标签:排名 download param 利用 ram 程序代码 完整 dex 信息
技术难点:openpyxl、matplotlib、scrapy的综合使用。
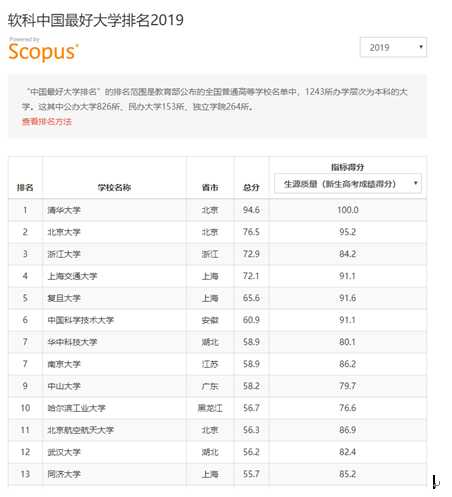
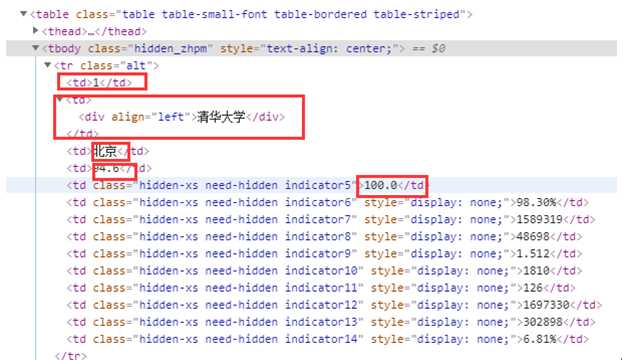
通过Elements分析可知,每一个院校都放在了一个tr中,排名在tr标签的第一个td中,学校名称在tr标签的第二个td标签中,省市在tr标签的第三个td标签中,总分在tr标签的第四个td标签中,指标得分在tr标签的第五个td中。
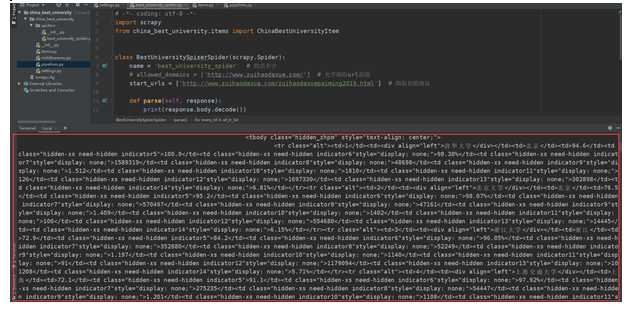
5.数据持久化
本任务是使用scrapy框架完成的
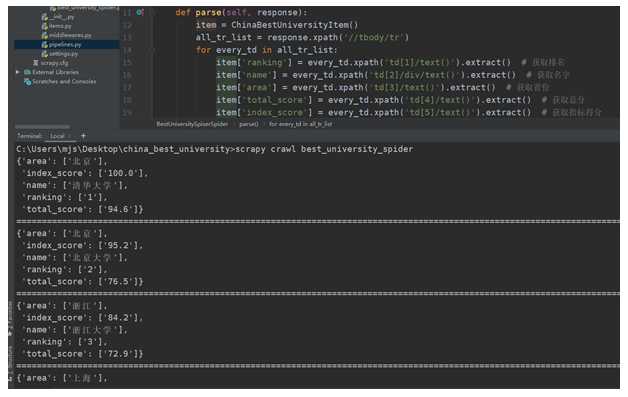
best_university_spider.py中
import scrapy from china_best_university.items import ChinaBestUniversityItem class BestUniversitySpiserSpider(scrapy.Spider): name = ‘best_university_spider‘ # 爬虫名字 start_urls = [‘http://www.zuihaodaxue.com/zuihaodaxuepaiming2019.html‘] # 爬取初始地址 def parse(self, response): item = ChinaBestUniversityItem() all_tr_list = response.xpath(‘//tbody/tr‘) for every_td in all_tr_list: item[‘ranking‘] = every_td.xpath(‘td[1]/text()‘).extract() # 获取排名 item[‘name‘] = every_td.xpath(‘td[2]/div/text()‘).extract() # 获取名字 item[‘area‘] = every_td.xpath(‘td[3]/text()‘).extract() # 获取省份 item[‘total_score‘] = every_td.xpath(‘td[4]/text()‘).extract() # 获取总分 item[‘index_score‘] = every_td.xpath(‘td[5]/text()‘).extract() # 获取指标得分 yield item
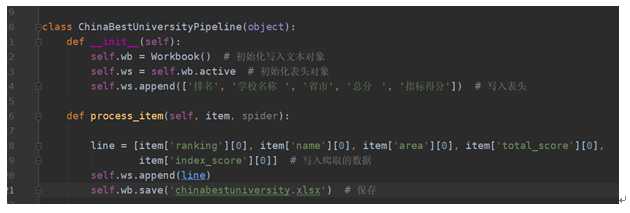
pipelines.py中
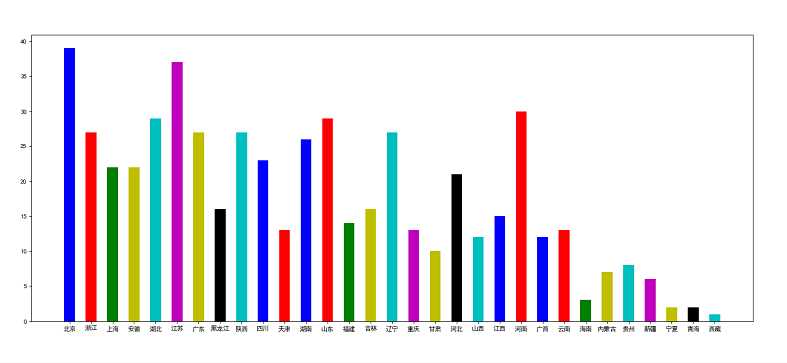
from collections import Counter from matplotlib import pyplot from openpyxl import Workbook list_x = [] class ChinaBestUniversityPipeline(object): def __init__(self): self.wb = Workbook() self.ws = self.wb.active self.ws.append([‘排名‘, ‘学校名称 ‘, ‘省市‘, ‘总分 ‘, ‘指标得分‘]) def process_item(self, item, spider): line = [item[‘ranking‘][0], item[‘name‘][0], item[‘area‘][0], item[‘total_score‘][0], item[‘index_score‘][0]] # 写入爬取的数据 self.ws.append(line) self.wb.save(‘bestunversity.xlsx‘) # 保存 list_x.append(item[‘area‘][0]) # 爬取的数据添加到全局变量的list_x中,用于关闭爬取的close_spider时的数据分析 def close_spider(self, item): global list_x # 解包字典,获取x轴和y轴的数据列表 x = list(Counter(list_x).keys()) y = list(Counter(list_x).values()) print(Counter(list_x)) # 设置matplotlib正常显示中文和负号 pyplot.rcParams[‘font.sans-serif‘] = [‘SimHei‘] pyplot.rcParams[‘axes.unicode_minus‘] = False # 生成画布 pyplot.figure(figsize=(20, 8), dpi=80) # 画图 pyplot.bar(x, y, width=0.5, color=[‘b‘, ‘r‘, ‘g‘, ‘y‘, ‘c‘, ‘m‘, ‘y‘, ‘k‘, ‘c‘, ‘b‘, ‘r‘]) # 保存图片 pyplot.savefig(‘bestunarea.png‘) # 显示图片 pyplot.show()
settings.py中
BOT_NAME = ‘china_best_university‘ SPIDER_MODULES = [‘china_best_university.spiders‘] NEWSPIDER_MODULE = ‘china_best_university.spiders‘ USER_AGENT = ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36‘ ROBOTSTXT_OBEY = False ITEM_PIPELINES = { ‘china_best_university.pipelines.ChinaBestUniversityPipeline‘: 300, # 开启中间件 } LOG_LEVEL = ‘WARNING‘
items.py中
import scrapy class ChinaBestUniversityItem(scrapy.Item): ranking = scrapy.Field() # 排名 name = scrapy.Field() # 名称 area = scrapy.Field() # 省份 total_score = scrapy.Field() # 总分 index_score = scrapy.Field() # 指标得分
最后:打开terminal,输入scrapy crawl best_university_spider,回车,然后我们所想要的结果就有了。
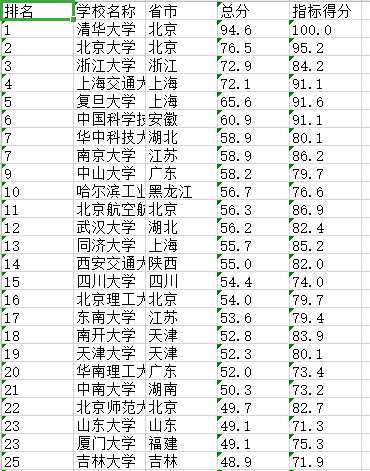
中间省略
标签:排名 download param 利用 ram 程序代码 完整 dex 信息
原文地址:https://www.cnblogs.com/chenxiaofang/p/12076941.html