标签:key stack reader 使用 extends 转化 off 数据 ATX
java.io.BufferedOutputStream extends OutputStream继承自父类的共性成员方法:
代码演示:
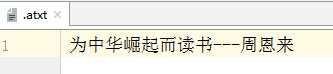
package demo01; import java.io.BufferedOutputStream; import java.io.FileOutputStream; import java.io.IOException; public class Demo01BufferedOutputStream { public static void main(String[] args) throws IOException { //创建FileOutputStream对象,指定要输出的目的地 FileOutputStream fos = new FileOutputStream("day21\\.atxt"); //2.创建BufferedOutputStream对象,构造方法中传递FileOutputStream对象对象,提高FileOutputStream对象效率 BufferedOutputStream bos = new BufferedOutputStream(fos); //把数据写入到内部缓冲区中 bos.write("为中华崛起而读书---周恩来".getBytes());//字符串转化为字节数组 /* 使用BufferedOutputStream对象中的方法flush,把内部缓冲区中的数据,刷新到文件中 bos.flush(); 5.释放资源(会先调用flush方法刷新数据,第4部可以省略) */ bos.close(); } }
代码执行后的结果
java.io.BufferedInputStream extends InputStream继承自父类的成员方法:
构造方法参数:
代码演示:
先准备好要读取的文件(字节文件一般使用字母演示,中文容易乱码)
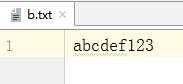
代码实现
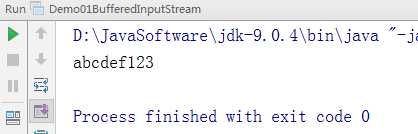
package demo01; import java.io.BufferedInputStream; import java.io.FileInputStream; import java.io.IOException; public class Demo01BufferedInputStream { public static void main(String[] args) throws IOException { //1.创建FileInputStream对象,构造方法中绑定要读取的数据源 FileInputStream fis = new FileInputStream("day21\\b.txt"); //2.创建BufferedInputStream对象,构造方法中传递FileInputStream对象,提高FileInputStream对象的读取效率 BufferedInputStream bis = new BufferedInputStream(fis); //3.使用BufferedInputStream对象中的方法read,读取文件 int len = 0;//记录每次读取的字节 //从输入流中读取一定数量的字节,并将其存储在缓冲区数组 b 中。 byte[] b = new byte[1024];//定义数组,存储每次读取的数据 //循环读取 while ((len = bis.read(b)) != -1) { //输出读取的数据,并且转化为字符串 System.out.println(new String(b, 0, len)); } //释放资源 bis.close(); } }
代码执行后的结果
代码演示
package demo01; import java.io.*; public class BufferedDemo { public static void main(String[] args) throws FileNotFoundException { // 记录开始时间 long start = System.currentTimeMillis(); // 创建流对象 try ( BufferedInputStream bis = new BufferedInputStream(new FileInputStream("C:\\1.txt")); BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("D\\copy.exe")); ) { // 读写数据 int len; byte[] bytes = new byte[8 * 1024]; while ((len = bis.read(bytes)) != -1) { bos.write(bytes, 0, len); } } catch (IOException e) { e.printStackTrace(); } // 记录结束时间 long end = System.currentTimeMillis(); System.out.println("缓冲流使用数组复制时间:" + (end - start) + " 毫秒"); } }
java.io.BufferedWriter extends Writer继承自父类的共性成员方法:
构造方法参数:
代码演示
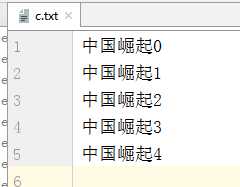
package demo01; import java.io.BufferedWriter; import java.io.FileWriter; import java.io.IOException; public class Demo01BufferedWriter { public static void main(String[] args) throws IOException { //1.创建字符缓冲输出流对象,构造方法中传递字符输出流 BufferedWriter bw = new BufferedWriter(new FileWriter("day21\\c.txt")); //2.调用字符缓冲输出流中的方法write,把数据写入到内存缓冲区中 for (int i = 0; i < 5; i++) { //利用for循环写5遍,中国崛起 bw.write("中国崛起" + i); //特意方法换行 bw.newLine(); } //释放资源 bw.close(); } }
代码执行后的结果
java.io.BufferedReader extends Reader继承自父类的共性成员方法:
参数:
String readLine() 读取一个文本行。读取一行数据行的终止符号。通过下列字符之一即可认为某行已终止:换行 (‘\n‘)、回车 (‘\r‘) 或回车后直接跟着换行(\r\n)。返回值:包含该行内容的字符串,不包含任何行终止符,如果已到达流末尾,则返回 null
代码演示
package demo01; import java.io.BufferedReader; import java.io.FileReader; import java.io.IOException; public class Demo01BufferedReader { public static void main(String[] args) throws IOException { //1.创建字符缓冲输入流对象,构造方法中传递字符输入流\ BufferedReader br = new BufferedReader(new FileReader("day21\\c.txt")); /* 发下以上读取是一个重复的过程,所以可以使用循环优化 不知道文件中有多少行数据,所以使用while循环 while的结束条件,读取到null结束 */ String s; //定义变量,记录每次读取的数据 while ((s = br.readLine()) != null) { System.out.println(s); } //释放资源 br.close(); } }
代码执行的结果

代码实现
package demo01; import java.io.*; import java.util.HashMap; /* 练习: 对文本的内容进行排序 按照(1,2,3....)顺序排序 分析: 1.创建一个HashMap集合对象,可以:存储每行文本的序号(1,2,3,..);value:存储每行的文本 2.创建字符缓冲输入流对象,构造方法中绑定字符输入流 3.创建字符缓冲输出流对象,构造方法中绑定字符输出流 4.使用字符缓冲输入流中的方法readline,逐行读取文本 5.对读取到的文本进行切割,获取行中的序号和文本内容 6.把切割好的序号和文本的内容存储到HashMap集合中(key序号是有序的,会自动排序1,2,3,4..) 7.遍历HashMap集合,获取每一个键值对 8.把每一个键值对,拼接为一个文本行 9.把拼接好的文本,使用字符缓冲输出流中的方法write,写入到文件中 10.释放资源 */ public class Test { public static void main(String[] args) throws IOException { //1.创建一个HashMap集合对象,可以:存储每行文本的序号(1,2,3,..);value:存储每行的文本 HashMap<String, String> map = new HashMap<>(); //2.创建字符缓冲输入流对象,构造方法中绑定字符输入流 BufferedReader br = new BufferedReader(new FileReader("day20\\a.txt")); //3.创建字符缓冲输出流对象,构造方法中绑定字符输出流 BufferedWriter bw = new BufferedWriter(new FileWriter("day20\\b.txt")); //4.使用字符缓冲输入流中的方法readline,逐行读取文本 String line; while ((line = br.readLine()) != null) { //5.对读取到的文本进行切割,获取行中的序号和文本内容 String[] arr = line.split("\\."); //6.把切割好的序号和文本的内容存储到HashMap集合中(key序号是有序的,会自动排序1,2,3,4..) map.put(arr[0], arr[1]); } //7.遍历HashMap集合,获取每一个键值对 for (String key : map.keySet()) { String value = map.get(key); //8.把每一个键值对,拼接为一个文本行 line = key + "." + value; //9.把拼接好的文本,使用字符缓冲输出流中的方法write,写入到文件中 bw.write(line); bw.newLine();//写换行 } //10.释放资源 bw.close(); br.close(); } }
标签:key stack reader 使用 extends 转化 off 数据 ATX
原文地址:https://www.cnblogs.com/wurengen/p/12079574.html