标签:response 图片 unicode cap exce ade www odi 链接
一、主题式网络爬虫设计方案
1. 主题式网络爬虫的名称
纵横小说网的爬取
2. 主题式网络爬虫的内容与数据特征分析
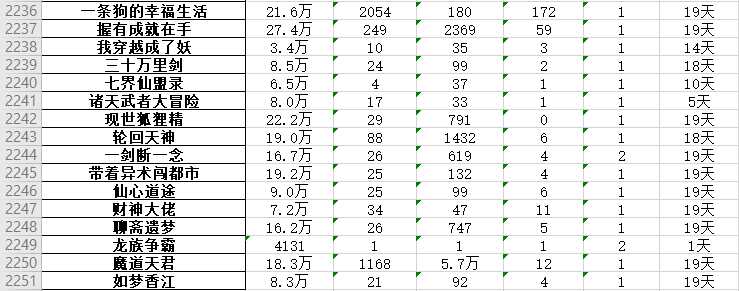
爬取内容:小说网链接,小说网页面链接,小说链接,小说名
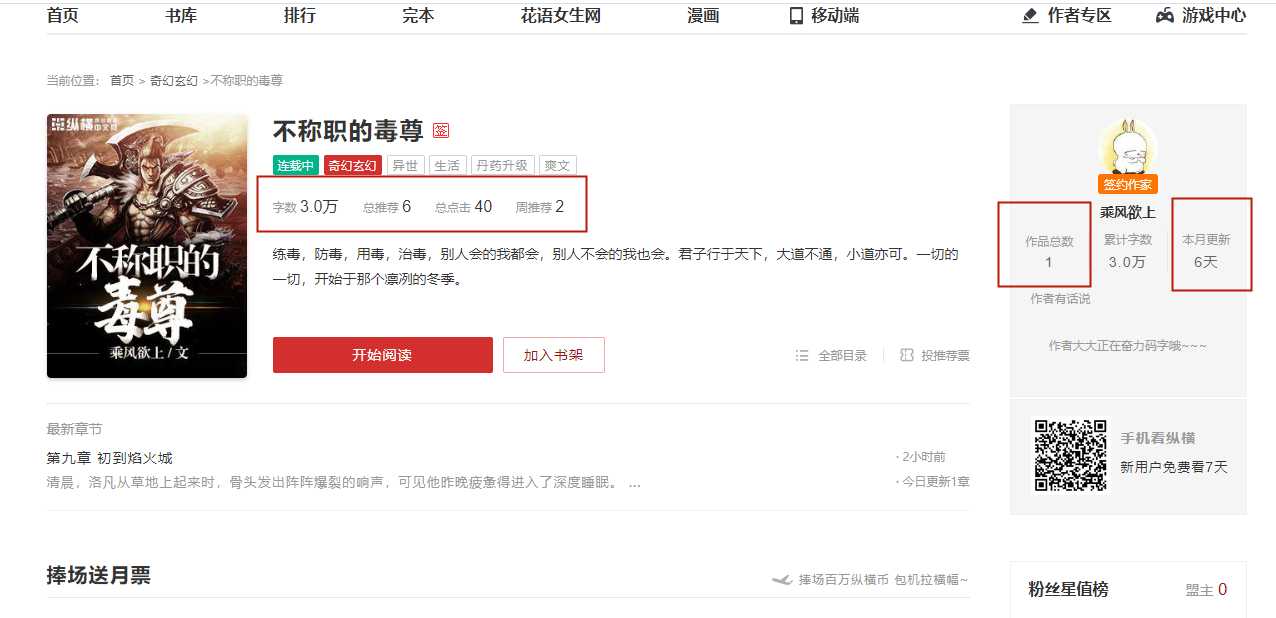
小说的字数、总推荐、总点击、周推荐、作品总数和每月更新
数据特征分析: 把书名、总推荐和总点击做透视表和可视化
做用每月更新和作品总数的可视化图
3. 主题式网络爬虫设计方案概述(包括实现思路和技术难点)
1. 实现思路:定义一个get函数去获取URL,接下来爬取自己所要的数据并且把他们拼接储存
2. 技术难点:可能会被禁IP一段时间,出现验证码,所以要想办法避开它
二、主题页面的结构特征分析
1.主题页面的结构特征
每页50项数据,爬取大约50页,共计约2500条数据。
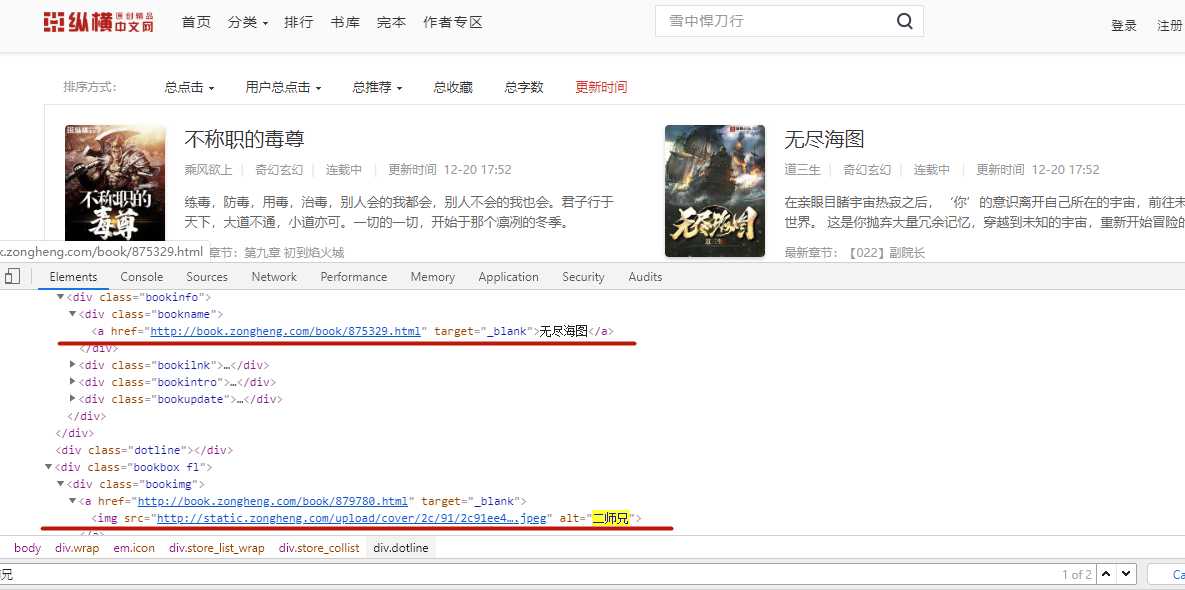
2,HTML页面解析
框中的数据都是需要爬取的字段。
3,节点(标签)查找方法与遍历发法(必要时画出节点数结构)
开网页的html搜索到第一个需要的内容,然后用正则表达式解析获取其余剩下的内容
三,网络爬虫程序设计
1,爬虫程序主题要包括以下部分,要附源代码及较详解注释,并在每部分程序后面提供输出结果的截图。
import requests import re import pandas as pd from fake_useragent import UserAgent import time import random #定义空列表 list_book_url = [] list_book_name = [] book_num_list = [] list_book_words = [] list_book_top = [] list_book_down = [] lll = [] a = [‘字数 ‘, ‘总推荐‘, ‘总点击‘, ‘周推荐‘,‘作品总数‘,‘每月更新‘] headers = { "User-Agent": UserAgent().random, "Cookies": "ZHID=00C4949100DCF069FDAFC28437EDDC3A; ver=2018; zh_visitTime=1576649797733; zhffr=www.baidu.com; v_user=https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DktxoKeZnEBAryUL8KyHEgpQkyD1mDg9g3WcFMtHpoufhlDAlC_a_f6C2ZNkwvZPh%26wd%3D%26eqid%3Da6d0c4a7000bf63c000000065df9c43c%7Chttp%3A%2F%2Fwww.zongheng.com%2F%7C46933825; sajssdk_2015_cross_new_user=1; Hm_up_c202865d524849216eea846069349eb9=%7B%22uid_%22%3A%7B%22value%22%3A%2200C4949100DCF069FDAFC28437EDDC3A%22%2C%22scope%22%3A1%7D%7D; zh_rba=true; platform=H5; PassportCaptchaId=8ff316499b6006386e66840ea1a004cd; Hm_lvt_c202865d524849216eea846069349eb9=1576650560,1576650668,1576661503,1576661899; JSESSIONID=abcdVgyjTeSPs7Rz8Ay8w; rSet=1_3_1_14; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2216f17a6b139df-0cba7f8e2cf92b-2393f61-1049088-16f17a6b13a2d3%22%2C%22%24device_id%22%3A%2216f17a6b139df-0cba7f8e2cf92b-2393f61-1049088-16f17a6b13a2d3%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%7D; Hm_lpvt_c202865d524849216eea846069349eb9=1576671881" } for i in range(1000): url = ‘‘ # 我们请求网站的接口 url = ‘http://book.zongheng.com/store/c0/c0/b0/u0/p‘+str(i)+‘/v0/s9/t0/u0/i1/ALL.html‘ response = requests.get(url=url, headers=headers) # 设置返回的编码 response.encoding = ‘utf-8‘ book_name = re.compile(r‘<div class="bookname">\r\n\s*?<a href="(.*?)" target="_blank">(.*?)</a>‘, re.S) book_list = book_name.findall(response.text) #获取每页每本小说的URL和名字 for j in range(len(book_list)): list_book_url.append(book_list[j][0]) list_book_name.append(book_list[j][1]) #控制爬取速度 time.sleep(random.random() * 3) for n in range(len(list_book_url)): responsz = requests.get(list_book_url[n]) responsz.encoding = ‘utf-8‘ #获取每本小说的字数、总推荐、总点击和周推荐 book_num = re.compile(r‘<div\sclass="nums"><span>字数\s<i>(.*?)\s</i>\s</span>\s<span>总推荐\s<i>(.*?)</i>\s</span>\s<span>总点击\s<i>(.*?)</i>\s</span>\s<span>周推荐\s<i>(.*?)</i>\s</span></div>‘, re.S) book_num_list1 = book_num.findall(responsz.text) book_num_list.append(book_num_list1) # 获取每本小说的作品总数和月更新几天 book_words = re.compile(r‘<div\sclass="au-words">.*?<span>作品总数<i>(.*?)</i></span>.*?<span>累计字数<i>.*?</i></span>.*?<span>本月更新<i>(.*?)</i></span>.*?</div>‘, re.S) book_words1 = book_words.findall(responsz.text) list_book_words.append(book_words1) time.sleep(random.random() * 3) #数据提取拼接 for i in range(len(book_list)): list_book_top.append(book_num_list[i][0]) list_book_down.append(list_book_words[i][0]) lll.append(book_num_list[i][0] + list_book_words[i][0]) #制作成表储存 df = pd.DataFrame(lll,index=[list_book_name],columns=a) df.to_excel(‘novel.xlsx‘)
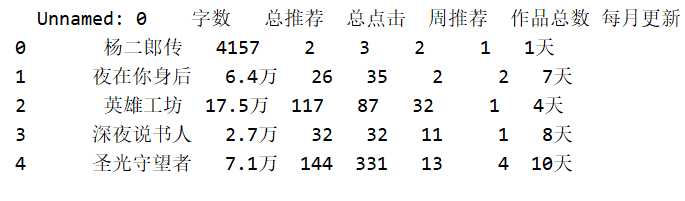
2.对数据进行清洗和处理
导包
# 导包操作 import numpy as np import pandas as pd import matplotlib.pyplot as plt from pandas import DataFrame, Series from pylab import mpl # 指定默认字体:解决plot不能显示中文问题 mpl.rcParams[‘font.sans-serif‘] = [‘Microsoft YaHei‘] # 解决保存图像是负号‘-‘显示为方块的问题 mpl.rcParams[‘axes.unicode_minus‘] = False %matplotlib inline
读取爬到的数据
novels = pd.DataFrame(pd.read_excel(‘novel.xlsx‘))
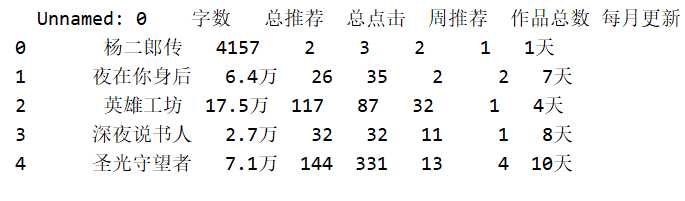
查看数据大小并显示前5条数据
novels.head()
查看是否存在重复值
novels.duplicated()
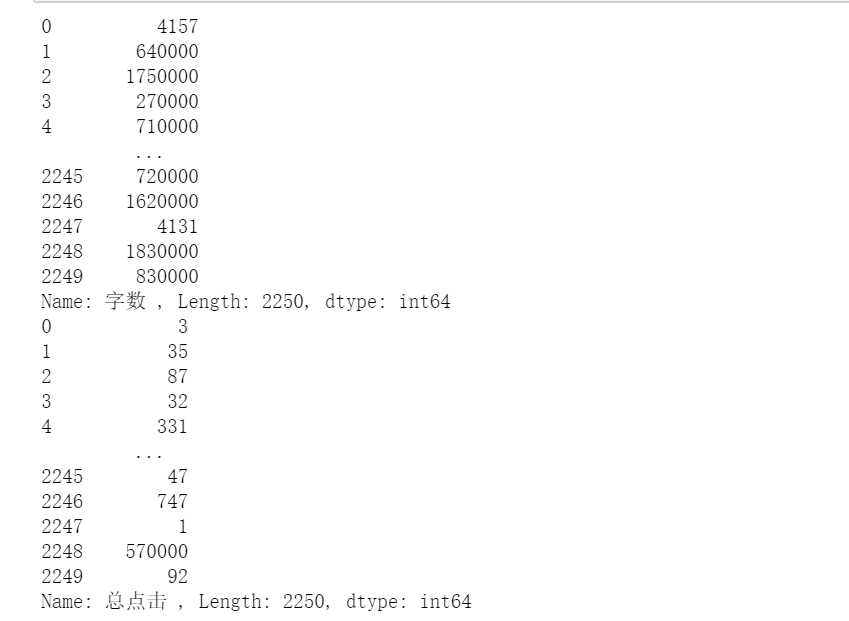
把数据字数和总点击中小数点去掉,把‘’万‘’换‘成‘’0000‘’
s = novels[‘字数 ‘] num = list(s) new_num = [] n = novels[‘总点击‘] click = list(n) new_click = [] for item in num: if "." in item and "万" in item: new_num.append(int(item.replace(".", "").replace("万", "0000"))) else: new_num.append(int(item)) novels[‘字数 ‘] = new_num for item in click: if "." in item and "万" in item: new_click.append(int(item.replace(".", "").replace("万", "0000"))) else: new_click.append(int(item)) novels[‘总点击 ‘] = new_click
3.文本分析(可选):jieba分词、wordcloud可视化
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
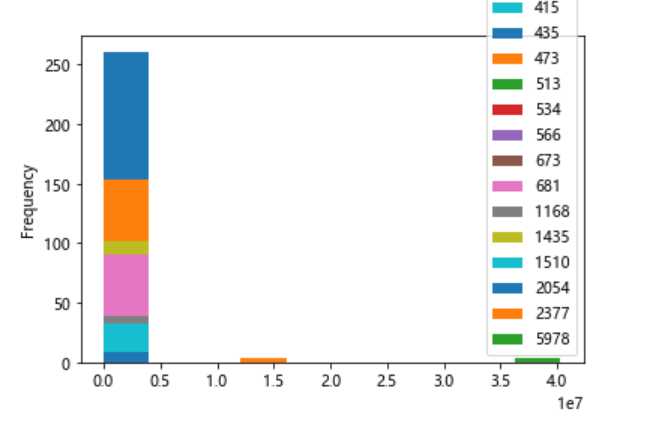
书名、总推荐和总点击的透视表用来查看这个网站是否有热度以及热度的程度
df_povit = novels.pivot_table(index="书名", columns="总推荐", values="总点击") df_povit.plot(kind="hist") df_povit.plot()
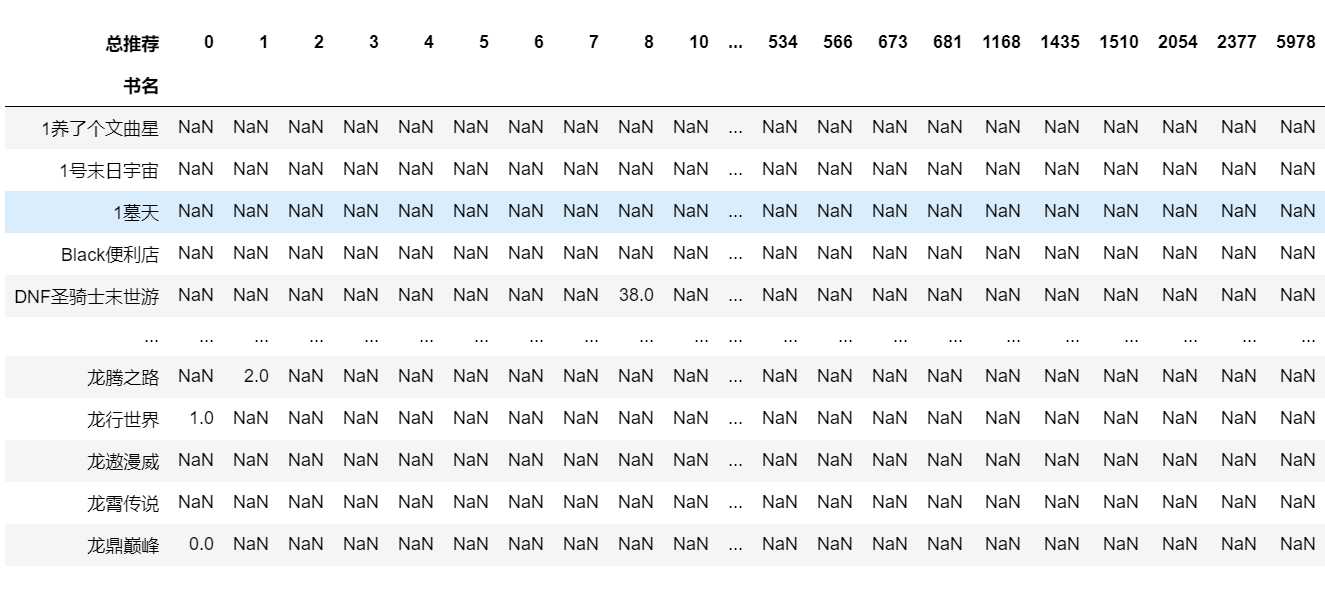
#数据可视化 df_povit.plot(kind="hist")
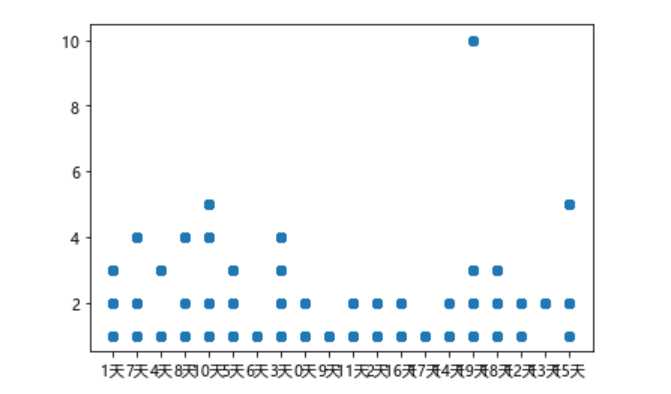
用每月更新和作品总数的散点图可以观察小说网站的作者活不活跃
#数据可视化散点图 plt.scatter(novels[‘每月更新‘], novels[‘作品总数‘])
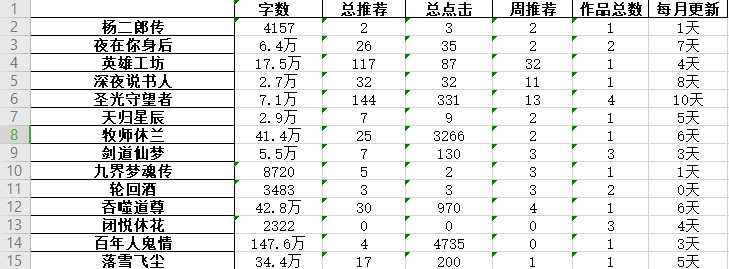
5.数据持久化
爬取到的数据存到Excel
#数据持久化 df.to_excel(‘novel.xlsx‘)
四、结论
1.经过对主题数据的分析与可视化,可以得到哪些结论?
这个小说网站热度不是很高
总推荐出现了好多NAN,说明总推荐高的书都没啥点击量也就是没什么人看
我们可以利用爬虫来找到点击高的书或者适合你要求的书
由散点图我们可以看出这个网站的作者的月更新天数头和尾都多,说明勤奋的很勤奋,没写的就没怎么写
2..对本次程序设计任务完成的情况做一个简单的小结。
本次作业,将所学的知识都有用上,感觉良好,中间处理“字数”这个数据的时候,发现自己之前在字数的而后面加了一个空格,处理就一直报错,后来发现加上空格才处理完成,希望自己通过这次的作业能更大的强化自己的技能
标签:response 图片 unicode cap exce ade www odi 链接
原文地址:https://www.cnblogs.com/w1476880339/p/12074928.html