标签:无效 执行计划 backup tree 生效 提高 mysqldump 缓冲区 条件查询
为什么要有索引?
一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,在生产环境中,我们遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,因此对查询语句的优化显然是重中之重。说起加速查询,就不得不提到索引了。
什么是索引?
索引在MySQL中也叫是一种“键”,是存储引擎用于快速找到记录的一种数据结构。索引对于良好的性能非常关键,尤其是当表中的数据量越来越大时,索引对于性能的影响愈发重要。索引优化应该是对查询性能优化最有效的手段了。索引能够轻易将查询性能提高好几个数量级。索引相当于字典的音序表,如果要查某个字,如果不使用音序表,则需要从几百页中逐页去查。
有哪些索引?
索引种类 : memory(hash索引); (innodb/myisam)-b+tree(聚集索引 辅助索引)
mysql中有哪些索引?
primary key 主键索引\联合主键索引
unique key 唯一索引\联合唯一索引
index key 普通索引\联合索引
本质是: 通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。
当一次IO时,不光把当前磁盘地址的数据,而是把相邻的数据也都读取到内存缓冲区内,因为局部预读性原理告诉我们,当计算机访问一个地址的数据的时候,与其相邻的数据也会很快被访问到。
树
树状图是一种数据结构,它是由n(n>=1)个有限结点组成一个具有层次关系的集合。把它叫做“树”是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。
它具有以下的特点:每个结点有零个或多个子结点;没有父结点的结点称为根结点;每一个非根结点有且只有一个父结点;除了根结点外,每个子结点可以分为多个不相交的子树
[](
)
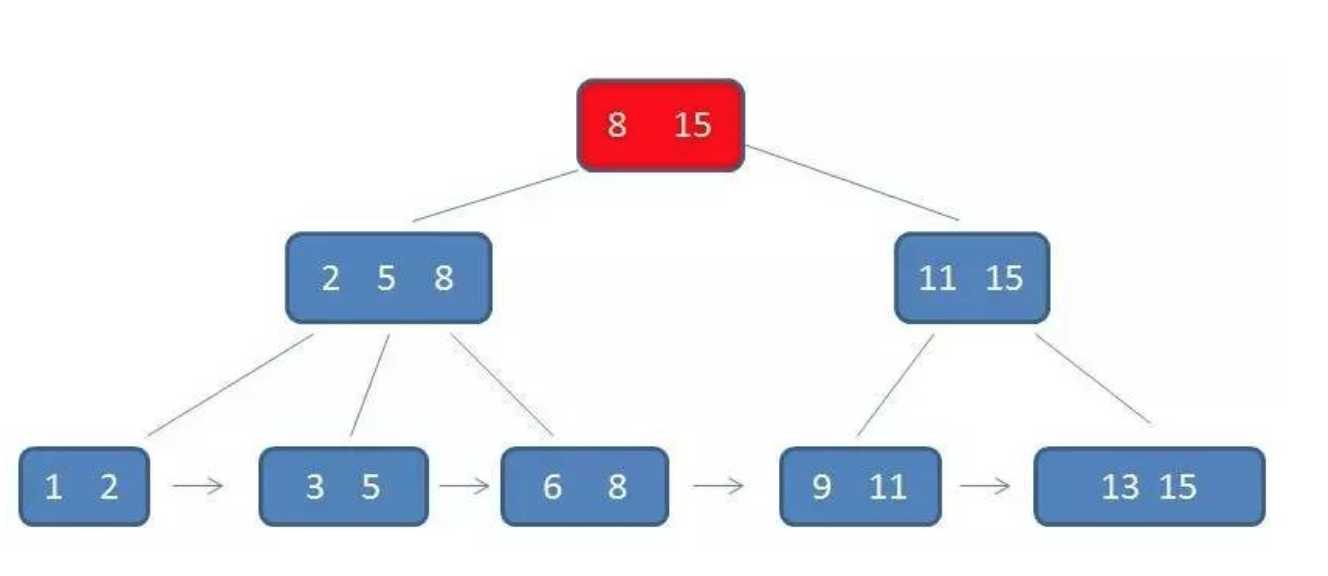
B+树
[](
)
聚集索引与辅助索引
在数据库中,B+树的高度一般都在2~4层,这也就是说查找某一个键值的行记录时最多只需要2到4次IO,这倒不错。因为当前一般的机械硬盘每秒至少可以做100次IO,2~4次的IO意味着查询时间只需要0.02~0.04秒.
数据库中的B+树索引可以分为聚集索引(clustered index)和辅助索引(secondary index),聚集索引与辅助索引相同的是:不管是聚集索引还是辅助索引,其内部都是B+树的形式,即高度是平衡的,叶子结点存放着所有的数据。聚集索引与辅助索引不同的是:叶子结点存放的是否是一整行的信息
聚集索引:(primary key 的创建自带索引效果 ) innodb
按照每张表的主键构造一棵B+树,同时叶子结点存放的即为整张表的行记录数据,也将聚集索引的叶子结点称为数据页。
聚集索引的好处之一:它对主键的排序查找和范围查找速度非常快,叶子节点的数据就是用户所要查询的数据。如用户需要查找一张表,查询最后的10位用户信息,由于B+树索引是双向链表,所以用户可以快速找到最后一个数据页,并取出10条记录
聚集索引的3想成为c询(range query),即如果要查找主键某一范围内的数据,通过叶子节点的上层中间节点就可以得到页的范围,之后直接读取数据页即可
辅助索引: innodb,myisam
表中除了聚集索引外其他索引都是辅助索引(Secondary Index,也称为非聚集索引),与聚集索引的区别是:辅助索引的叶子节点不包含行记录的全部数据。使用辅助索引查询其他的字段,需要在拿到索引字段后回到原表查询,称为回表
unique唯一约束的创建也自带索引效果,index普通的索引
聚集索引和非聚集索引的区别
聚集索引
1.纪录的索引顺序与无力顺序相同
因此更适合between and和order by操作
2.叶子结点直接对应数据
从中间级的索引页的索引行直接对应数据页
3.每张表只能创建一个聚集索引
非聚集索引
1.索引顺序和物理顺序无关
2.叶子结点不直接指向数据页
3.每张表可以有多个非聚集索引,需要更多磁盘和内容
多个索引会影响insert和update的速度功能
#1. 索引的功能就是加速查找
#2. mysql中的primary key,unique,联合唯一也都是索引,这些索引除了加速查找以外,还有约束的功能mysql常用的索引
普通索引INDEX:加速查找
唯一索引:
-主键索引PRIMARY KEY:加速查找+约束(不为空、不能重复)
-唯一索引UNIQUE:加速查找+约束(不能重复)
联合索引:
-PRIMARY KEY(id,name):联合主键索引
-UNIQUE(id,name):联合唯一索引
-INDEX(id,name):联合普通索引创建/删除索引的语法
#方法一:创建表时
CREATE TABLE 表名 (
字段名1 数据类型 [完整性约束条件…],
字段名2 数据类型 [完整性约束条件…],
[UNIQUE | FULLTEXT | SPATIAL ] INDEX | KEY
[索引名] (字段名[(长度)] [ASC |DESC])
);
#方法二:CREATE在已存在的表上创建索引
CREATE [UNIQUE | FULLTEXT | SPATIAL ] INDEX 索引名
ON 表名 (字段名[(长度)] [ASC |DESC]) ;
#方法三:ALTER TABLE在已存在的表上创建索引
ALTER TABLE 表名 ADD [UNIQUE | FULLTEXT | SPATIAL ] INDEX
索引名 (字段名[(长度)] [ASC |DESC]) ;
#删除索引:DROP INDEX 索引名 ON 表名字;索引的优缺点
优点: 查找速度快
缺点: 占用空间,拖慢写入的速度
所以不要创建无用的索引
并不是说创建了索引就一定会加快查询速度,若想利用索引达到预想的提高查询速度的效果,在添加索引时,必须遵循以下问题
所查询的列必须是创建了索引的列
在条件中不能带运算或者函数,必须是"字段 = 值"
数据对应的范围如果太大的话,或者说条件不明确,条件中出现这些符号或关键字:>、>=、<、<=、!= 、between...and...、not in
like如果把%放在最前面也不能命中索引
如果创建索引的列的内容重复率高也不能有效利用索引,重复率不超过10%的列比较适合做索引
多条件的情况
联合索引
其他情况
- 使用函数
select * from tb1 where reverse(email) = 'egon';
- 类型不一致
如果列是字符串类型,传入条件是必须用引号引起来,不然...
select * from tb1 where email = 999;
#排序条件为索引,则select字段必须也是索引字段,否则无法命中
- order by
select name from s1 order by email desc;
当根据索引排序时候,select查询的字段如果不是索引,则速度仍然很慢
select email from s1 order by email desc;
特别的:如果对主键排序,则还是速度很快:
select * from tb1 order by nid desc;
- 组合索引最左前缀
如果组合索引为:(name,email)
name and email -- 命中索引
name -- 命中索引
email -- 未命中索引
- count(1)或count(列)代替count(*)在mysql中没有差别了
- create index xxxx on tb(title(19)) #text类型,必须制定长度注意事项
- 避免使用select *
- 使用count(*)
- 创建表时尽量使用 char 代替 varchar
- 表的字段顺序固定长度的字段优先
- 组合索引代替多个单列索引(由于mysql中每次只能使用一个索引,所以经常使用多个条件查询时更适合使用组合索引)
- 尽量使用短索引
- 使用连接(JOIN)来代替子查询(Sub-Queries)
- 连表时注意条件类型需一致
- 索引散列值(重复少)不适合建索引,例:性别不适合联合索引是指对表上的多个列合起来做一个索引。联合索引的创建方法与单个索引的创建方法一样,不同之处仅在于有多个索引列,如下
mysql> create table t(
-> a int,
-> b int,
-> primary key(a),
-> key idx_a_b(a,b)
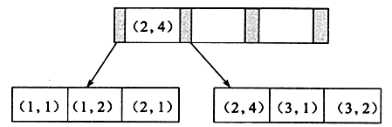
-> );那么何时需要使用联合索引呢?在讨论这个问题之前,先来看一下联合索引内部的结果。从本质上来说,联合索引就是一棵B+树,不同的是联合索引的键值得数量不是1,而是>=2。接着来讨论两个整型列组成的联合索引,假定两个键值得名称分别为a、b如图
[](
)
可以看到这与单个键的B+树并没有什么不同,键值都是排序的,通过叶子结点可以逻辑上顺序地读出所有数据,就上面的例子来说,即(1,1),(1,2),(2,1),(2,4),(3,1),(3,2),数据按(a,b)的顺序进行了存放。
因此,对于查询select * from table where a=xxx and b=xxx, 显然是可以使用(a,b) 这个联合索引的,对于单个列a的查询select * from table where a=xxx,也是可以使用(a,b)这个索引的。
但对于b列的查询select * from table where b=xxx,则不可以使用(a,b) 索引,其实不难发现原因,叶子节点上b的值为1、2、1、4、1、2显然不是排序的,因此对于b列的查询使用不到(a,b) 索引
联合索引的第二个好处是在第一个键相同的情况下,已经对第二个键进行了排序处理,例如在很多情况下应用程序都需要查询某个用户的购物情况,并按照时间进行排序,最后取出最近三次的购买记录,这时使用联合索引可以避免多一次的排序操作,因为索引本身在叶子节点已经排序了,如下
#对于联合索引(a,b),下述语句可以直接使用该索引,无需二次排序
select ... from table where a=xxx order by b;
#对于联合索引(a,b,c)来说,下列语句同样可以直接通过索引得到结果
select ... from table where a=xxx order by b;
select ... from table where a=xxx and b=xxx order by c;
#但是对于联合索引(a,b,c),下列语句不能通过索引直接得到结果,还需要自己执行一次filesort操作,因为索引(a,c)并未排序
select ... from table where a=xxx order by c;InnoDB存储引擎支持覆盖索引(covering index,或称索引覆盖),即从辅助索引中就可以得到查询记录,而不需要查询聚集索引中的记录。
使用覆盖索引的一个好处是:辅助索引不包含整行记录的所有信息,故其大小要远小于聚集索引,因此可以减少大量的IO操作
要查询的字段就是条件中的索引字段:
select id from tb where id=1000;对于(a,b)形式的联合索引,一般是不可以选择b中所谓的查询条件。但如果是统计操作,并且是覆盖索引,则优化器还是会选择使用该索引:
select count(*) from tb where b between 100 and 200;查看sql语句的执行计划
explain select * from s1 where id < 1000000;
是否命中了索引,命中的索引的类型
rows是核心指标,绝大部分rows小的语句执行一定很快。所以优化语句基本上都是在优化rows。
all < index < range < index_merge < ref_or_null < ref < eq_ref < system/const0.先运行看看是否真的很慢,注意设置SQL_NO_CACHE
1.where条件单表查,锁定最小返回记录表。这句话的意思是把查询语句的where都应用到表中返回的记录数最小的表开始查起,单表每个字段分别查询,看哪个字段的区分度最高
2.explain查看执行计划,是否与1预期一致(从锁定记录较少的表开始查询)
3.order by limit 形式的sql语句让排序的表优先查
4.了解业务方使用场景
5.加索引时参照建索引的几大原则
6.观察结果,不符合预期继续从0分析# 1.表结构
# 尽量用固定长度的数据类型代替可变长数据类型
# 把固定长度的字段放在前面
# 2.数据的角度上来说
# 如果表中的数据越多 查询效率越慢
# 列多 : 垂直分表
# 行多 : 水平分表
# 3.从sql的角度来说
# 1.尽量把条件写的细致点儿 where条件就多做筛选
# 2.多表尽量连表代替子查询
# 3.创建有效的索引,而规避无效的索引
# 4.配置角度上来说
# 开启慢日志查询 确认具体的有问题的sql
# 5.数据库
# 读写分离
# 解决数据库读的瓶颈慢日志
- 执行时间 > 10
- 未命中索引
- 日志文件路径
配置:
- 内存
show variables like '%query%';
show variables like '%queries%';
set global 变量名 = 值
- 配置文件
mysqld --defaults-file='E:\wupeiqi\mysql-5.7.16-winx64\mysql-5.7.16-winx64\my-default.ini'
my.conf内容:
slow_query_log = ON
slow_query_log_file = D:/....
注意:修改配置文件之后,需要重启服务begin; # 开启事务
select * from emp where id = 1 for update; # 查询id值,for update添加行锁;
update emp set salary=10000 where id = 1; # 完成更新
commit; # 提交事务数据库的逻辑备份:
#语法:
# mysqldump -h 服务器 -u用户名 -p密码 数据库名 > 备份文件.sql
#示例:
#单库备份
mysqldump -uroot -p123 db1 > db1.sql
mysqldump -uroot -p123 db1 table1 table2 > db1-table1-table2.sql
#多库备份
mysqldump -uroot -p123 --databases db1 db2 mysql db3 > db1_db2_mysql_db3.sql
#备份所有库
mysqldump -uroot -p123 --all-databases > all.sql 数据恢复:
#方法一:
[root@egon backup]# mysql -uroot -p123 < /backup/all.sql
#方法二:
mysql> use db1;
mysql> SET SQL_LOG_BIN=0; #关闭二进制日志,只对当前session生效
mysql> source /root/db1.sql标签:无效 执行计划 backup tree 生效 提高 mysqldump 缓冲区 条件查询
原文地址:https://www.cnblogs.com/douzi-m/p/12079870.html