标签:dir parse 通过 mil 播放量 _for rom excel 循环
技术难点:1.爬取数据提取相关信息 2.遍历过程 3.保存数据至excel表格
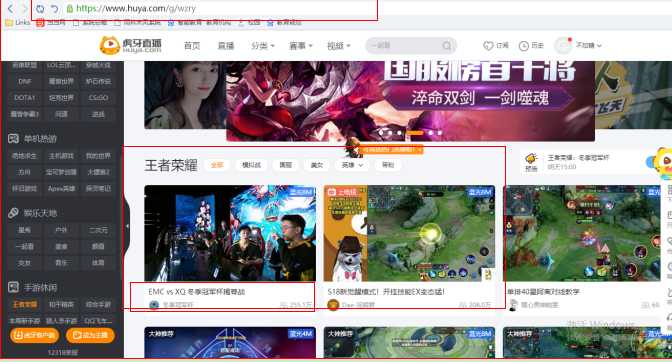

标题信息在class="title new-clickstat"的<a>标签中;
主播名在class="nick"的<i>标签中;
播放量在class="js-num"的<i>标签中。
#爬取虎牙直播视频:王者荣耀 目标的HTML页面 def getHTMLText(url): try: #获取目标页面 r = requests.get(url) #判断页面是否链接成功 r.raise_for_status() #使用HTML页面内容中分析出的响应内容编码方式 r.encoding = r.apparent_encoding #返回页面内容 return r.text except: #如果爬取失败,返回“爬取失败” return "爬取失败" #获取目标信息 def getData(titleList,nameList,numList,html): #创建BeautifulSoup对象 soup = BeautifulSoup(html,"html.parser") #获取标题信息 for a in soup.find_all("a",{"class":"title new-clickstat"}): #将标题信息存在列表中 titleList.append(a.string) #获取主播名字信息 for i in soup.find_all("i",{"class":"nick"}): #将主播名字存在列表中 nameList.append(i.string) #获取播放量 for i in soup.find_all("i",{"class":"js-num"}): #将播放量存在列表中 numList.append(i.string)

#创建文件夹 def makeMkdir(): try: #创建文件夹 os.mkdir("C:\虎牙直播") except: #如果文件夹存在则什么也不做 ""

#获取目标信息 def getData(titleList,nameList,numList,html): #创建BeautifulSoup对象 soup = BeautifulSoup(html,"html.parser") #获取标题信息 for a in soup.find_all("a",{"class":"title new-clickstat"}): #将标题信息存在列表中 titleList.append(a.string) #获取主播名字信息 for i in soup.find_all("i",{"class":"nick"}): #将主播名字存在列表中 nameList.append(i.string) #获取播放量 for i in soup.find_all("i",{"class":"js-num"}): #将播放量存在列表中 numList.append(i.string)
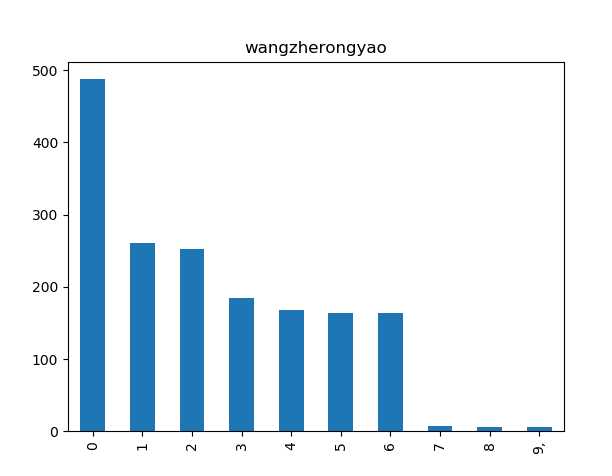
import pandas as pd import numpy as np #excel表格对应序列号 ,主播视频播放量 s=pd.Series([487.7,260.9,253.0,185.1,167.6,164.2,163.7,6.8,5.3,5.8],[‘0‘,‘1‘,‘2‘,‘3‘,‘4‘,‘5‘,‘6;,‘7‘,‘8‘,‘9‘] s.plot(kinf=‘bar‘,title=‘wangzherongyao‘) plt.show

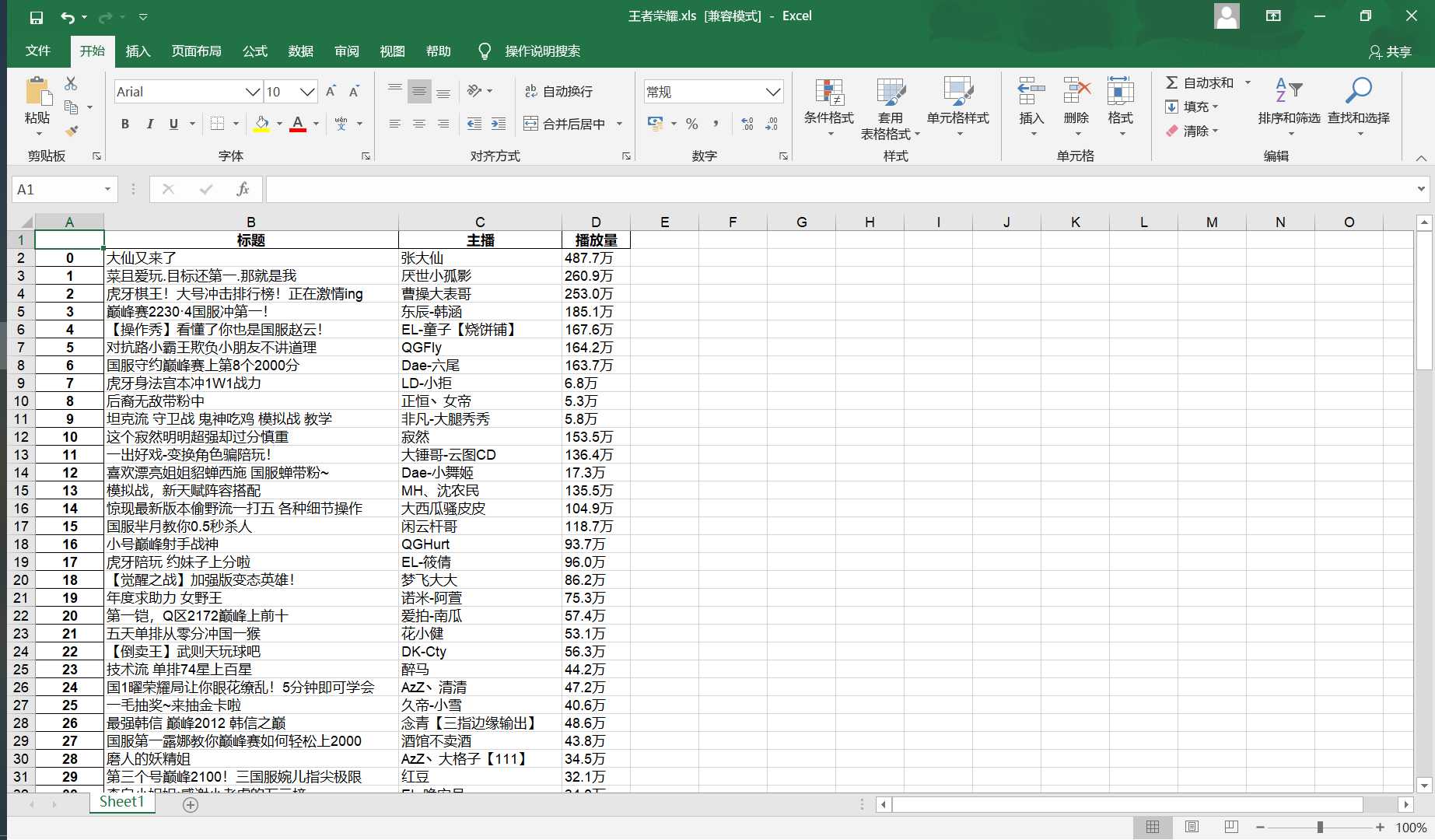
#使用pandas进行数据存储、读取 def pdSaveRead(titleList,nameList,numList): #创建numpy数组 r = np.array([titleList,nameList,numList]) #columns(列)名 columns_title = [‘标题‘,‘主播‘,‘播放量‘] #创建DataFrame数据帧 df = pd.DataFrame(r.T,columns = columns_title) #将数据存在Excel表中 df.to_excel(r‘C:\虎牙直播\王者荣耀.xls‘,columns = columns_title) #读取表中岗位信息 dfr = pd.read_excel(r‘C:\虎牙直播\王者荣耀.xls‘) print(dfr.head()) #用来存放标题的列表 titleList = [] #用来存放主播名字的列表 nameList = [] #用来存放播放量的列表 numList = [] #英雄联盟页面链接 url = "https://www.huya.com/g/wzry" #获取页面html代码 html = getHTMLText(url) #将目标信息存在目标列表中 getData(titleList,nameList,numList,html) #创建文件夹 makeMkdir() #数据存储并打印数据 pdSaveRead(titleList,nameList,numList)
1 import requests 2 from bs4 import BeautifulSoup 3 import pandas as pd 4 import numpy as np 5 import os 6 7 8 #爬取虎牙直播视频:王者荣耀 目标的HTML页面 9 def getHTMLText(url): 10 try: 11 #获取目标页面 12 r = requests.get(url) 13 #判断页面是否链接成功 14 r.raise_for_status() 15 #使用HTML页面内容中分析出的响应内容编码方式 16 r.encoding = r.apparent_encoding 17 #返回页面内容 18 return r.text 19 except: 20 #如果爬取失败,返回“爬取失败” 21 return "爬取失败" 22 23 #获取目标信息 24 def getData(titleList,nameList,numList,html): 25 #创建BeautifulSoup对象 26 soup = BeautifulSoup(html,"html.parser") 27 #获取标题信息 28 for a in soup.find_all("a",{"class":"title new-clickstat"}): 29 #将标题信息存在列表中 30 titleList.append(a.string) 31 #获取主播名字信息 32 for i in soup.find_all("i",{"class":"nick"}): 33 #将主播名字存在列表中 34 nameList.append(i.string) 35 #获取播放量 36 for i in soup.find_all("i",{"class":"js-num"}): 37 #将播放量存在列表中 38 numList.append(i.string) 39 40 #创建文件夹 41 def makeMkdir(): 42 try: 43 #创建文件夹 44 os.mkdir("C:\虎牙直播") 45 except: 46 #如果文件夹存在则什么也不做 47 "" 48 49 #使用pandas进行数据存储、读取 50 def pdSaveRead(titleList,nameList,numList): 51 #创建numpy数组 52 r = np.array([titleList,nameList,numList]) 53 #columns(列)名 54 columns_title = [‘标题‘,‘主播‘,‘播放量‘] 55 #创建DataFrame数据帧 56 df = pd.DataFrame(r.T,columns = columns_title) 57 #将数据存在Excel表中 58 df.to_excel(r‘C:\虎牙直播\王者荣耀.xls‘,columns = columns_title) 59 60 #读取表中岗位信息 61 dfr = pd.read_excel(r‘C:\虎牙直播\王者荣耀.xls‘) 62 print(dfr.head()) 63 64 65 #用来存放标题的列表 66 titleList = [] 67 #用来存放主播名字的列表 68 nameList = [] 69 #用来存放播放量的列表 70 numList = [] 71 #英雄联盟页面链接 72 url = "https://www.huya.com/g/wzry" 73 #获取页面html代码 74 html = getHTMLText(url) 75 #将目标信息存在目标列表中 76 getData(titleList,nameList,numList,html) 77 #创建文件夹 78 79 80 makeMkdir() 81 #数据存储并打印数据 82 pdSaveRead(titleList,nameList,numList)
标签:dir parse 通过 mil 播放量 _for rom excel 循环
原文地址:https://www.cnblogs.com/zoelinvo/p/12078080.html