标签:可变 a+b 十六进制 for 技术 detail alt 混合 映射
python中有7种标准数据类型,分别是布尔型、数字型、字符串、元组、列表、字典和集合,根据数据的特点,可以划分为两大类:不可变数据类型、可变数据类型,见下图:
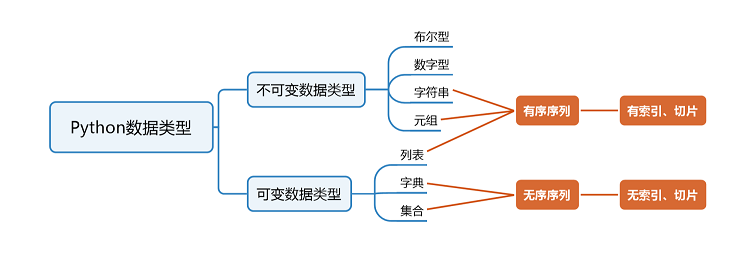
而不同数据类型,内部的组成元素,经常可以是其他的数据类型,即可以互相嵌套,见下图:
布尔型数据也叫布尔值,只有两种取值:True和False。布尔值有两种生成方式:
| 操作符 | 含义 |
|---|---|
| == | 等于 |
| != | 不等于 |
| < | 小于 |
| > | 大于 |
| <= | 小于等于 |
| >= | 大于等于 |
not 5
not 5 and 5 < 1 or 5 > 1
(not 5) and (5 < 1 or 5 > 1) # 加括号()可以控制运算先后次序数字型数据分为三类,其中int和float最常用:
三者存在拓展关系:整数 → 浮点数 → 复数,即「不同类型混合运算结果是最宽类型」。
数字型数据之间,可以通过运算操作符进行换算,常用运算符见下表:
| 运算操作符 | 含义 |
|---|---|
| x + y | x与y之和 |
| x - y | x与y之差 |
| x * y | x与y之积 |
| x / y | x与y之商 |
| x // y | x与y之整数商,即不大于x与y之商的最大整数 |
| x % y | x与y之商的余数,也叫模运算 |
| x ** y | x的y次幂,即x^y |
| - x | x的负值 |
| + x | x本身 |
# 整数商
9//4
# 模运算,可以把任意运算,映射到0-3之间
9 % 4
# x的y次幂,有两种表达方式
pow(2, 3)
2**3python中的内置函数底层由C语言编写,运行速度快,推荐优先使用
| 内置函数 | 含义 |
|---|---|
| abs(x) | x的绝对值 |
| divmod(x, y) | (x//y, x%y), 输出为二元组形式 |
| pow(x, y) | 与x**y相同 |
| round(x, [ndigits]) | 向整数位最靠近的偶数进行四舍五入,保留ndigits位小数 |
| max(x1, x2, ...) | 求最大值 |
| min(x1, x2, ...) | 求最小值 |
divmod(10, 3) # 输出为二元组形式
# 向最靠近的偶数进行四舍五入,目的是想要减少误差(银行家算法)
round(4.5)
round(5.5)
# 若对一堆数进行四舍五入,可以都加一个非常小的数,再用round()
round(4.500000000000001)字符串是用单引号‘ ‘、双引号" "、或多引号‘‘‘ ‘‘‘括起来的一个或多个字符串,
引号之间可以相互嵌套,用来表示复杂字符串。
转义字符\,表示转义,常用在一些字符或符号前面,共同组成新的含义,常用的有:
\:后接符号,表示原来是什么作用,转义之后还是什么作用,如"前面加 \就能打印出"\n:表示换行\t:表示Tab键拓展用法:在字符串的引号前加上r,就成为原始字符串,忽略所有转义字符
a = 'abc\ncde' # \n表示换行
print(a)
a = 'abc\tabc' # \t表示Tab键
print(a)
aa = 'Tom said, \'Let\'s go\'?' # 转义字符的运用
print(aa)
# 打印出转义字符
bb = '\\'
print(bb)
# 打印指定格式:三重引号
print('''Dear Tom,
I\'m happy to accept your letter. Now I\'ll tell you about my plan to my summer vacation.
......
Yours,
Xiao Qiang''')字符串中的编号叫做索引,访问对象是「单个元素值」;访问对象是「范围的数据」就是切片 ,用冒号:连接(开始、结束、步长),切片最少1个参数,最多3个参数。
特别注意,索引和切片都是「新生成」,原始数据不发生改变.
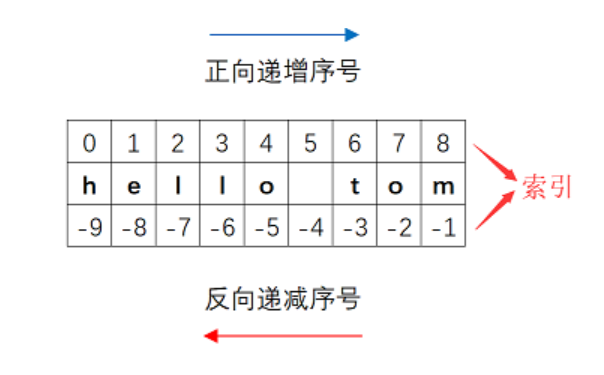
a = 'hello world'
a[-1] # 取最后一个
a[2:4] # 左闭右开
a[2:6:2] # 跳着取:从2到6,隔1个取一个
a[::-1] # 倒序
b = '123456789'
b[::2] # 取奇数
b[1::2] # 取偶数| 函数 | 含义 |
|---|---|
| len(x) | 返回字符串长度 |
| str(x) | 把任意类型x字符串化 |
| ord(x) | 返回单字符表示的unicode编码 |
| chr(x) | 返回unicode编码对应的单字符 |
| hex(x) | 返回整数x对应十六进制的小写形式字符串 |
| oct(x) | 返回整数x对应八进制的小写形式字符串 |
| eval(x) | 把任意字符串转化为表达式并求值 |
a = 'asgasdga sgasg' # 空格也算长度
len(a)
a = 'c'
ord(a) # 单字符对应的unicode编码
chr(99) # unicode编码对应的单字符
eval('4+5')查找
| 方法 | 含义 |
|---|---|
| find() | 查找字符串在另一字符串指定范围内首次出现位置,不存在返回-1 |
| rfind() | 最后一次出现位置,不存在返回-1 |
| index() | 查找字符串在另一字符串指定范围内首次出现位置,不存在抛出异常 |
| rindex() | 最后一次出现位置,不存在抛出异常 |
| count() | 返回一个字符串在另一个字符串中出现次数 |
s = 'ashuigasgi'
s.find('a')
s.rfind('8')
s.index('h')
s.find('9')
s.count('0')
分割与拼接
| 方法 | 含义 | 是否新生成 |
|---|---|---|
| split() | 指定字符为分隔符,从字符串左端开始分割成多个字符,返回列表 | 是 |
| rsplit() | 从右端开始分割 | 是 |
| partition() | 字符串分割成3部分:分割符前的字符串、分隔符字符串、分隔符后的字符串 | 是 |
| rpartition() | 从右端开始分割 | 是 |
| join() | 将字符串列表拼接成字符串,并在相邻字符串直接插入指定字符 | 是 |
| + | 拼接字符串 | 是 |
| * | 复制字符串 | 是 |
s = 'apple, peach, banana, peach, pear'
s.split(',') # 用什么分割
s.split(',', 2) # 分割几次
s.partition('peach')
x = ['apple', 'peach', 'banana', 'peach', 'pear']
'/'.join(x)
' '.join(x) # 用空格拼接
a = '123'
b = 'abc'
a+b
a*3
大小写
| 方法 | 含义 | 是否新生成 |
|---|---|---|
| lower() | 返回字符串的副本,全部字符串小写 | 是 |
| upper() | 返回字符串的大写副本 | 是 |
| capitalize() | 将字符串首字母大写 | 是 |
| title() | 将每个单词的首字母大写 | 是 |
| swapcase() | 大小写互换 | 是 |
s = 'Apple,Peach,Banana,Peach,Pear'
s.lower() # 全部小写
s.upper() # 全部大写
s = 'apple,peach,banana,peach,pear'
s.capitalize() # 字符串首字母大写
s.upper() # 每个单词首字母大写
s.swapcase() # 大小写互换
判断
| 方法 | 含义(判断字符串) |
|---|---|
| isdigit() | 是否只由数字组成 |
| isalpha() | 是否只由字母组成 |
| isalnum() | 是否只由数字或字母组成 |
| isupper() | 所有字母是否为大写 |
| islower() | 所有字母是否为小写 |
| isspace() | 是否只由空白字符组成 |
| istitle() | 是否单词首字母都是大写,且后面都是小写 |
| isdecimal() | 是否只包含十进制字符 |
| isnumeric() | 是否所有字符都是数字 |
| isprintable() | 是否所有字符都可以打印 |
| in | 在…内 |
| not in | 不在…内 |
判断的返回值都是True 或 False
a = 'hello world'
'hu' not in a
x = ' '
x.isspace()
s = 'Apple PeacH'
s.istitle()
移除空白字符串
| 方法 | 含义 | 是否新生成 |
|---|---|---|
| strip() | 移除左右两侧指定的字符,不指定默认移除空格 | 是 |
| lstrip() | 移除左侧指定的字符,不指定默认移除空格 | 是 |
| rstrip() | 移除右侧指定的字符,不指定默认移除空格 | 是 |
s = ' abcd '
s.strip() # 不指定,默认移除空格
s = '****abcd******'
s.strip('*') # 指定
s = ' abcd '
s.lstrip() # 移除左边
s.rstrip() # 移除右边
对齐文本
| 方法 | 含义 | 是否新生成 |
|---|---|---|
| ljust() | 返回左对齐的字符串,并使用指定长度的填充符号,不指定默认使用空格 | 是 |
| rjust() | 返回右对齐的字符串,并使用指定长度的填充符号,不指定默认使用空格 | 是 |
| center() | 返回居中对齐的字符串,并使用指定长度的填充符号,不指定默认使用空格 | 是 |
s = 'abjd'
s.ljust(10)
s.center(10, '*')
映射
| 方法 | 含义 |
|---|---|
| maketrans() | 生成字符串映射表 |
| translate() | 按映射表关系转换字符串 |
两者一般配对使用
s1 = 'abcde' # 原字符串中要替换的字符
num = '12345' # 相应的映射字符的字符串。
s2 = 'aaxxbbxxccxxddxxee' # 原字符串
hah = s1.maketrans(s1, num)
hah
s2.translate(hah)
其他方法
| 方法 | 含义(判断字符串) | 是否新生成 |
|---|---|---|
| replace() | 用指定字符串替代原字符串,并返回替换后的新字符串 | 是 |
| startswith() | 判断字符串:是否以指定字符串开头,并可以指定范围,返回布尔值 | / |
| endswith() | 判断字符串:是否以指定字符串结尾,并可以指定范围,返回布尔值 | / |
| zfill() | 在字符串左侧用0填充至指定长度,并返回补齐后的字符串 | 是 |
| encode() | 以指定编码格式对字符串进行编码,返回编码后的二进制 | / |
| decode() | 对编码后的字符串进行解码 | / |
s = 'aaxxbbxxccxxddxxee' # 原字符串
s.replace('xx', 'oo')
s.replace('ff', 'oo') # 如果不存在,返回原字符串
s = 'apple,peach,banana,peach,pear'
s.startswith('a') # 是不是以a开头
s.startswith('apple') # 是不是以apple开头
s.startswith('peach', 6) # 判断单词是不是从第i个开始
s = 'apple'
s.zfill(10)
s = '中国'
s1 = s.encode('utf-8') # utf8编码
s1
s1.decode() # 编码format格式化
为了将其他类型数据类型转换为字符串,需要进行格式化,通过format()方法实现,有三种常见形式:
| 格式化方法 | 语法形式 |
|---|---|
| 按从左到右传值 | "字符串 - {} -字符串- {}".format("内容1", "内容2") |
| 按指定位置传值 | "字符串 - {2} -字符串- {1}".format("内容1", "内容2") |
| 按设置参数传值 | "字符串 - {变量名1} -字符串- {变量名2}".format(变量名1="内容1", 变量名2="内容2") |
# 按默认顺序对字符串进行格式化
s = "I'm dark {}, I'm {} years old!"
s1 = s.format('knight', '28')
print(s1)
# 按位置对字符串进行格式化
s = "I'm dark {1}, I'm {0} years old!"
s1 = s.format('28', 'knight')
print(s1)
# 按参数设置对字符串进行格式化
s = "I'm dark {name}, I'm {age} years old!"
s1 = s.format(age='28', name='knight')
print(s1)
format格式控制
format除了可以进行字符串格式化以外,还可以对字符串进行「格式控制」,使得字符串呈现不同的表现形式,语法:{<参数序号>: <格式控制标记>}。
其中,<格式控制标记>用来控制参数显示的格式,包括:<填充><对齐><宽度>,<.精度><类型>6 个字段,这些字段都是可选的,能组合使用。
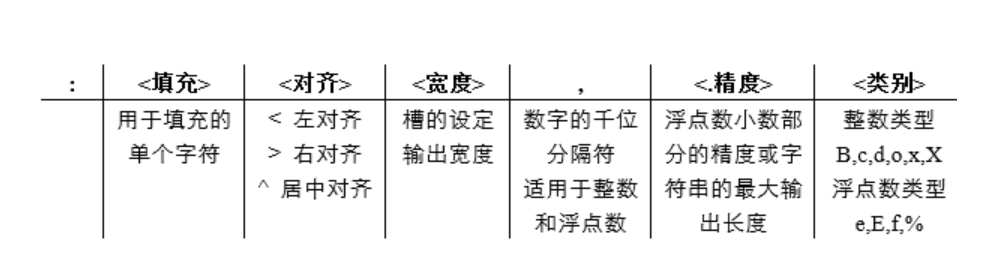
更多用法,可参见链接:https://blog.csdn.net/i_chaoren/article/details/77922939
s = 'dark knight'
'{0:20}'.format(s) # 默认左对齐
'{0:>30}'.format(s) # >表示右对齐
'{0:^30}'.format(s) # ^表示居中对齐
'{0:*^30}'.format(s) # 指定填充符号
'{0:*^30,}'.format(123456789) # 用逗号显示数字类型的千位分隔符
'{0:.2f}'.format(123.456789) # 指定浮点数精度
'{0:.2f}, {1:.4f}'.format(1/3, 5/7) # 不同位置取不同精度元组,外层用括号()包裹,里面元素用逗号分割的数据类型,如(1, 2),它是一种有序序列。
注意,元组外层的()也可以不写,如1, 2也是元组,等价于(1, 2)。
融化与冻结,实质就是元组和列表的相互转化
list()tuplea = (1, 2, 3, 4)
list(a) # 融化,元组变列表
b = [5, 6, 7, 8]
tuple(b) # 冻结,列表变元组同字符串、列表的索引切片,逻辑一样
t = (1, 'aa', {'abc': 123, 'cde': 789, 'efg': [11, 22, 33]})
t[2]['efg'][1]一次给多个变量赋值的方法叫序列解包,常用的序列解包方法有:
a, b = [1, 2] # 列表的序列解包
a
b
# a, b = 4, 5 # 这也是元组的序列解包
t1, t2 = (4, 5) # 元组的序列解包
t1
t2
c, d = 'sd' # 字符串的序列解包
c
d
e, f = range(2) # 内置对象的序列解包
e
f
x, y = map(str, range(2)) # 内置对象的序列解包
x
y和列表推导式类似,只是保存的是算法,且最外层用的是(),用法详见列表推导式
| 方法 | 含义 | 形式 |
|---|---|---|
| 列表推导式 | 保存元素,直接输出 | [ ] |
| 字典推导式 | 保存元素,直接输出 | { } |
| 生成器表达式 | 保存算法,元素用 .__next__() 或for循环访问 | ( ) |
[i for i in range(10) if i % 2 == 0] # 列表推导式——保存的是元素
(i for i in range(10) if i % 2 == 0) # 生成器表达式——保存的是算法
# 一般是逐个访问生成器表达式的元素,在计算的时候,用for循环逐个读出来
g = (i for i in range(10) if i % 2 == 0)
g.__next__()
g.__next__()
g.__next__()
# 用for循环逐个访问生成器表达式中的元素
g = (i for i in range(10) if i % 2 == 0)
for i in g:
print(i)
# 生成器表达式中的元素访问一次后就会失效,要想多次重复访问,就得重新生成生成器表达式
h = (i**2 for i in range(10))
4 in h # 第一次访问
4 in h # 第二次访问标签:可变 a+b 十六进制 for 技术 detail alt 混合 映射
原文地址:https://www.cnblogs.com/1k-yang/p/12082764.html