标签:自己 mil home import 作业 bad http 输入 aci
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
京东商品比价定向爬虫
2.主题式网络爬虫爬取的内容与数据特征分析
对指定的京东商品名称+价格分类爬取进行比较
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
获取京东搜索页面的信息,提取其中的商品名称和价格
京东的搜索接口,怎么通过程序向拼多多提交请求并获得返回的结果
技术路线:requests‐bs4‐re
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
https://www.pinduoduo.com/home/supermarket/
2.Htmls页面解析
3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)

三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
2.对数据进行清洗和处理
3.文本分析(可选):jieba分词、wordcloud可视化
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
需求:
模拟浏览器
将爬取数据存储到excel
爬取数据
遍历商品,构建字典将商品的价格由低至高排序
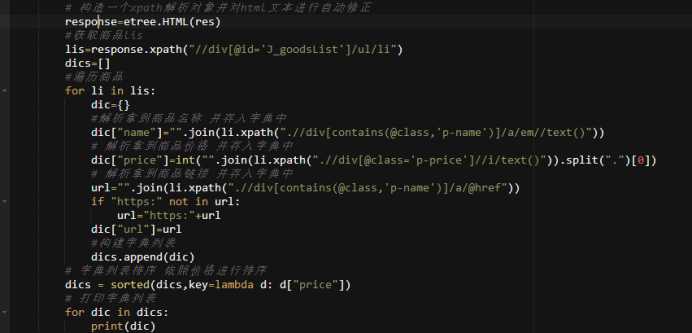
将数据存储至excel
登录京东
登录url:https://search.jd.com/Search?keyword=%E6%89%8B%E7%8E%AF&enc=utf-8&wq=%E6%89%8B%E7%8E%AF&pvid=540e8fa47b4e4eed8dc18f50f9b12427"
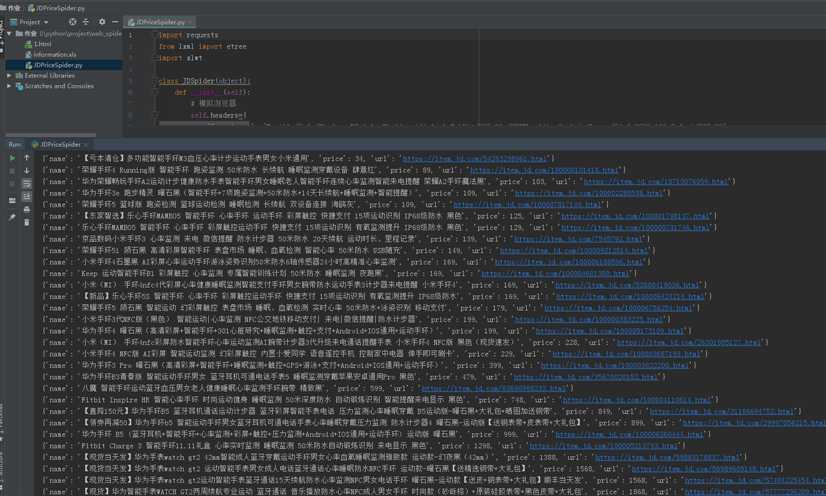
运行结果:
5.数据持久化
import requests
from lxml import etree
import xlwt
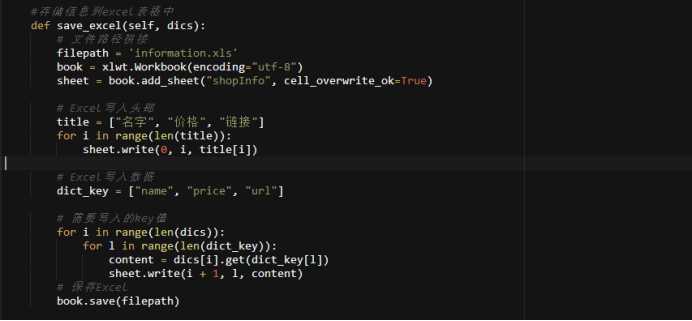
class JDSpider(object):
def __init__(self):
# 模拟浏览器
self.headers={
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36",
"cookie": "shshshfpa=57509b59-8069-519a-1641-3f220e3335e0-1561532203; shshshfpb=m4PGDEWSU4%20wrkiFPg2RE5A%3D%3D; __jdu=2000960888; qrsc=3; pinId=Kzs80NxA6hywPwqU1ahgAw; _base_=YKH2KDFHMOZBLCUV7NSRBWQUJPBI7JIMU5R3EFJ5UDHJ5LCU7R2NILKK5UJ6GLA2RGYT464UKXAI4Z6HPCTN4UQM3WHVQ4ENFP57OC6NEK6D6VJMD2N3BXP2H7NLTWX2TCNE6YVKRXISVMTLK5AVTQAH4EXMXGPYGVEOCQCSG4SOQWCP5WPWO6EFS7HEHMRWVKBRVHB33TFD4GL3U5GHRXUST5CDB7PGO73OEDI52BWVGQBKUX7DOFBCZI4SEQU7S5WA4VUS4LVOIBF7GUMQX2MZK7H3ZRU7WA5GKJMYGGXIN62B2M7UBSRP2BADLWCZAGBVJ7XUUUP7FZ4GORYX6BGLIHWUP5JGRH5KARUJXA3TJDTBGGDN3K2L5MOPSA7Z; TrackID=1_EixmrOQPQHvwkPmuQF9xhmZh48YjMirwXwM_C2e77nnMdAqUQfGk5g2o22oFpMIs03ABGMLOkZxut0teqnfvc1394M0IapCL1sV4Z4_7Ug; areaId=2; user-key=bc52c4c3-32a6-4833-a12d-0d1dd4aa3217; cn=0; ipLoc-djd=2-2813-51976-0; PCSYCityID=CN_310000_310100_0; xtest=4604.cf6b6759; mt_xid=V2_52007VwATU1xQVVsWQBBsDGBWFgENDAdGHBsRXhliBxECQQgFCRxVTF0HMwoTUApaVQ5LeRpdBW8fElFBWFdLH0wSXgFsBhBiX2hSah9JHVoAYwIQV1poUlMeSQ%3D%3D; unpl=V2_ZzNtbRZUQBcnDhQBeh5YDGIDEl1LBEZBcAgTBikbXQBjVEdZclRCFX0URldnGVoUZwcZX0BcRhNFCEdkeBBVAWMDE1VGZxBFLV0CFSNGF1wjU00zQwBBQHcJFF0uSgwDYgcaDhFTQEJ2XBVQL0oMDDdRFAhyZ0AVRQhHZHgYXQRvBBNUS15zJXI4dmR%2bEFwBYQAiXHJWc1chVEJUeBxcBSoAE1xDX0QUfAFPZHopXw%3d%3d; __jdv=76161171|baidu-pinzhuan|t_288551095_baidupinzhuan|cpc|0f3d30c8dba7459bb52f2eb5eba8ac7d_0_e223c7cd065841118b4e41dcc3045fd5|1576568024183; 3AB9D23F7A4B3C9B=2AN3B7KCFOIALQLOFAUKI6UKRH4LKM7TACIQJJCIAV7FQ2JX4QMA6W3QVMG4KWP3V7JKBTGVY4MG6CZAA7EFHZX554; __jda=122270672.2000960888.1559775283.1576568024.1576812768.31; __jdb=122270672.2.2000960888|31.1576812768; __jdc=122270672; shshshfp=2d92c14af643b77229b065704a92defb; shshshsID=def5c1eaf39366b0cf81f403576ab9a5_1_1576812779775; rkv=V0900",
"referer": "https://www.jd.com/"
}
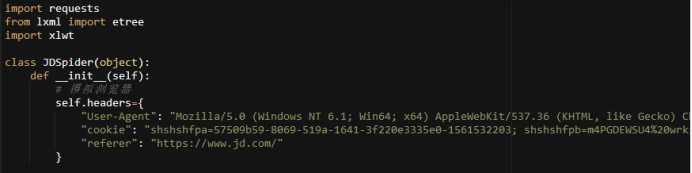
#存储信息到excel表格中
def save_excel(self, dics):
# 文件路径拼接
filepath = ‘information.xls‘
book = xlwt.Workbook(encoding="utf-8")
sheet = book.add_sheet("shopInfo", cell_overwrite_ok=True)
# Excel写入头部
title = ["名字", "价格", "链接"]
for i in range(len(title)):
sheet.write(0, i, title[i])
# Excel写入数据
dict_key = ["name", "price", "url"]
# 需要写入的key值
for i in range(len(dics)):
for l in range(len(dict_key)):
content = dics[i].get(dict_key[l])
sheet.write(i + 1, l, content)
# 保存Excel
book.save(filepath)
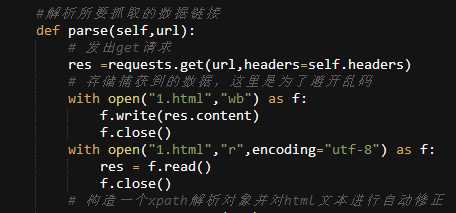
#解析所要抓取的数据链接
def parse(self,url):
# 发出get请求
res =requests.get(url,headers=self.headers)
# 存储捕获到的数据,这里是为了避开乱码
with open("1.html","wb") as f:
f.write(res.content)
f.close()
with open("1.html","r",encoding="utf-8") as f:
res = f.read()
f.close()
# 构造一个xpath解析对象并对html文本进行自动修正
response=etree.HTML(res)
#获取商品lis
lis=response.xpath("//div[@id=‘J_goodsList‘]/ul/li")
dics=[]
#遍历商品
for li in lis:
dic={}
#解析拿到商品名称 并存入字典中
dic["name"]="".join(li.xpath(".//div[contains(@class,‘p-name‘)]/a/em//text()"))
# 解析拿到商品价格 并存入字典中
dic["price"]=int("".join(li.xpath(".//div[@class=‘p-price‘]//i/text()")).split(".")[0])
# 解析拿到商品链接 并存入字典中
url="".join(li.xpath(".//div[contains(@class,‘p-name‘)]/a/@href"))
if "https:" not in url:
url="https:"+url
dic["url"]=url
#构建字典列表
dics.append(dic)
# 字典列表排序 依照价格进行排序
dics = sorted(dics,key=lambda d: d["price"])
# 打印字典列表
for dic in dics:
print(dic)
#存储数据到excel表格中
self.save_excel(dics)
def run(self):
# 输入需要获取的页面链接
url="https://search.jd.com/Search?keyword=%E6%89%8B%E7%8E%AF&enc=utf-8&wq=%E6%89%8B%E7%8E%AF&pvid=540e8fa47b4e4eed8dc18f50f9b12427"
# 解析链接
self.parse(url)
#程序开头
if __name__ == ‘__main__‘:
JD = JDSpider()
JD.run()
三、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
大部分的商品价格相差并不大。
但是最低和最高还是差了很多。
2.对本次程序设计任务完成的情况做一个简单的小结。
由于自己知识的缺乏在进行实操出现各种各样的错误,不断翻阅书籍才补缺补漏将代码写好。这次的作业让我python更进一步的了解也更加深了我的知识,是一次很好的学习过程。
标签:自己 mil home import 作业 bad http 输入 aci
原文地址:https://www.cnblogs.com/h993472551/p/12074625.html