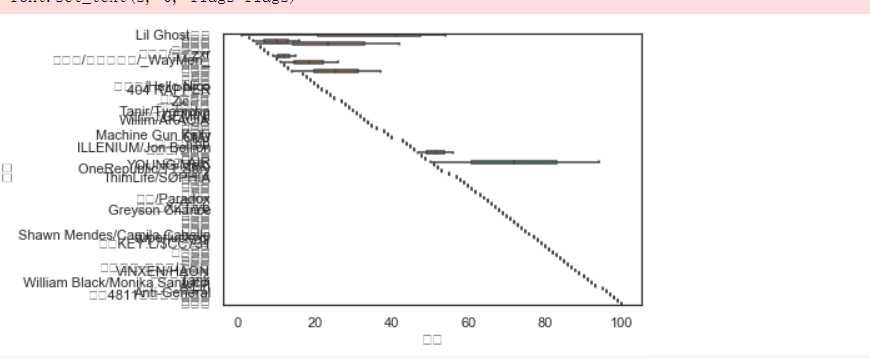
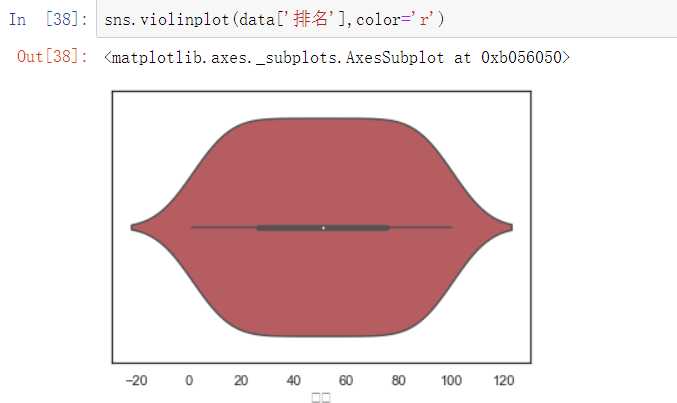
5.数据持久化

6.附完整程序代码
from lxml import etree
from selenium import webdriver
import pandas as pd
class WangyiMusic():
# 请求的地址 云音乐飙升榜
url = "https://music.163.com/#/discover/toplist?id=19723756"
def __init__(self):
#选择浏览器驱动 chromedriver.exe
self.browser = webdriver.Chrome(executable_path="D:\python\chromedriver.exe")
if self.get_HTML():
self.parse_HTML()
#由于页面的歌曲信息都存放在页面的ifram里面,所以采用Selenium进入子页面获得源码
def get_HTML(self):
#使用get方法访问网站
self.browser.get(self.url)
self.browser.switch_to_frame(‘contentFrame‘)
iframe = self.browser.page_source
return iframe
#用xpath方法解析网页原码
def parse_HTML(self):
iframe = self.get_HTML()
html = etree.HTML(iframe)
try:
#获取排名
num = html.xpath(‘//td/div/span[@class = "num"]/text()‘)
#获取歌名
song = html.xpath(‘//td//div/span[@class="txt"]/a/b/@title‘)
#获取歌手
singer = html.xpath(‘//td/div[@class = "text"]/@title‘)
#获取歌曲时长
time = html.xpath(‘//td[@class = " s-fc3"]/span[@class = "u-dur "]/text()‘)
#DataFrame列名
columns_list = [‘歌名‘,‘歌手‘,‘时长‘]
#将歌名、歌手和时长用zip函数转换成一个列表数据类型
data = list(zip(song,singer,time))
#用排名做行索引
index_list = num
#转换成DataFram数据
dataFrame = pd.DataFrame(data,index = index_list,columns = columns_list)
#避免多次运行爬取,将数据存入csv文件中,做后续的数据分析
dataFrame.to_csv(".wangyiMusic.csv")
return dataFrame
except Exception as e:
print(‘解析失败!‘,e.args)
object = WangyiMusic()
print(object.parse_HTML())
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
结论:
大部分的歌曲时长都集中在3-4分钟之间。
隔壁老樊,小鬼和华晨宇等歌手比较受听众喜爱。
2.对本次程序设计任务完成的情况做一个简单的小结。
由于自己知识的缺乏在进行实操出现各种各样的错误,不断翻阅书籍才补缺补漏将代码写好。这次的作业让我python更进一步的了解也更加深了我的知识,是一次很好的学习过程。
标签:信息 表格 nts self scribe 概述 code from img
原文地址:https://www.cnblogs.com/zzr99/p/12070415.html