标签:豆瓣 要求 coding end xls 表格 tis jieba分词 image
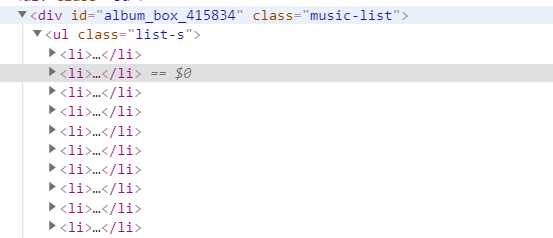
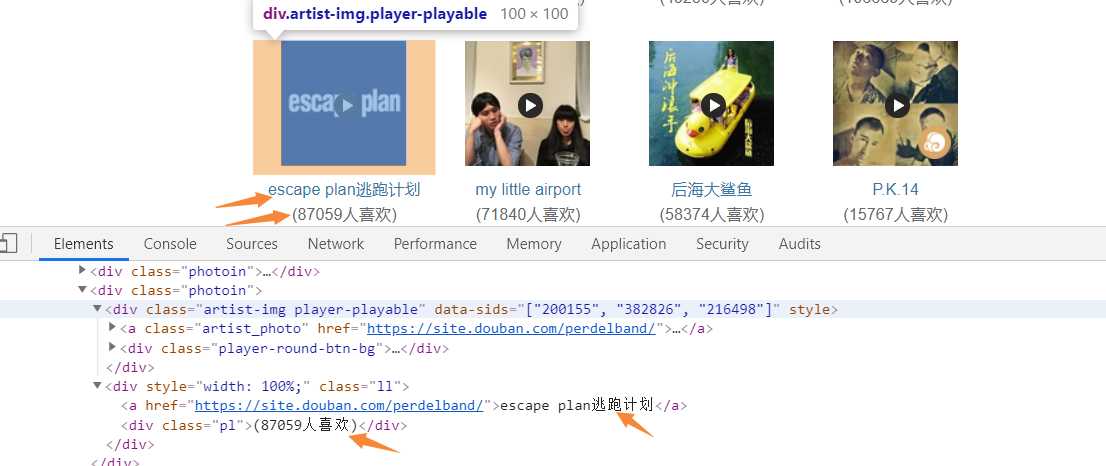
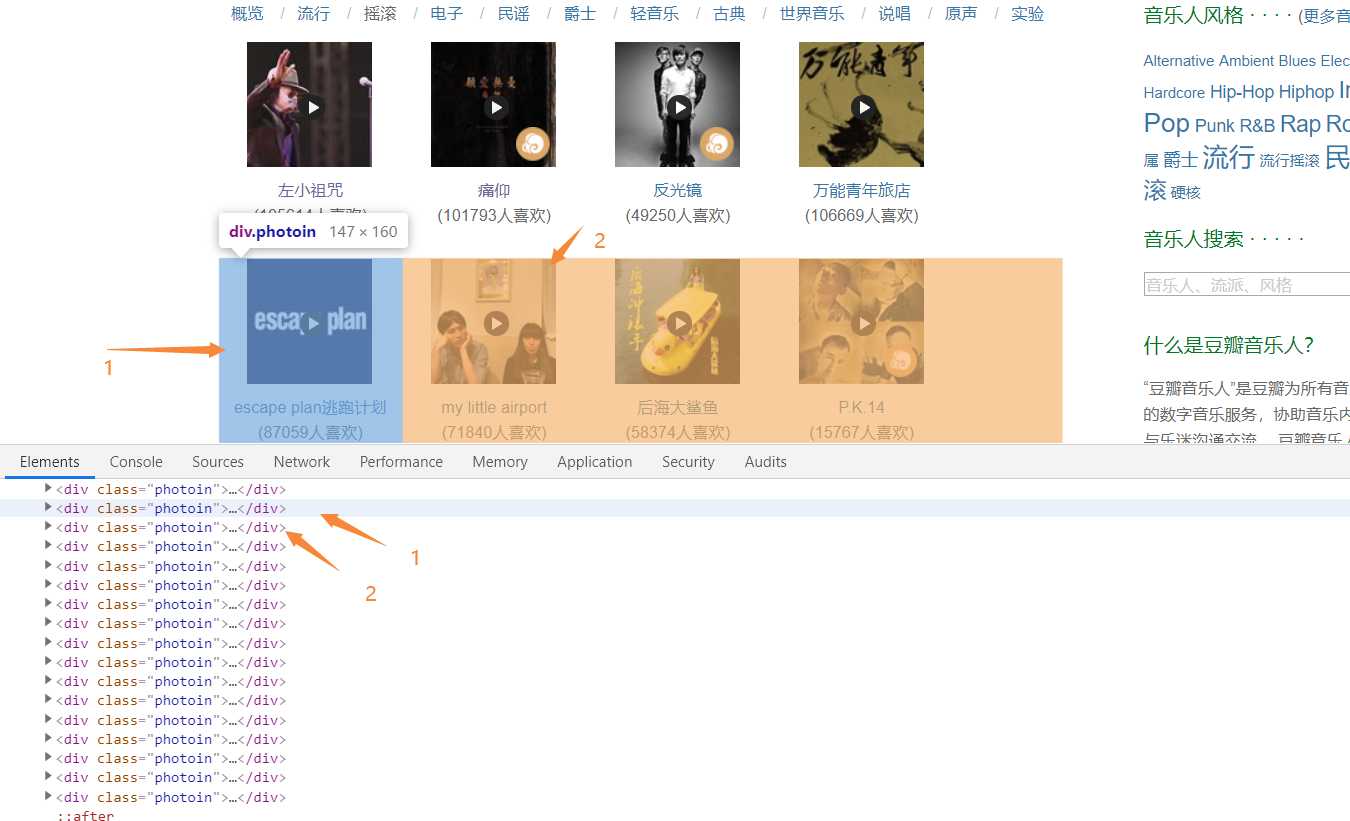
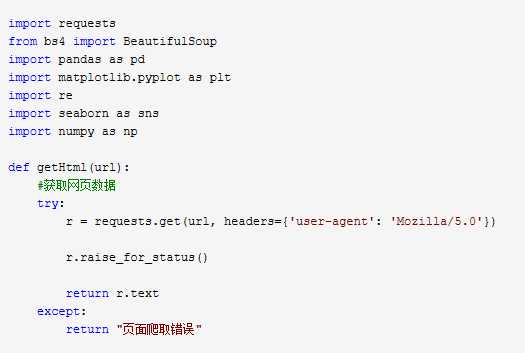
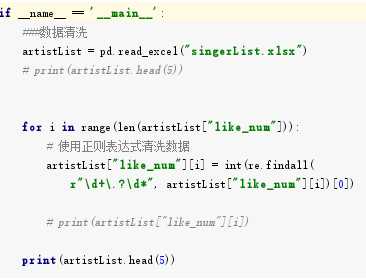
# -*- coding: utf-8 -*- import requests from bs4 import BeautifulSoup import pandas as pd import matplotlib.pyplot as plt import re import seaborn as sns import numpy as np def getHtml(url): #获取网页数据 try: r = requests.get(url, headers={‘user-agent‘: ‘Mozilla/5.0‘}) r.raise_for_status() return r.text except: return "页面爬取错误" def beautifulSoup(html, artistList): List = [] #使用BeautifulSoup类解析html文本 soup = BeautifulSoup(html, "html.parser") clearfix = soup.find_all("div", "clearfix")[1] # 爬取列表标签 photoins = clearfix.find_all("div", "photoin") # 循环列表 for photoin in photoins: div = photoin.find("div", "ll") # 歌手 singer_name = div.find("a").text # 链接 singer_href = div.find("a").attrs["href"] # 喜欢人数 like_num = div.find("div").text artistList.append([singer_name, singer_href, like_num]) # 输入爬取页数 def numpage(n,artistList,urls): # 随机生成index,爬取指定页数数据 for i in range(1,n+1): # 拼接url地址 url = "https://music.douban.com/artists/genre_page/8/"+str(i) # 获取源码 html = getHtml(url) # 数据添加=到数组中 beautifulSoup(html, artistList) # 保存数据 def saveexcel(artistList): save = pd.ExcelWriter("singerList.xlsx") #指定列名 column = ["singer_name", "singer_href", "like_num"] # 生成DataFrame格式数据 pf = pd.DataFrame(artistList,columns=column) # 使用pandas将DataFrame存入excel表格中 pf.to_excel(save) save.save() def readExcel(path): singerdetailslist = pd.read_excel(path) for i in singerdetailslist[‘singer_href‘]: try: text = getHtml(i) soup = BeautifulSoup(text, "html.parser") sp_logo = soup.select("div.sp-logo")[0].text.strip() try: # 获取所有专辑信息 albums = soup.select("div#album_box_415834")[0].text.strip() except: albums = "" bulletin_content = soup.select( "div#link-report415877")[0].text.strip() print(albums) except: bulletin_content = "" # 运行 def run(): artistList = [] urls = [] # 爬取5个页面的数据 numpage(5, artistList,urls) # 数据持久化 saveexcel(artistList) path = "singerList.xlsx" def run2(): readExcel("singerList.xlsx") run()



4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)

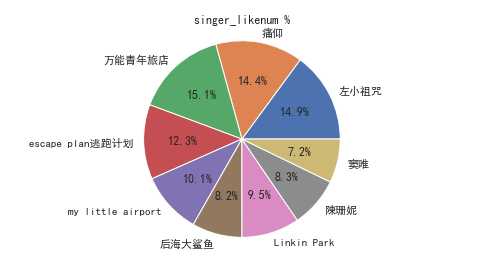
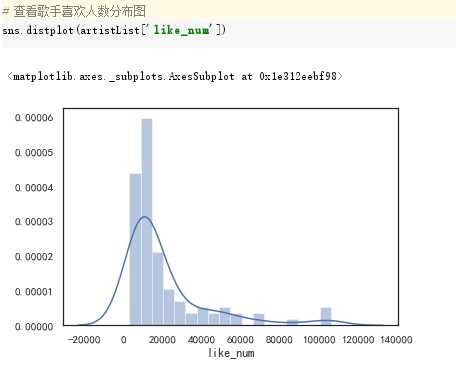

import requests from bs4 import BeautifulSoup import pandas as pd import matplotlib.pyplot as plt import re import seaborn as sns import numpy as np def getHtml(url): #获取网页数据 try: r = requests.get(url, headers={‘user-agent‘: ‘Mozilla/5.0‘}) r.raise_for_status() return r.text except: return "页面爬取错误" def beautifulSoup(html, artistList): List = [] #使用BeautifulSoup类解析html文本 soup = BeautifulSoup(html, "html.parser") clearfix = soup.find_all("div", "clearfix")[1] # 爬取列表标签 photoins = clearfix.find_all("div", "photoin") # 循环列表 for photoin in photoins: div = photoin.find("div", "ll") # 歌手 singer_name = div.find("a").text # 链接 singer_href = div.find("a").attrs["href"] # 喜欢人数 like_num = div.find("div").text artistList.append([singer_name, singer_href, like_num]) # 输入爬取页数 def numpage(n,artistList,urls): # 随机生成index,爬取指定页数数据 for i in range(1,n+1): # 拼接url地址 url = "https://music.douban.com/artists/genre_page/8/"+str(i) # 获取源码 html = getHtml(url) # 数据添加=到数组中 beautifulSoup(html, artistList) # 保存数据 def saveexcel(artistList): save = pd.ExcelWriter("singerList.xlsx") #指定列名 column = ["singer_name", "singer_href", "like_num"] # 生成DataFrame格式数据 pf = pd.DataFrame(artistList,columns=column) # 使用pandas将DataFrame存入excel表格中 pf.to_excel(save) save.save() def readExcel(path): singerdetailslist = pd.read_excel(path) for i in singerdetailslist[‘singer_href‘]: try: text = getHtml(i) soup = BeautifulSoup(text, "html.parser") sp_logo = soup.select("div.sp-logo")[0].text.strip() try: # 获取所有专辑信息 albums = soup.select("div#album_box_415834")[0].text.strip() except: albums = "" bulletin_content = soup.select( "div#link-report415877")[0].text.strip() print(albums) except: bulletin_content = "" # 运行 def run(): artistList = [] urls = [] # 爬取5个页面的数据 numpage(5, artistList,urls) # 数据持久化 saveexcel(artistList) path = "singerList.xlsx" def run2(): readExcel("singerList.xlsx") run()

标签:豆瓣 要求 coding end xls 表格 tis jieba分词 image
原文地址:https://www.cnblogs.com/caixiaoyu/p/12077792.html