标签:应用 exists rip div 内容 str write 网络爬虫 from
一,主题式网络爬虫设计方案
1,主题式网络爬虫的名称
1.1虎扑球星网站的爬取
2,主题式网络爬虫的内容与数据特征分析
2.1爬虫的内容
球队,球员名称, 身高,体重,年薪, 位置, 出生年月日
2.2 数据特征分析
2.2.1对球员的身高体重做一个散点图
3,主题式网络爬虫设计方案概述(包括实现思路和技术难点)
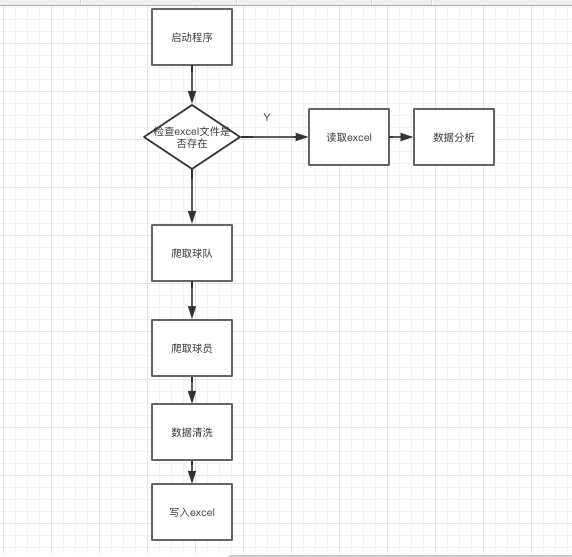
3.1实现思路
创建一个球队的类和一个球员的累,定义master()方法作为启动程序,由于球员数据是一个相对稳定的数据, excel文件生成一次后不需要在另外进行生成, 所以通过pathlib.Path的方法检查excel文件是否存在,如果存在直接读取进行数据分析, 网站内容使用requests 和 beautifulsoup进行抓取,具体如下图解。
3.2技术难点
爬取过程中并未遇到阻拦,既不需要设置header, 也没遇到在爬取过程中被重定向到登录页面(整个爬取5-6分钟)。
二,主题页面的结构特征分析
1,主题页面的特征结构
总共6个赛区,每个赛区5只球队, 每只球队人数大约15人,通过查看接口详情,发现接口数据都是静态数据,直接通过分析网页的Dom数据就可以完成爬取,首先爬取球队信息,然后根据球队的href地址取抓取对应的球员数据
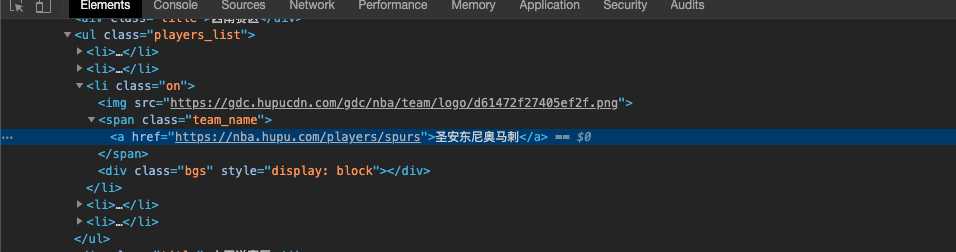
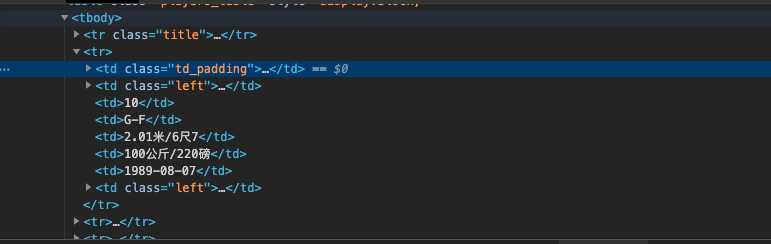
2,HTML页面解析
<span class="team_name"> 球队标签
<table class="players_table" style="display:block;"> <tbody> <tr class="title"> <td width="102"></td> <td width="110">姓名</td> <td width="30">号码</td> <td width="40">位置</td> <td width="75">身高</td> <td width="70">体重</td> <td width="70">生日</td> <td width="105">合同</td> </tr> </tbody> </table>
这部分是截取的部分球员数据和球队标签

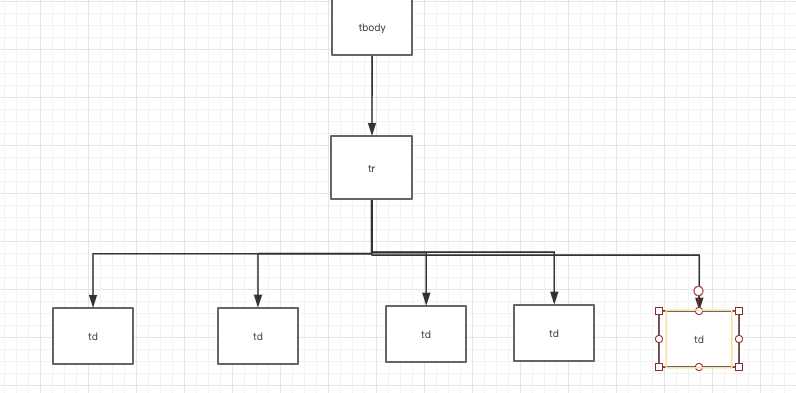
3,节点(标签)查找方法与遍历发法(必要时画出节点数结构)
查找节点的方法采用beautifoulSoup的元素选择器,通过find,select等内置方法来来提取所需要的数据。从整体(tbody)到部分(tr)的查找方式,即先确定爬取的数据所在哪个html的节点中,找到这个节点的所有直接子节点,也就是每一个攻略项,再用for循环依次遍历,然后再具体解析遍历的每一项攻略的数据,图解如下。
三,网络爬虫程序设计
1,爬虫程序主题要包括以下部分,要附源代码及较详解注释,并在每部分程序后面提供输出结果的截图。
import requests from bs4 import BeautifulSoup import openpyxl import pathlib import numpy as np import matplotlib.pyplot as plt def write_to_excel(players): book_name = "nba球员.xlsx" sheet_name = "nba球员" columns = ["球队", "姓名", "号码", "位置", "身高", "体重", "生日", "薪水"] path = pathlib.Path(book_name) is_new = False # 检查文件是否存在, 不存在的创建一个文件 if not path.exists(): workbook = openpyxl.Workbook() sheet = workbook.active # 设置sheet的名称 sheet.title = sheet_name index = 1 is_new = True else: return # 球员数据不需要更新 # workbook = openpyxl.load_workbook(book_name) # sheet = workbook[sheet_name] # sheet.title = sheet_name # index = sheet.max_row # 插入标题栏 if is_new: for i in range(0, len(columns)): sheet.cell(index, i + 1, columns[i]) for value in players: index += 1 sheet.cell(index, 1, value.team) sheet.cell(index, 2, value.name) sheet.cell(index, 3, value.number) sheet.cell(index, 4, value.location) sheet.cell(index, 5, value.height) sheet.cell(index, 6, value.weight) sheet.cell(index, 7, value.birthday) sheet.cell(index, 8, value.salary) workbook.save(book_name) class Player: def __init__(self, team): self.team = team self.name = "" self.number = "" self.location = "" self.height = "" self.weight = "" self.salary = "" self.birthday = "" class Team: def __init__(self, team, href): self.name = team self.href = href def get_players(self): print("获取球员数据" + self.name) response = requests.get(self.href) if response.status_code != 200: print("http error, url: %s, code: %d" % (self.href, response.status_code)) return ct = response.headers["Content-Type"].split("charset=")[1].lower() bs4 = BeautifulSoup(response.content, features="html.parser", from_encoding=ct) player_list = bs4.select("table.players_table > tbody > tr") players = [] for pt in player_list: if pt.has_attr("class") and pt["class"][0] == "title": continue pd = pt.find_all("td") player = Player(self.name) for index, p in enumerate(pd): if p.has_attr("class") and p["class"][0] == "td_padding": continue if index == 1: player.name = "".join(p.get_text()) elif index == 2: player.number = p.get_text().strip() elif index == 3: player.location = p.get_text().strip() elif index == 4: player.height = p.get_text().strip() elif index == 5: player.weight = p.get_text().strip() elif index == 6: player.birthday = p.get_text().strip() else: player.salary = p.select_one("b").get_text().strip().split("本年薪金:")[1] players.append(player) return players def master(): base = "https://nba.hupu.com/players" response = requests.get(base) if response.status_code != 200: print("http error, url: %s, code: %d" % (base, response.status_code)) return ct = response.headers["Content-Type"].split("charset=")[1].lower() bs4 = BeautifulSoup(response.content, features="html.parser", from_encoding=ct) team_list = bs4.select("ul.players_list > li") all = [] for team in team_list: players = [] # 获取球队信息 td = team.find("a") href = td["href"] name = td.get_text() t = Team(name, href) # 爬取队员信息 players.extend(t.get_players()) all.extend(players) write_to_excel(players) if __name__ == "__main__": book_name = "nba球员.xlsx" path = pathlib.Path(book_name) # 爬虫数据不存在爬取数据 if not path.exists(): master() else: read_excel()
2. 对数据进行清洗
2.1. 读取excel文件中的数据
workbook = openpyxl.load_workbook("nba球员.xlsx") ws = workbook.active
? 2.2. 获取最大的列数
col = ws.max_column heights = [] weights = []
2.3 遍历所有的数据
for row in ws.iter_cols(min_col=5, max_col=6, min_row=2, max_row=ws.max_row):
? 2.4 数据清理
if "米" in cell.value: height = cell.value.split("/")[0].split("米")[0] heights.append(height) elif "公斤" in cell.value: weight = cell.value.split("/")[0].split("公斤")[0] weights.append(weight)
? 2.5 画散点图
plt.scatter(heights, weights) plt.axis() plt.title("distribution") plt.xlabel("height/meter") plt.ylabel("weight/kilogram") plt.savefig("./players.png") plt.show()
3.文本分析(可选):jieba分词、wordcloud可视化
4.数据分析与可视化
4.1 根据球员的身高体重绘制散点图
plt.scatter(heights, weights) plt.axis() plt.title("distribution") plt.xlabel("height/meter") plt.ylabel("weight/kilogram") plt.savefig("./players.png") plt.show()
具体截图如下:
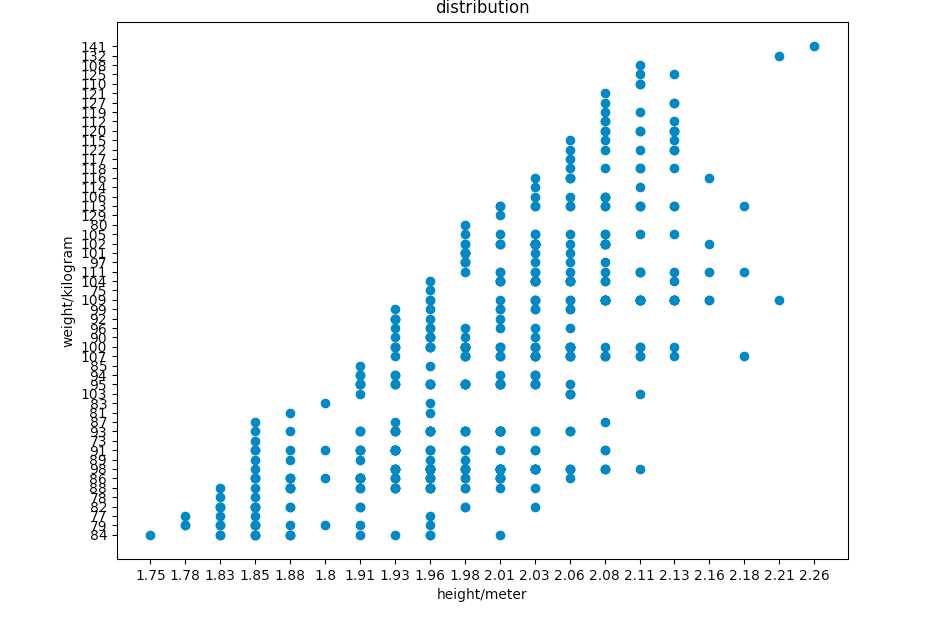
5.数据持久化
写入csv文件
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
1.1 随着球员的身高增长, 体重也会有较大幅度的增长。
1.2 大部分球员的身高分布相对还是比较均匀的。
1.3 每只球队中各个身高和球员的分布情况较为相似。
2.对本次程序设计任务完成的情况做一个简单的小结。
本次作业, 通过运用了学习到的爬虫和数据分析的知识分析了虎扑球员的相关情况,为自己以后工作奠定了基础,同时也在思考了之后比如在多线程或者数据的持久化方面的知识,为自己取得的成就感到高兴
标签:应用 exists rip div 内容 str write 网络爬虫 from
原文地址:https://www.cnblogs.com/l1427856623/p/12070396.html