标签:auto object tool nump mpi 完整 handle des exist
Python高级应用程序设计任务要求
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
去哪儿网攻略信息爬取
2.主题式网络爬虫爬取的内容与数据特征分析
爬取内容:文章链接、标题、简要秒速信息、发布者、发布者个人标签、出发日期、天数、拍照数量、出行的类型、旅行的标签、途经、行程路线、人均消费、观看数、点赞数、评论数
数据特征分析:
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
实现思路:编写 HandleQuNar 类,HandleQuNar 类中 __init__ () 初始化方法,初始化爬虫过程中的 User-Agent;handle_travel()方法对url迭代,采用requests库的get()获取对应的html网页,利用BeautifulSoup的find_all方法获取每一页的10个li进行遍历,利用find等方法获取标签内相应的文本并对获取的数据进行处理。每爬取完一个li(攻略信息),将其设置成字典的格式,调用save()方法进行保存;save()方法将数据存储到csv文件中;process_num()方法对爬取下来的部分数据进行处理;handle_request()方法用于返回url对应的html文本;—main—方法用于执行程序。
技术难点:对数据的处理有一定的难点
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
共200页,每页有10条 li 对应着每一个攻略信息,通过查看网页源代码,发现每页都是静态页面,无ajax、js产生的动态数据
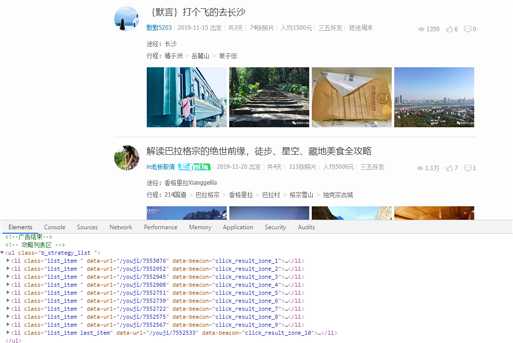
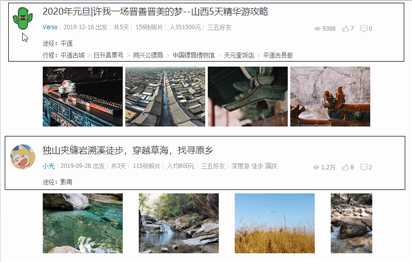
2.Htmls页面解析
图示中黑色框内为需爬取的数据。
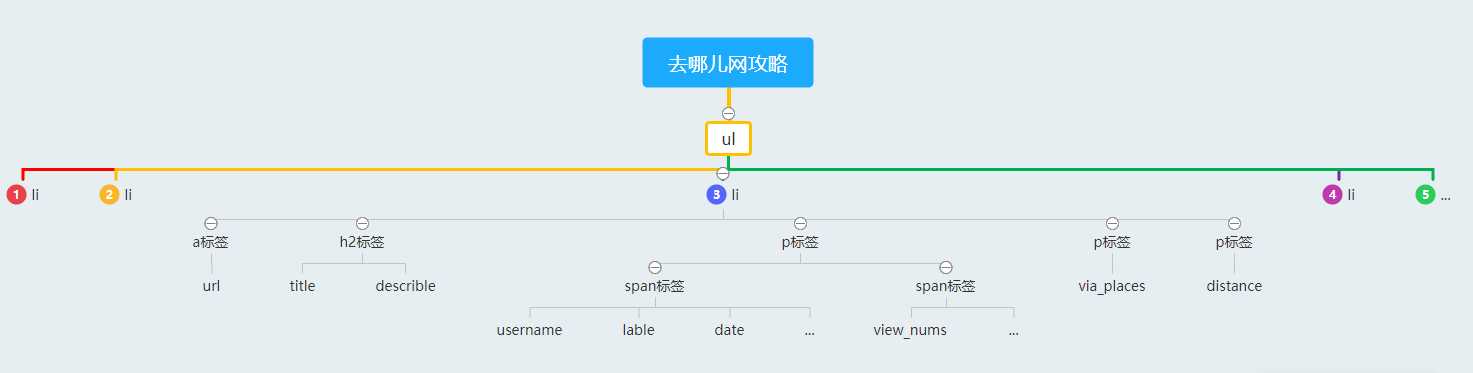
3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
爬取采用request库和BeautifulSoup库,利用BeautifulSoup的find_all方法获取每一页的10个li进行遍历,利用find等方法获取标签内相应的文本并对获取的数据进行处理。
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
import requests import re from bs4 import BeautifulSoup from fake_useragent import UserAgent from datetime import datetime from urllib import parse import os from pandas import DataFrame class HnadleQuNar(object): ‘‘‘定义标头‘‘‘ def __init__(self): self.headers = { "User-Agent": UserAgent().random } ‘‘‘定义qunar_data.csv的路径‘‘‘ file_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), ‘qunar_data.csv‘) def handle_travel(self): ‘‘‘ 解析去哪儿网的攻略信息 对于大部分字段用try-except,如果无相关字段,将以‘‘保存 ‘‘‘ for i in range(1, 201): ‘‘‘对200页的数据进行爬取‘‘‘ travelbook_url = "https://travel.qunar.com/travelbook/list.htm?page=%d&order=hot_heat"%(i) travelbook_result = self.handle_request(method="GET", url=travelbook_url) soup = BeautifulSoup(travelbook_result , "html.parser" , from_encoding="utf-8") print("正在爬取:{}".format(travelbook_url)) lis = soup.find_all("li", class_="list_item")#获取所有相关的li节点 for li in lis:#遍历每一页的li节点 ‘‘‘获取url信息‘‘‘ url = li.find("h2").find(‘a‘)["href"] url = parse.urljoin(‘https://travel.qunar.com‘, url) ‘‘‘获取title信息‘‘‘ try: title = li.find("h2").find(‘a‘).get_text() except: title = ‘‘ try: describle = li.find("h2").find(‘p‘)[‘class‘][1] except: describle = ‘‘ spans = li.find_all("span", class_="intro") for span in spans: ‘‘‘获取发布者的用户名信息‘‘‘ try: username = span.find("span").find("a",href=re.compile(r"space")).get_text() except: username = ‘‘ ‘‘‘获取发布者的个人标签‘‘‘ try: label = span.find("span").find_all("a") label = label[1].find("span")["title"] except: label = ‘‘ ‘‘‘获取出发日期‘‘‘ try: startdate = span.find("span", class_="date").get_text() startdate = re.findall(r‘(\d+-\d+-\d+)‘ , startdate)[0] startdate = datetime.strptime(startdate, "%Y-%m-%d") except: startdate = ‘‘ ‘‘‘获取天数‘‘‘ days = span.find("span",class_="days").get_text() days = re.findall(r"\d+",days)[0] days = int(days) ‘‘‘获取照片数量‘‘‘ photo_nums = span.find("span", class_="photo_nums").get_text() photo_nums = int(re.findall(r"\d+", photo_nums)[0]) ‘‘‘获取人均消费‘‘‘ try: price = span.find("span", class_="fee").get_text() price = int(re.findall(r"\d+",price)[0]) except: price = 0 ‘‘‘获取出行人员的类型‘‘‘ try: people = span.find("span", class_="people").get_text() except: people = ‘‘ ‘‘‘获取旅行的标签‘‘‘ try: trip = span.find("span", class_="trip").get_text() except: trip = ‘‘ ‘‘‘ 获取旅行的途经 获取旅行的行程路线 ‘‘‘ try: places = li.find_all("p", class_="places")
# 因途经或行程路线有为空的可能,所以在此做一个逻辑判断 if(len(places)!=0): for i in range(len(places)): if(len(places) == 2): if(i==0): via_places =places[i].get_text() else: distance = places[i].get_text() elif(len(places)==1): if("途经" in places[i].get_text()): via_places = places[i].get_text() distance = ‘‘ else: distance = places[i].get_text() via_places = ‘‘ else: via_places = ‘‘ distance = ‘‘ except: via_places = ‘‘ distance = ‘‘ ‘‘‘获取该行程的观看数‘‘‘ view_nums = li.find("p", class_="user_info").find("span",class_="nums").find("span").find("span").get_text() view_nums = self.process_num(view_nums) ‘‘‘获取该行程的点赞数‘‘‘ praise_nums = li.find("p", class_="user_info").find("span", class_="nums").find("span",class_="icon_love").find("span").get_text() praise_nums = self.process_num(praise_nums) ‘‘‘获取该行程的评论数‘‘‘ comment_nums = li.find("p", class_="user_info").find("span", class_="nums").find("span",class_="icon_comment").find("span").get_text() comment_nums = self.process_num(comment_nums) # 写入到csv文件 df = DataFrame({ "url": [url], "title": [title], "describle": [describle], "username": [username], "label": [label], "date": [startdate], "days": [days], "photo_nums": [photo_nums], "people": [people], "trip": [trip], "via_places": [via_places], "distance": [distance], "price": [price], "view_nums": [view_nums], "praise_nums": [praise_nums], "comment_nums": [comment_nums] }) ‘‘‘利用save()将攻略信息保存‘‘‘ self.save(df) def save(self,df): ‘‘‘ 将数据写入csv ‘‘‘ # 若文件已存在,将以追加的形势存入csv文件中 if (os.path.exists(self.file_path)): df.to_csv(self.file_path, header=False, index=False, mode="a+", encoding="utf_8_sig") else: df.to_csv(self.file_path, index=False, mode="w+", encoding="utf_8_sig") def process_num(self,value): ‘‘‘ 将例如点赞数,观看数的一些数据格式化 ‘‘‘ if("万" in value): value = float(re.search(r"\d+\.{0,1}\d{0,}",value)[0]) value = int(value*10000) else: value = int(re.search(r"\d+\.{0,1}\d{0,}",value)[0]) return value def handle_request(self,method,url,data=None,info=None): if method == "GET": response = requests.get(url=url,headers = self.headers) try: response.raise_for_status() #状态码 response.encoding = ‘UTF-8‘ #定义编码格式 return response.text #获取对于的html文本 except Exception as e: raise e else: pass ‘‘‘主函数‘‘‘ if __name__ == "__main__": qunar = HnadleQuNar() qunar.handle_travel()
1.数据爬取与采集
2.对数据进行清洗和处理
2.1进行导包
import pandas as pd import numpy as np import matplotlib.pyplot as plt from datetime import datetime
from mpl_toolkits. mplot3d import Axes3D
2.2获取数据所保存的csv文件
qunar = pd.read_csv(r"D:\Python\qunar_data.csv")
2.3查看数据前5行
qunar.head()

2.4查看数据分布情况
qunar.shape

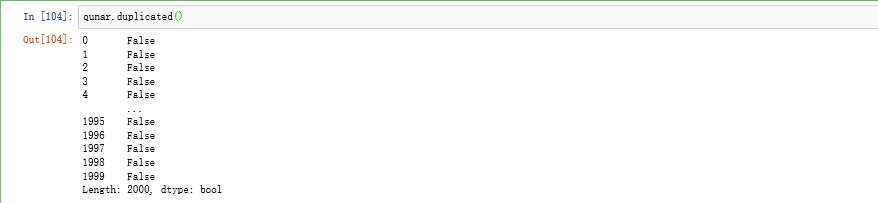
2.5查看是否存在重复值
qunar.duplicated()
2.6去除"username"与"title"的重复值
# "title"、"username"不可存在重复值
qunar[‘username‘].drop_duplicates qunar[‘title‘].drop_duplicates
qunar.head()

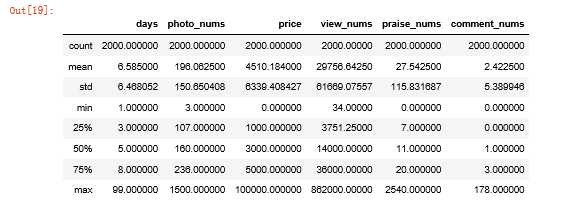
2.7使用describe查看统计信息
qunar.describe()
2.8查看"describle"数据的合计,并将"describle"数据内的拼音转换为中文
qunar[‘describle‘].value_counts()

qunar[‘describle‘] = qunar[‘describle‘].replace("meitu", "美图") qunar[‘describle‘] = qunar[‘describle‘].replace("ganhuo", "干货") qunar[‘describle‘] = qunar[‘describle‘].replace("duantupai", "短途派") qunar[‘describle‘] = qunar[‘describle‘].replace("jinghua", "臻华") qunar[‘describle‘] = qunar[‘describle‘].replace("wenyifan", "文艺范") qunar[‘describle‘].value_counts()

3.文本分析(可选):jieba分词、wordcloud可视化
4.数据分析与可视化
显示正常中文和负号
plt.rcParams[‘font.family‘] = [‘sans-serif‘] plt.rcParams[‘font.sans-serif‘] = [‘SimHei‘] plt.rcParams[‘axes.unicode_minus‘]=False #用来正常显示负号
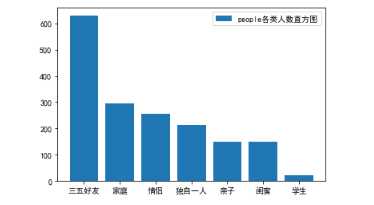
4.1查看出行人员类别的直方图
plt.bar(peoples.index, peoples.values, label="people各类人数直方图") plt.legend() plt.show()
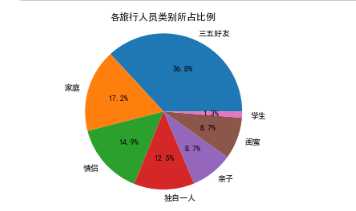
4.2查看各旅行人员类别所占比例
peoples = qunar[‘people‘].value_counts()
Type = peoples.index Data = peoples.values plt.pie(Data ,labels=Type, autopct=‘%1.1f%%‘) plt.axis(‘equal‘) plt.title(‘各旅行人员类别所占比例‘) plt.show()
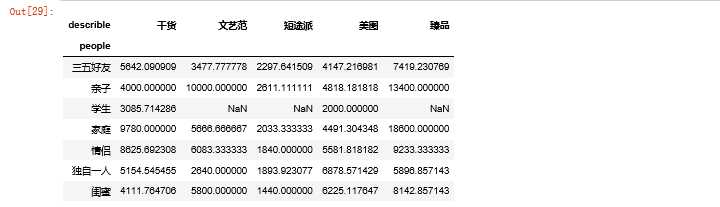
4.3查看"describle"与"people"所对应的人均消费信息并可视化
df_pivot = qunar.pivot_table(index="people", columns="describle", values="price") df_pivot.shape df_pivot
df_pivot.plot(kind=‘bar‘, title=‘people and price‘) plt.xlabel(‘people‘) plt.ylabel(‘price‘)
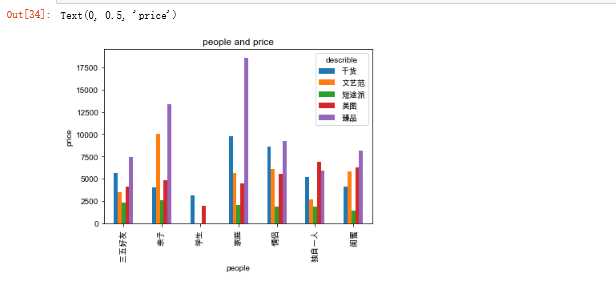
4.4查看去哪儿各月份攻略信息的旅游量
for i in range(len(qunar[‘date‘])): qunar[‘date‘][i] = qunar[‘date‘][i].replace(qunar[‘date‘][i],qunar[‘date‘][i][5:7]) dates = qunar[‘date‘].value_counts() plt.bar(dates.index, dates.values, label="各月份攻略信息的旅游量") plt.legend() plt.show()
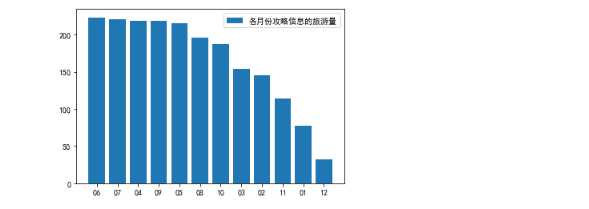
4.5查看出行天数、人均消费、观看人数的3D散点图
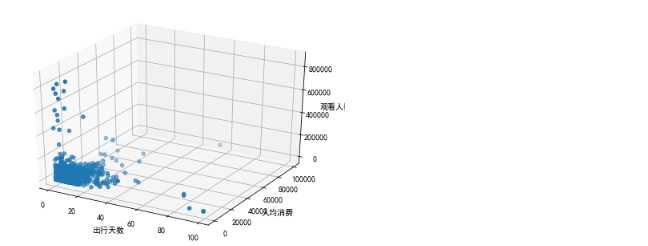
fig = plt.figure() ax = Axes3D(fig) x = np.array(qunar[‘days‘]) y = np.array(qunar[‘price‘]) z = np.array(qunar[‘view_nums‘]) ax. scatter(x, y, z) ax.set_xlabel(‘出行天数‘) ax.set_ylabel( ‘人均消费‘ ) ax.set_zlabel(‘观看人数‘ ) plt.show()
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
5.数据持久化
将爬下来的数据存入csv文件中,以实现数据持久化
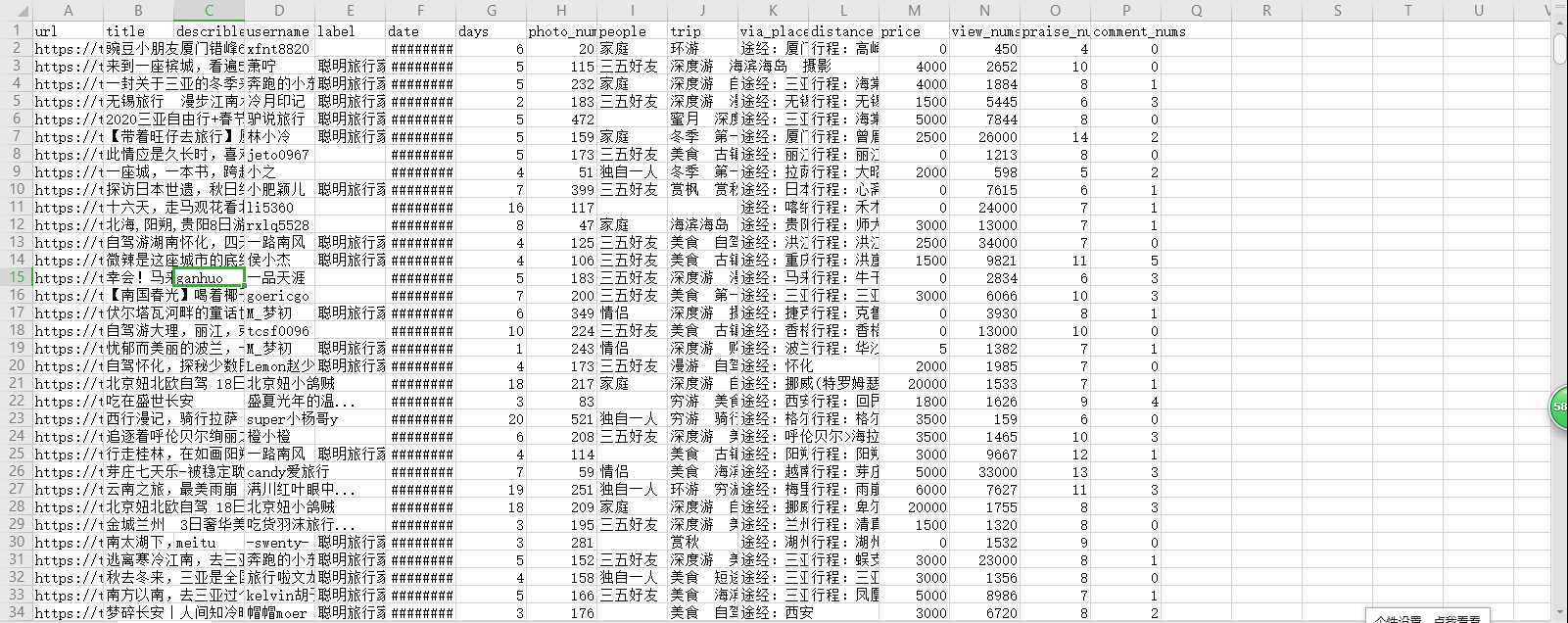
6.完整代码
1 import requests 2 import re 3 from bs4 import BeautifulSoup 4 from fake_useragent import UserAgent 5 from datetime import datetime 6 from urllib import parse 7 import os 8 from pandas import DataFrame 9 import pandas as pd 10 import numpy as np 11 import matplotlib.pyplot as plt 12 from datetime import datetime 13 from mpl_toolkits. mplot3d import Axes3D 14 15 class HnadleQuNar(object): 16 ‘‘‘定义标头‘‘‘ 17 def __init__(self): 18 self.headers = { 19 "User-Agent": UserAgent().random 20 } 21 ‘‘‘定义qunar_data.csv的路径‘‘‘ 22 file_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), ‘qunar_data.csv‘) 23 def handle_travel(self): 24 ‘‘‘ 25 解析去哪儿网的攻略信息 26 对于大部分字段用try-except,如果无相关字段,将以‘‘保存 27 ‘‘‘ 28 for i in range(1, 201): 29 ‘‘‘对200页的数据进行爬取‘‘‘ 30 travelbook_url = "https://travel.qunar.com/travelbook/list.htm?page=%d&order=hot_heat"%(i) 31 travelbook_result = self.handle_request(method="GET", url=travelbook_url) 32 soup = BeautifulSoup(travelbook_result , "html.parser" , from_encoding="utf-8") 33 print("正在爬取:{}".format(travelbook_url)) 34 lis = soup.find_all("li", class_="list_item")#获取所有相关的li节点 35 for li in lis:#遍历每一页的li节点 36 ‘‘‘获取url信息‘‘‘ 37 url = li.find("h2").find(‘a‘)["href"] 38 url = parse.urljoin(‘https://travel.qunar.com‘, url) 39 ‘‘‘获取title信息‘‘‘ 40 try: 41 title = li.find("h2").find(‘a‘).get_text() 42 except: 43 title = ‘‘ 44 45 try: 46 describle = li.find("h2").find(‘p‘)[‘class‘][1] 47 except: 48 describle = ‘‘ 49 spans = li.find_all("span", class_="intro") 50 for span in spans: 51 ‘‘‘获取发布者的用户名信息‘‘‘ 52 try: 53 username = span.find("span").find("a",href=re.compile(r"space")).get_text() 54 except: 55 username = ‘‘ 56 ‘‘‘获取发布者的个人标签‘‘‘ 57 try: 58 label = span.find("span").find_all("a") 59 label = label[1].find("span")["title"] 60 except: 61 label = ‘‘ 62 ‘‘‘获取出发日期‘‘‘ 63 try: 64 startdate = span.find("span", class_="date").get_text() 65 startdate = re.findall(r‘(\d+-\d+-\d+)‘ , startdate)[0] 66 startdate = datetime.strptime(startdate, "%Y-%m-%d") 67 except: 68 startdate = ‘‘ 69 ‘‘‘获取天数‘‘‘ 70 days = span.find("span",class_="days").get_text() 71 days = re.findall(r"\d+",days)[0] 72 days = int(days) 73 ‘‘‘获取照片数量‘‘‘ 74 photo_nums = span.find("span", class_="photo_nums").get_text() 75 photo_nums = int(re.findall(r"\d+", photo_nums)[0]) 76 ‘‘‘获取人均消费‘‘‘ 77 try: 78 price = span.find("span", class_="fee").get_text() 79 price = int(re.findall(r"\d+",price)[0]) 80 except: 81 price = 0 82 ‘‘‘获取出行人员的类型‘‘‘ 83 try: 84 people = span.find("span", class_="people").get_text() 85 except: 86 people = ‘‘ 87 ‘‘‘获取旅行的标签‘‘‘ 88 try: 89 trip = span.find("span", class_="trip").get_text() 90 except: 91 trip = ‘‘ 92 ‘‘‘ 93 获取旅行的途经 94 获取旅行的行程路线 95 ‘‘‘ 96 try: 97 places = li.find_all("p", class_="places") 98 if(len(places)!=0): 99 for i in range(len(places)): 100 if(len(places) == 2): 101 if(i==0): 102 via_places =places[i].get_text() 103 else: 104 distance = places[i].get_text() 105 elif(len(places)==1): 106 if("途经" in places[i].get_text()): 107 via_places = places[i].get_text() 108 distance = ‘‘ 109 else: 110 distance = places[i].get_text() 111 via_places = ‘‘ 112 else: 113 via_places = ‘‘ 114 distance = ‘‘ 115 except: 116 via_places = ‘‘ 117 distance = ‘‘ 118 ‘‘‘获取该行程的观看数‘‘‘ 119 view_nums = li.find("p", class_="user_info").find("span",class_="nums").find("span").find("span").get_text() 120 view_nums = self.process_num(view_nums) 121 ‘‘‘获取该行程的点赞数‘‘‘ 122 praise_nums = li.find("p", class_="user_info").find("span", class_="nums").find("span",class_="icon_love").find("span").get_text() 123 praise_nums = self.process_num(praise_nums) 124 ‘‘‘获取该行程的评论数‘‘‘ 125 comment_nums = li.find("p", class_="user_info").find("span", class_="nums").find("span",class_="icon_comment").find("span").get_text() 126 comment_nums = self.process_num(comment_nums) 127 # 写入到csv文件 128 df = DataFrame({ 129 "url": [url], 130 "title": [title], 131 "describle": [describle], 132 "username": [username], 133 "label": [label], 134 "date": [startdate], 135 "days": [days], 136 "photo_nums": [photo_nums], 137 "people": [people], 138 "trip": [trip], 139 "via_places": [via_places], 140 "distance": [distance], 141 "price": [price], 142 "view_nums": [view_nums], 143 "praise_nums": [praise_nums], 144 "comment_nums": [comment_nums] 145 }) 146 ‘‘‘利用save()将攻略信息保存‘‘‘ 147 print(df) 148 self.save(df) 149 150 def save(self,df): 151 ‘‘‘ 152 将数据写入csv 153 ‘‘‘ 154 # 如果文件已经存在了,追加的形式写入文件,且不设置columns 155 if (os.path.exists(self.file_path)): 156 # 字符编码采用utf-8-sig,因为存在表情包 157 df.to_csv(self.file_path, header=False, index=False, mode="a+", encoding="utf_8_sig") 158 else: 159 df.to_csv(self.file_path, index=False, mode="w+", encoding="utf_8_sig") 160 161 def process_num(self,value): 162 ‘‘‘ 163 将例如点赞数,观看数的一些数据格式化 164 ‘‘‘ 165 if("万" in value): 166 value = float(re.search(r"\d+\.{0,1}\d{0,5}",value)[0]) 167 value = int(value*10000) 168 else: 169 value = int(re.search(r"\d+\.{0,1}\d{0,5}",value)[0]) 170 return value 171 172 def handle_request(self,method,url,data=None,info=None): 173 if method == "GET": 174 response = requests.get(url=url,headers = self.headers) 175 try: 176 response.raise_for_status() #状态码 177 response.encoding = ‘UTF-8‘ #定义编码格式 178 return response.text #获取对于的html文本 179 except Exception as e: 180 raise e 181 else: 182 pass 183 ‘‘‘主函数‘‘‘ 184 if __name__ == "__main__": 185 qunar = HnadleQuNar() 186 qunar.handle_travel() 187 188 189 qunar = pd.read_csv(r"D:\Python\qunar_data.csv") 190 qunar.head()#查看文件前5行 191 qunar.shape#查看文件行列数 192 qunar.duplicated() 193 194 # "title"、"username"不可存在重复值 195 qunar[‘username‘].drop_duplicates 196 qunar[‘title‘].drop_duplicates 197 qunar.head() 198 qunar.describe() 199 200 #将"describle"字段中的拼音改为中文 201 qunar[‘describle‘] = qunar[‘describle‘].replace("meitu", "美图") 202 qunar[‘describle‘] = qunar[‘describle‘].replace("ganhuo", "干货") 203 qunar[‘describle‘] = qunar[‘describle‘].replace("duantupai", "短途派") 204 qunar[‘describle‘] = qunar[‘describle‘].replace("jinghua", "臻华") 205 qunar[‘describle‘] = qunar[‘describle‘].replace("wenyifan", "文艺范") 206 qunar[‘describle‘].value_counts()#修改后的"describle"统计 207 208 #用于正常显示中文和负号 209 plt.rcParams[‘font.family‘] = [‘sans-serif‘] 210 plt.rcParams[‘font.sans-serif‘] = [‘SimHei‘] 211 plt.rcParams[‘axes.unicode_minus‘]=False 212 213 #查看出行人员类别的直方图 214 peoples = qunar[‘people‘].value_counts() 215 plt.bar(peoples.index, 216 peoples.values, 217 label="people各类人数直方图") 218 plt.legend() 219 plt.show() 220 221 #查看各旅行人员类别所占比例(扇形图) 222 Type = peoples.index 223 Data = peoples.values 224 plt.pie(Data ,labels=Type, autopct=‘%1.1f%%‘) 225 plt.axis(‘equal‘) 226 plt.title(‘各旅行人员类别所占比例‘) 227 plt.show() 228 229 #查看"describle"与"people"所对应的人均消费透视表并可视化 230 df_pivot = qunar.pivot_table(index="people", columns="describle", values="price") 231 df_pivot.shape 232 df_pivot.plot(kind=‘bar‘, title=‘people and price‘) 233 plt.xlabel(‘people‘) 234 plt.ylabel(‘price‘) 235 236 #查看去哪儿各月份攻略信息的旅游量 237 for i in range(len(qunar[‘date‘])): 238 qunar[‘date‘][i] = qunar[‘date‘][i].replace(qunar[‘date‘][i],qunar[‘date‘][i][5:7]) 239 dates = qunar[‘date‘].value_counts() 240 plt.bar(dates.index, 241 dates.values, 242 label="各月份攻略信息的旅游量") 243 plt.legend() 244 plt.show() 245 246 #查看出行天数、人均消费、观看人数的3D散点图 247 fig = plt.figure() 248 ax = Axes3D(fig) 249 x = np.array(qunar[‘days‘]) 250 y = np.array(qunar[‘price‘]) 251 z = np.array(qunar[‘view_nums‘]) 252 ax. scatter(x, y, z) 253 ax.set_xlabel(‘出行天数‘) 254 ax.set_ylabel( ‘人均消费‘ ) 255 ax.set_zlabel(‘观看人数‘ ) 256 plt.show()
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
1.1通过对出行人员类别的可视图分析,可以看出,去哪儿攻略中大多数的出行人员类别都是“”三五好友“”,攻略中所占比例为36.5%。而出行人员类别中的"学生"在攻略中是最少的。攻略中所占比例为1.3%.
1.2通过对"describle"与"people"所对应的人均消费信息并可视图分析,在人均消费中,属出行类别为"家庭",描述类别为"精品"的人均消费最高。而类别为"学生"的人均消费都较低。同时也可以看出:出行描述中,"精品"的人均消费最高,"短途派"的人均消费最低。出行类别中,"家庭"、"亲子"人均消费较其他出行类别人均消费更高。
1.3通过对去哪儿各月份攻略信息的旅游量可视图分析,可以看出,旅游攻略中,大多数的出行时间为4-10月份,其中6月的旅游量最高,12月份的旅游量最低。
1.4通过对出行天数、人均消费、观看人数的3D散点图分析,可以看出出行天数和人均消费存在正相关,其他之间存在较弱的相关性。
2.对本次程序设计任务完成的情况做一个简单的小结。
通过这次的爬虫任务以及数据分析,了解了更多关于爬虫的技巧和知识,也发现了对这方面还需要补充很多的知识,’需要查缺补漏,更深层的掌握爬虫技术。
标签:auto object tool nump mpi 完整 handle des exist
原文地址:https://www.cnblogs.com/wuzezong/p/11992040.html