标签:tps 详细 获取 函数 结果 com 柱形图 解析 网页数据
这次爬虫主要是爬取58同城泉州区域的房屋交易价格和房屋信息。
实现思路:获取58同城目标的HTML页面,使用requests爬取数据,BeautifulSoup解析页面,使用records进行数据存储、读取,最后打印出来数据
技术难点:爬取数据,遍历标签属性。存储数据表格信息
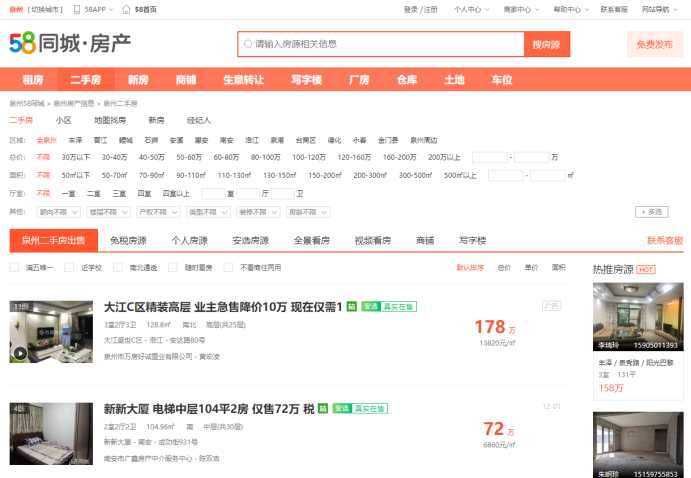

用鼠标右键点击查看“查看元素”选项或者按“F12”

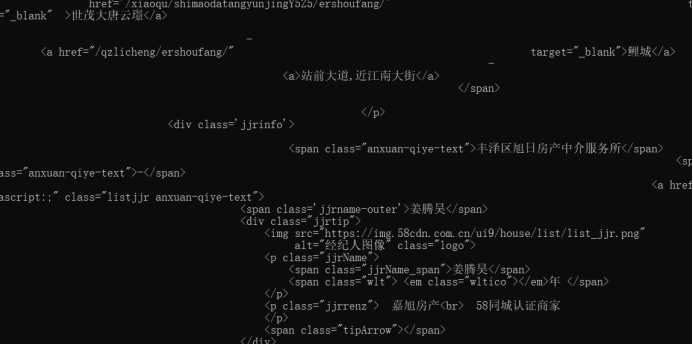
查找:select函数

遍历:for循环嵌套





import requests
from bs4 import BeautifulSoup
import records
def getHtml(url):
‘‘‘
获取目标网页数据
‘‘‘
try:
# 伪装UA
ua = {‘user-agent‘: ‘Mozilla/5.0 Chrome/79.0.3945.88 Safari/537.36‘}
# 读取网页
r = requests.get(url, headers=ua)
# 获取状态
r.raise_for_status()
# 打印数据 print(r.text)
# 返回数据
return r.text
except:
return "Fail"
def parseHtml(html):
‘‘‘
房屋数据收集
‘‘‘
# 数据数组
data = []
# 结构解析
soup = BeautifulSoup(html, "html.parser")
# 获取具体房屋的链接
titles = soup.select(‘.title a‘)
print(titles)
# for循环解析链接
for i in titles:
# 解析href链接属性
a = i.get(‘href‘)
# 打印数据 print(a)
# 加入数组
data.append(a)
# 返回数组
return data
def parseInfo(html):
‘‘‘
房屋数据清洗
‘‘‘
# 创建字典
j = {}
# 结构解析
soup = BeautifulSoup(html, "html.parser")
# 获取房屋标题
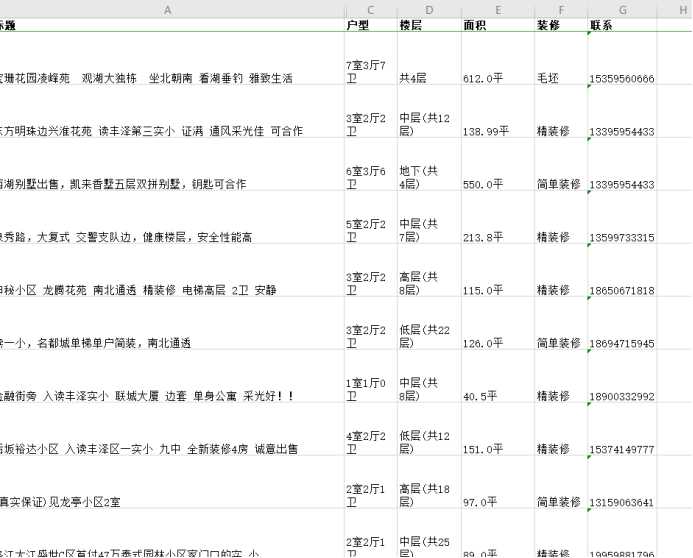
titles = soup.select(‘.f20‘)[0].get_text()
# 获取房屋价格
price = soup.select(‘.house-basic-info .price‘)[0].get_text()
# 获取房屋户型
huxing = soup.select(‘.house-basic-info .room .main‘)[0].get_text()
# 获取房屋楼层
louceng = soup.select(‘.house-basic-info .room .sub‘)[0].get_text()
# 获取房屋面积
mianji = soup.select(‘.house-basic-info .area .main‘)[0].get_text()
# 获取房屋装修
maopi = soup.select(‘.house-basic-info .area .sub‘)[0].get_text()
# 获取联系电话
phone = soup.select(‘.phone-num‘)[0].get_text()
# 组合数据
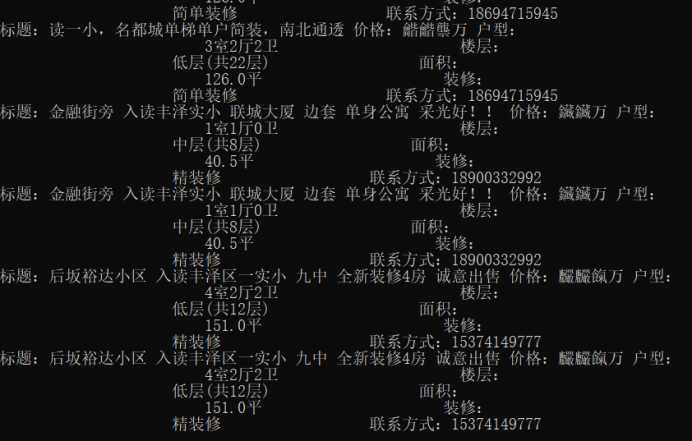
sj = ‘标题:%s 价格:%s 户型:%s 楼层:%s 面积:%s 装修:%s 联系方式:%s ‘%(titles,price,huxing,louceng,mianji,maopi,phone)
# 打印数据
print(sj)
# 字典
j[‘标题‘] = titles
j[‘价格‘] = price
j[‘户型‘] = huxing
j[‘楼层‘] = louceng
j[‘面积‘] = mianji
j[‘装修‘] = maopi
j[‘联系‘] = phone
# 返回字典
return j
# 采集
urls = parseHtml(getHtml(‘https://qz.58.com/ershoufang/pn1/‘))
# 数组
data = []
# 循环
for i in urls:
# 房屋数据清洗
sj = parseInfo(getHtml(i))
# 打印数据 print(sj)
# 加入成员
data.append(sj)
# 数据保存
results = records.RecordCollection(iter(data))
with open(‘house.xlsx‘, ‘wb‘) as f:
# 写入
f.write(results.export(‘xlsx‘))
标签:tps 详细 获取 函数 结果 com 柱形图 解析 网页数据
原文地址:https://www.cnblogs.com/chenxinyuy/p/12076156.html