标签:持久化 一点 柱形图 ons dict pytho 字体 response describe
Python高级应用程序设计任务要求
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
爬取去哪儿所有攻略帖子数据及其分析
2.主题式网络爬虫爬取的内容与数据特征分析
A、爬虫的内容
文章连接、标题、发布者、发布者的个人标签、出发日期、天数、拍照数量、出行的类型、旅行的标签、途经、行程路线、人均消费、观看数、点赞数、评论数
B、数据特征分析
b1、旅游天数分布图分图
b2、拍照数量分布图
b3、出行类型分布图
b4、各种出行方式人均消费箱型图
b5、对出行天数、拍照数量、人均消费、观看数、点赞数和评论数进行相关性分析
b6、人均消费价格和观看数的散点图分析
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
A、实现思路
首先通过 get_page()方法获取网页的源码,然后通过 parse_page()方法提取所需要爬取的数据,将其设置为字典的格式,本文这里所采用的提取所用的工具是 bs4 中的 BeautifulSoup,使用的方法是 find 和find_all 方法,最后将爬取到的数据存储到 csv 文件之中。
B、技术难点
在数据提取的过程之中,存在有一定的难点,在爬取部分汉字内容时只能爬取下汉字所对应拼音内容。
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
本文爬取了共两百页数据,其中每页包含 10 条数据,总计两千条数据。
2.Htmls页面解析
需要爬取网站的数据如图所示:

3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
本文获得网页源码之后,主要是运用 BeautifulSoup 中的 find 和 find_all 来获取所需要的数据,节点部分如下图所示:
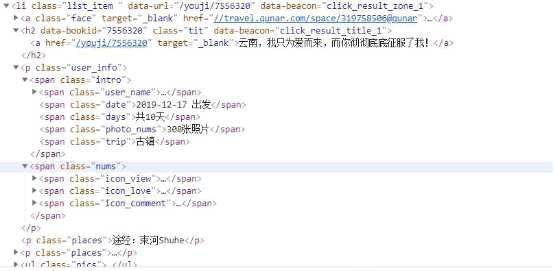
可以看出,每条数据都在一个 li 标签下,因此使用 BeautifulSoup提取较为方便。
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
爬虫代码如下所示:
# !/usr/bin/env python # -*- coding:utf-8-*- import requests from bs4 import BeautifulSoup import csv headers = {‘User-Agent‘:‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36‘} #获取网页源码 def get_page(url): response = requests.get(url,headers = headers) if response.status_code == 200: return response.text return None #提取所需要爬取的数据 def parse_page(html): soup = BeautifulSoup(html,‘lxml‘) #使用BeautifulSoup来解析网页 tables = soup.find_all(‘li‘,class_ = ‘list_item‘) #每个数据所存储的节点位置 #对每个节点遍历循环 for table in tables: datas = {} datas[‘url‘] = ‘https://travel.qunar.com‘ + table.h2.a.get(‘href‘) datas[‘title‘] = table.h2.a.get_text() describe = table.h2.p datas[‘username‘] = table.find(class_ = ‘user_name‘).a.get_text() label = table.find(class_ = ‘user_name_icon‘) if label: datas[‘label‘] = label.get(‘title‘) datas[‘date‘] = table.find(class_ = ‘date‘).get_text().replace(‘出发‘,‘‘) datas[‘days‘] = table.find(class_ = ‘days‘).get_text().replace(‘共‘,‘‘).replace(‘天‘,‘‘) datas[‘photo_nums‘] = table.find(class_ = ‘photo_nums‘).get_text().replace(‘张照片‘,‘‘) people = table.find(class_ = ‘people‘) if people: datas[‘people‘] = people.get_text() trip = table.find(class_ = ‘trip‘) if trip: datas[‘trip‘] = trip.get_text().replace(‘\xa0‘,‘,‘) places = table.find_all(class_ = ‘places‘) if places: datas[‘via_places‘] = places[0].get_text().replace(‘途经:‘,‘‘) if len(places) == 2: datas[‘distance‘] = places[1].get_text().replace(‘行程:‘,‘‘) price = table.find(class_ = ‘fee‘) if price: datas[‘price‘] = price.get_text().replace(‘人均‘,‘‘).replace(‘元‘,‘‘) view_nums = table.find(class_ = ‘icon_view‘).get_text().replace(‘\ue09d‘,‘‘) if ‘万‘ in view_nums: datas[‘view_nums‘] = float(view_nums.replace(‘万‘,‘‘)) * 10000 else: datas[‘view_nums‘] = view_nums datas[‘praise_nums‘] = table.find(class_ = ‘icon_love‘).get_text().replace(‘\uf04f‘,‘‘) datas[‘comment_nums‘] = table.find(class_ = ‘icon_comment‘).get_text().replace(‘\uf060‘,‘‘) yield datas #设置csv文件的标题 def write_csv_header(fileheader): with open("qunaer.csv", "a", newline=‘‘,encoding = ‘utf-8‘) as csvfile: writer = csv.DictWriter(csvfile, fileheader) writer.writeheader() #将获取到的数据保存到csv def save_to_csv(result,fileheader): with open("qunaer.csv", "a", newline=‘‘,encoding = ‘utf-8‘) as csvfile: print(‘正在保存‘) writer = csv.DictWriter(csvfile, fieldnames=fileheader) writer.writerow(result) if __name__ == ‘__main__‘: fileheader = [‘url‘,‘title‘,‘username‘,‘label‘,‘date‘,‘days‘,‘photo_nums‘,‘people‘,‘trip‘,‘via_places‘,‘distance‘,‘price‘,‘view_nums‘,‘praise_nums‘,‘comment_nums‘] write_csv_header(fileheader) for page in range(1,201): #爬取200页 url = ‘https://travel.qunar.com/travelbook/list.htm?page=‘ + str(page) + ‘&order=hot_heat‘ html = get_page(url) datas = parse_page(html) for data in datas: save_to_csv(data,fileheader)
2.对数据进行清洗和处理
在爬取数据的过程中,已经对数据做了一定的的清洗工作,如所其他的文章链接中不全,给他前面加上 https://travel.qunar.com,出发日期中的出发二字剔除,只取其中的日期部分,人均消费中如果含有万字,则删掉万字,并在原来数值的基础之上乘以 10000,天数中的共和天二字剔除,只取具体的天数部分,拍照数量中剔除张照片的字样,只取具体的拍照数量等。其中部分数据的某些指标为空值,但是不影响接下来继续分析。
3.文本分析(可选):jieba分词、wordcloud可视化
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
导包
import pandas as pd import matplotlib.pyplot as plt import seaborn as sns
获取数据
#防止matplotlib中文乱码 plt.rcParams[‘font.sans-serif‘] = [‘KaiTi‘] # 指定默认字体 plt.rcParams[‘axes.unicode_minus‘] = False #读取数据 data = pd.read_csv(‘qunaer.csv‘)
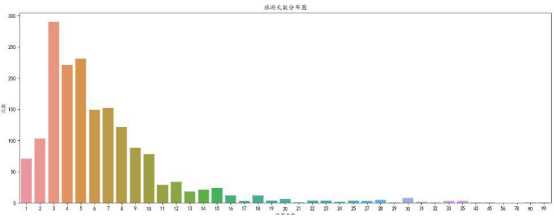
A、旅游天数分布图:
实现代码如下所示:
#旅游天数分布图 date_count = data.groupby(‘days‘)[‘people‘].count().to_frame().reset_index() _,ax = plt.subplots(figsize = (15,6)) sns.barplot(x = ‘days‘,y = ‘people‘,data = date_count,ax = ax ) ax.set_title(‘旅游天数分布图‘) ax.set_xlabel(‘旅游天数‘) ax.set_ylabel(‘次数‘) plt.show()
所得到的分布图如下图所示:
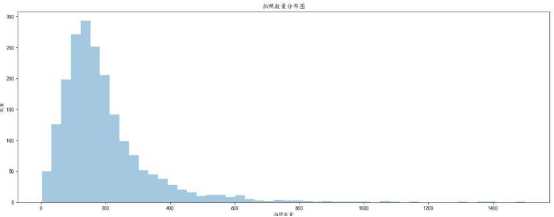
B、拍照数量分布图
代码如下图所示:
#拍照数量分布图 _,ax = plt.subplots(figsize = (15,6)) sns.distplot(data[‘photo_nums‘],kde = False,ax = ax) ax.set_title(‘拍照数量分布图‘) ax.set_xlabel(‘拍照数量‘) ax.set_ylabel(‘数量‘) plt.show()
所得到的分布图如下所示:
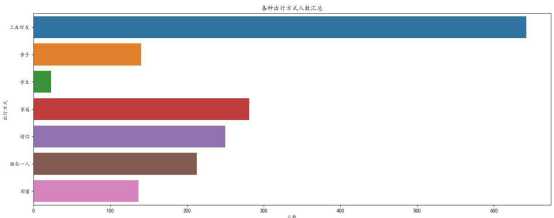
C、出行类型分布图
代码如下图所示:
data_people = data.groupby(‘people‘)[‘trip‘].count().to_frame().reset_index() _,ax = plt.subplots(figsize = (15,6)) sns.barplot(x = ‘trip‘,y = ‘people‘,data = data_people,orient = ‘h‘,ax = ax) ax.set_title(‘各种出行方式人数汇总‘) ax.set_xlabel(‘人数‘) ax.set_ylabel(‘出行方式‘) plt.show()
所得到的分布图如下所示:
D、各种出行方式人均消费箱型图
代码如下图所示:
_,ax = plt.subplots(figsize = (15,6)) sns.boxplot(x = ‘people‘,y = ‘price‘,data = data,ax = ax) ax.set_title(‘各种出行方式人均消费箱型图‘) ax.set_xlabel(‘出行方式‘) ax.set_ylabel(‘人均消费‘) plt.show()
所得到的箱型图如下图所示:
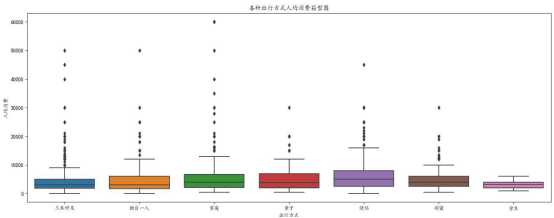
E、对出行天数、拍照数量、人均消费、观看数、点赞数和评论数进行相关性分析,并作热力图可视化
代码如下图所示:
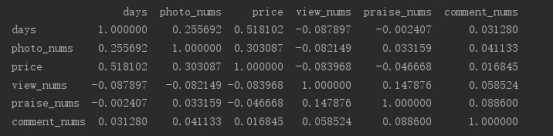
#相关性分析 select_data = data[[‘days‘,‘photo_nums‘,‘price‘,‘view_nums‘,‘praise_nums‘,‘comment_nums‘]] corr = select_data.corr() print(corr) sns.heatmap(corr) plt.show()
得到的相关性矩阵如下图所示:
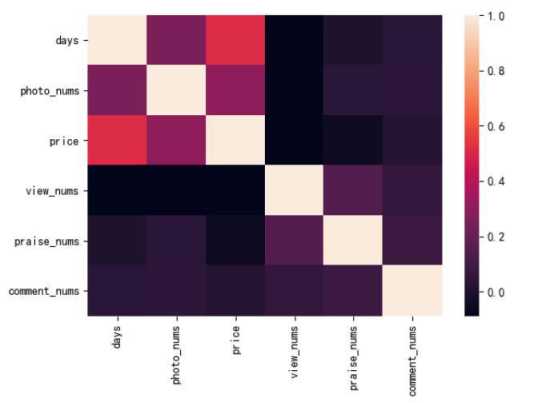
所得到的热力图如下图所示:
F、人均消费价格和观看数的散点图分析
代码如下图所示:
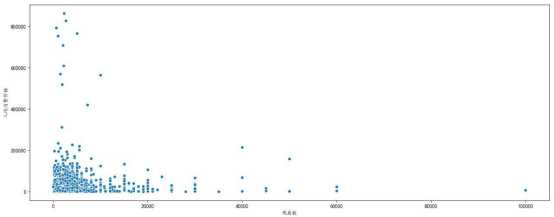
#散点图 _,ax = plt.subplots(figsize = (15,6)) sns.scatterplot(data[‘price‘],data[‘view_nums‘],ax = ax) ax.set_xlabel(‘观看数‘) ax.set_ylabel(‘人均消费价格‘) plt.show()
所得到的散点图如下图所示:
5.数据持久化
将爬取到的数据以 csv 文件的格式存储起来,这样方便用 pandas 进行读取和分析。保存的数据格式如图所示:

6.附完整程序代码
# !/usr/bin/env python # -*- coding:utf-8-*- import requests from bs4 import BeautifulSoup import csv import pandas as pd import matplotlib.pyplot as plt import seaborn as sns headers = {‘User-Agent‘:‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36‘} #获取网页源码 def get_page(url): response = requests.get(url,headers = headers) if response.status_code == 200: return response.text return None #提取所需要爬取的数据 def parse_page(html): soup = BeautifulSoup(html,‘lxml‘) #使用BeautifulSoup来解析网页 tables = soup.find_all(‘li‘,class_ = ‘list_item‘) #每个数据所存储的节点位置 #对每个节点遍历循环 for table in tables: datas = {} datas[‘url‘] = ‘https://travel.qunar.com‘ + table.h2.a.get(‘href‘) datas[‘title‘] = table.h2.a.get_text() describe = table.h2.p datas[‘username‘] = table.find(class_ = ‘user_name‘).a.get_text() label = table.find(class_ = ‘user_name_icon‘) if label: datas[‘label‘] = label.get(‘title‘) datas[‘date‘] = table.find(class_ = ‘date‘).get_text().replace(‘出发‘,‘‘) datas[‘days‘] = table.find(class_ = ‘days‘).get_text().replace(‘共‘,‘‘).replace(‘天‘,‘‘) datas[‘photo_nums‘] = table.find(class_ = ‘photo_nums‘).get_text().replace(‘张照片‘,‘‘) people = table.find(class_ = ‘people‘) if people: datas[‘people‘] = people.get_text() trip = table.find(class_ = ‘trip‘) if trip: datas[‘trip‘] = trip.get_text().replace(‘\xa0‘,‘,‘) places = table.find_all(class_ = ‘places‘) if places: datas[‘via_places‘] = places[0].get_text().replace(‘途经:‘,‘‘) if len(places) == 2: datas[‘distance‘] = places[1].get_text().replace(‘行程:‘,‘‘) price = table.find(class_ = ‘fee‘) if price: datas[‘price‘] = price.get_text().replace(‘人均‘,‘‘).replace(‘元‘,‘‘) view_nums = table.find(class_ = ‘icon_view‘).get_text().replace(‘\ue09d‘,‘‘) if ‘万‘ in view_nums: datas[‘view_nums‘] = float(view_nums.replace(‘万‘,‘‘)) * 10000 else: datas[‘view_nums‘] = view_nums datas[‘praise_nums‘] = table.find(class_ = ‘icon_love‘).get_text().replace(‘\uf04f‘,‘‘) datas[‘comment_nums‘] = table.find(class_ = ‘icon_comment‘).get_text().replace(‘\uf060‘,‘‘) yield datas #设置csv文件的标题 def write_csv_header(fileheader): with open("qunaer.csv", "a", newline=‘‘,encoding = ‘utf-8‘) as csvfile: writer = csv.DictWriter(csvfile, fileheader) writer.writeheader() #将获取到的数据保存到csv def save_to_csv(result,fileheader): with open("qunaer.csv", "a", newline=‘‘,encoding = ‘utf-8‘) as csvfile: print(‘正在保存‘) writer = csv.DictWriter(csvfile, fieldnames=fileheader) writer.writerow(result) if __name__ == ‘__main__‘: fileheader = [‘url‘,‘title‘,‘username‘,‘label‘,‘date‘,‘days‘,‘photo_nums‘,‘people‘,‘trip‘,‘via_places‘,‘distance‘,‘price‘,‘view_nums‘,‘praise_nums‘,‘comment_nums‘] write_csv_header(fileheader) for page in range(1,201): #爬取200页 url = ‘https://travel.qunar.com/travelbook/list.htm?page=‘ + str(page) + ‘&order=hot_heat‘ html = get_page(url) datas = parse_page(html) for data in datas: save_to_csv(data,fileheader) #防止matplotlib中文乱码 plt.rcParams[‘font.sans-serif‘] = [‘KaiTi‘] # 指定默认字体 plt.rcParams[‘axes.unicode_minus‘] = False #读取数据 data = pd.read_csv(‘qunaer.csv‘) #旅游天数分布图 date_count = data.groupby(‘days‘)[‘people‘].count().to_frame().reset_index() _,ax = plt.subplots(figsize = (15,6)) sns.barplot(x = ‘days‘,y = ‘people‘,data = date_count,ax = ax ) ax.set_title(‘旅游天数分布图‘) ax.set_xlabel(‘旅游天数‘) ax.set_ylabel(‘次数‘) plt.show() #拍照数量分布图 _,ax = plt.subplots(figsize = (15,6)) sns.distplot(data[‘photo_nums‘],kde = False,ax = ax) ax.set_title(‘拍照数量分布图‘) ax.set_xlabel(‘拍照数量‘) ax.set_ylabel(‘数量‘) plt.show() #出行方式分布图 data_people = data.groupby(‘people‘)[‘trip‘].count().to_frame().reset_index() _,ax = plt.subplots(figsize = (15,6)) sns.barplot(x = ‘trip‘,y = ‘people‘,data = data_people,orient = ‘h‘,ax = ax) ax.set_title(‘各种出行方式人数汇总‘) ax.set_xlabel(‘人数‘) ax.set_ylabel(‘出行方式‘) plt.show() #各种出行方式人均消费箱型图 _,ax = plt.subplots(figsize = (15,6)) sns.boxplot(x = ‘people‘,y = ‘price‘,data = data,ax = ax) ax.set_title(‘各种出行方式人均消费箱型图‘) ax.set_xlabel(‘出行方式‘) ax.set_ylabel(‘人均消费‘) plt.show() #相关性分析 select_data = data[[‘days‘,‘photo_nums‘,‘price‘,‘view_nums‘,‘praise_nums‘,‘comment_nums‘]] corr = select_data.corr() print(corr) sns.heatmap(corr) plt.show() #散点图 _,ax = plt.subplots(figsize = (15,6)) sns.scatterplot(data[‘price‘],data[‘view_nums‘],ax = ax) ax.set_xlabel(‘观看数‘) ax.set_ylabel(‘人均消费价格‘) plt.show()
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
a、通过对旅游天数的分布图分析,我们可以看出,大多数都是处于十天之内的,人们更偏好于短期旅游。
b、通过对拍照数量分布图进行可视化分析,可以得出大部分拍照数量处于 50-250 之间。
c、通过对出行类型类型的分布图进行可视化分析,可以看到三五好友的出行方式是最多的,其他像家庭,情侣,亲子的不少,因此可以得出人们更愿意结伴出游。
d、通过对各种出行方式人均消费箱型图进行可视化分析,可以看到以家庭、亲子、情侣的出行方式相对其他出行方式,人均消费更高。
e、相关性分析:通过对六个数值指标计算其相关系数矩阵,可以得出人均消费价格和出行天数之间存在较强的相关关系,平且两者之间具有正相关,拍照数量和出行天数也有一定的关系,但是其相关性相对较弱一点。
f、通过对人均消费价格和观看数的散点图的可视化分析,可以看出两者之间存在一定的正相关关系,但是相关性关系较弱。
2.对本次程序设计任务完成的情况做一个简单的小结。
通过这次的程序设计任务,我边编写边探索,实践、丰富了很多有关爬虫和数据分析相关的知识,更加明白了Python这门语言的便捷与乐趣,很感谢老师对这次实践作业的教导与陪伴,我会在将来的生活中逐渐用好这门神奇的课程。
标签:持久化 一点 柱形图 ons dict pytho 字体 response describe
原文地址:https://www.cnblogs.com/eddieG/p/12073055.html