标签:size blog 空间 sel 坐标系 class 群集 颜色 方法
时间过得很快,这篇文章已经是机器学习入门系列的最后一篇了。短短八周的时间里,虽然对机器学习并没有太多应用和熟悉的机会,但对于机器学习一些基本概念已经差不多有了一个提纲挈领的了解,如分类和回归,损失函数,以及一些简单的算法——kNN算法、决策树算法等。
那么,今天就用聚类和K-Means算法来结束我们这段机器学习之旅。
将物理或抽象对象的集合分成由类似的对象组成的多个类的过程被称为聚类。由聚类所生成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其他簇中的对象相异。“物以类聚,人以群分”,在自然科学和社会科学中,存在着大量的分类问题。聚类分析又称群分析,它是研究(样品或指标)分类问题的一种统计分析方法。聚类分析起源于分类学,但是聚类不等于分类。聚类与分类的不同在于,聚类所要求划分的类是未知的。聚类分析内容非常丰富,有系统聚类法、有序样品聚类法、动态聚类法、模糊聚类法、图论聚类法、聚类预报法等。
——摘自百度百科“聚类”词条
聚类分析(英语:Cluster analysis)亦称为群集分析,是对于统计数据分析的一门技术,在许多领域受到广泛应用,包括机器学习,数据挖掘,模式识别,图像分析以及生物信息。聚类是把相似的对象通过静态分类的方法分成不同的组别或者更多的子集(subset),这样让在同一个子集中的成员对象都有相似的一些属性,常见的包括在坐标系中更加短的空间距离等。一般把数据聚类归纳为一种非监督式学习。
——摘自Wikipedia“聚类分析”词条
翻译一下,聚类试图将数据集中的样本划分为若干个通常是不相交的子集,每个子集成为一个“簇”。
通过这样的划分,每个簇可能对应于一些潜在的概念(也就是类别),如“浅色瓜” “深色瓜”,“有籽瓜” “无籽瓜”,甚至“本地瓜” “外地瓜”等;需说明的是,这些概念对聚类算法而言事先是未知的,聚类过程仅能自动形成簇结构,簇对应的概念语义由使用者来把握和命名。(摘自 https://www.jianshu.com/p/caef1926adf7)
聚类是无监督的学习算法,分类是有监督的学习算法。所谓有监督就是有已知标签的训练集(也就是说提前知道训练集里的数据属于哪个类别),机器学习算法在训练集上学习到相应的参数,构建模型,然后应用到测试集上。而聚类算法是没有标签的,聚类的时候,我们并不关心某一类是什么,我们需要实现的目标只是把相似的东西聚到一起。
用小球来举例:
聚类划分得到的每一组对象称为一个对象簇。要想进行有意义的聚类分析,获得有用的对象簇是最为关键的一步。以下是几种常用的簇:
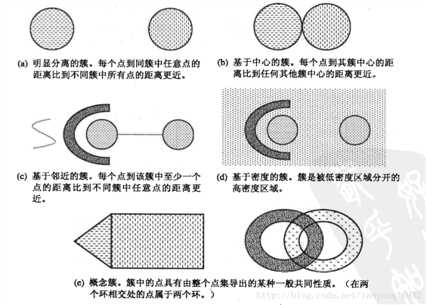
(摘自 https://blog.csdn.net/taoyanqi8932/article/details/53727841)
其中,基于中心的簇是我们接下来要研究的K-Means算法所要用到的簇类型。
提到距离,再重复一下之前的文章里提到过的各种距离类型。

我们最常用的,仍然是欧式距离(即差向量的2-范数)
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。每分配一个样本,聚类的聚类中心会根据聚类中现有的对象被重新计算。这个过程将不断重复直到满足某个终止条件。终止条件可以是没有(或最小数目)对象被重新分配给不同的聚类,没有(或最小数目)聚类中心再发生变化,误差平方和局部最小。
——摘自百度百科“K均值聚类算法”词条
K-平均算法(英文:k-means clustering)源于信号处理中的一种向量量化方法,现在则更多地作为一种聚类分析方法流行于数据挖掘领域。k-平均聚类的目的是:把n个点(可以是样本的一次观察或一个实例)划分到k个聚类中,使得每个点都属于离他最近的均值(此即聚类中心)对应的聚类,以之作为聚类的标准。这个问题将归结为一个把数据空间划分为Voronoi cells的问题。这个问题在计算上是NP困难的,不过存在高效的启发式算法。一般情况下,都使用效率比较高的启发式算法,它们能够快速收敛于一个局部最优解。这些算法通常类似于通过迭代优化方法处理高斯混合分布的最大期望算法(EM算法)。而且,它们都使用聚类中心来为数据建模;然而k-平均聚类倾向于在可比较的空间范围内寻找聚类,期望-最大化技术却允许聚类有不同的形状。k-平均聚类与k-近邻之间没有任何关系(后者是另一流行的机器学习技术)。
——摘自Wikipedia“K-Means算法”词条
简而言之,K-Means算法做的事情是:对于给定的样本集,按照样本之间的距离大小,将样本集划分为K个簇。让簇内的点尽量紧密的连在一起,而让簇间的距离尽量的大。
K-Means算法的流程描述如下:

给出一段参考的Python代码实现:
import numpy as np
import pandas as pd
import random
import sys
import time
class KMeansClusterer:
def __init__(self,ndarray,cluster_num):
self.ndarray = ndarray
self.cluster_num = cluster_num
self.points=self.__pick_start_point(ndarray,cluster_num)
def cluster(self):
result = []
for i in range(self.cluster_num):
result.append([])
for item in self.ndarray:
distance_min = sys.maxsize
index=-1
for i in range(len(self.points)):
distance = self.__distance(item,self.points[i])
if distance < distance_min:
distance_min = distance
index = i
result[index] = result[index] + [item.tolist()]
new_center=[]
for item in result:
new_center.append(self.__center(item).tolist())
# 中心点未改变,说明达到稳态,结束递归
if (self.points==new_center).all():
return result
self.points=np.array(new_center)
return self.cluster()
def __center(self,list):
'''计算一组坐标的中心点
'''
# 计算每一列的平均值
return np.array(list).mean(axis=0)
def __distance(self,p1,p2):
'''计算两点间距
'''
tmp=0
for i in range(len(p1)):
tmp += pow(p1[i]-p2[i],2)
return pow(tmp,0.5)
def __pick_start_point(self,ndarray,cluster_num):
if cluster_num <0 or cluster_num > ndarray.shape[0]:
raise Exception("簇数设置有误")
# 随机点的下标
indexes=random.sample(np.arange(0,ndarray.shape[0],step=1).tolist(),cluster_num)
points=[]
for index in indexes:
points.append(ndarray[index].tolist())
return np.array(points)好了,为期八周的机器学习入门到这里就结束了。希望这段学习经历能够或多或少能在将来起到一些作用。
那么,笔者也终于可以全心全意开始课程设计和期末复习啦。Bye~
https://www.jianshu.com/p/caef1926adf7
https://blog.csdn.net/taoyanqi8932/article/details/53727841
https://zh.wikipedia.org/wiki/%E8%81%9A%E7%B1%BB%E5%88%86%E6%9E%90
https://zh.wikipedia.org/wiki/K-%E5%B9%B3%E5%9D%87%E7%AE%97%E6%B3%95
https://baike.baidu.com/item/K%E5%9D%87%E5%80%BC%E8%81%9A%E7%B1%BB%E7%AE%97%E6%B3%95/15779627?fr=aladdin
https://baike.baidu.com/item/%E8%81%9A%E7%B1%BB/593695?fr=aladdin
【机器学习】机器学习入门08 - 聚类与聚类算法K-Means
标签:size blog 空间 sel 坐标系 class 群集 颜色 方法
原文地址:https://www.cnblogs.com/DrChuan/p/12082985.html