标签:普通话 file 脚本 tee 学习任务 重命名 code mamicode 文本
最近因学习任务,对语音识别需要了解,所以现在就把一些学习过程遇到的问题解决方法分享给大家。首先pyhon提供了许多语音识别库,大致包含:
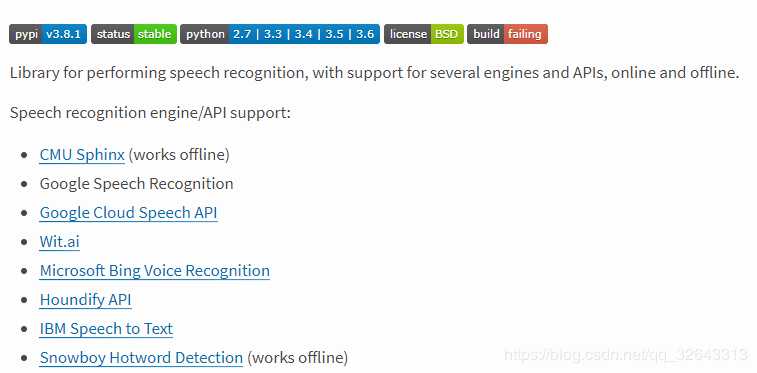
上述语音识别软件库各个之间的侧重点不同,如:谷歌云语音侧重语音向文本转换,又如wit与apiai还提供超出基本语音识别的内置功能(识别讲话者意图的自然语言处理功能)。由于我仅仅是做简单的中文语音识别,所以使用的是SpeechRcognition这个语音识别库。
下载地址:https://pypi.org/project/SpeechRecognition/
安装命令: pip install SpeechRcognition
不过仅仅安装这个是不够的,还需要安装对应需要的资源库,如下图:


Python开发案例
以上七个中只有 recognition_sphinx()可与CMU Sphinx 引擎脱机工作, 其他六个都需要连接互联网。另外,SpeechRecognition 附带 Google Web Speech API 的默认 API 密钥,可直接使用它。其他六个 API 都需要使用 API 密钥或用户名/密码组合进行身份验证。
我在这里使用的是recognize_sphinx()语音识别器,它可以脱机工作,但是必须安装pocketsphinx库(详细安装过程见https://blog.csdn.net/zouxy09/article/details/7942784),若要进行中文识别,还需要两样东西
WAV: 必须是 PCM/LPCM 格式
AIFF
AIFF-C
FLAC: 必须是初始 FLAC 格式;OGG-FLAC 格式不可用
pocketsphinx需要安装的中文语言、声学模型
下载地址:http://sourceforge.net/projects/cmusphinx/files/Acoustic%20and%20Language%20Models/
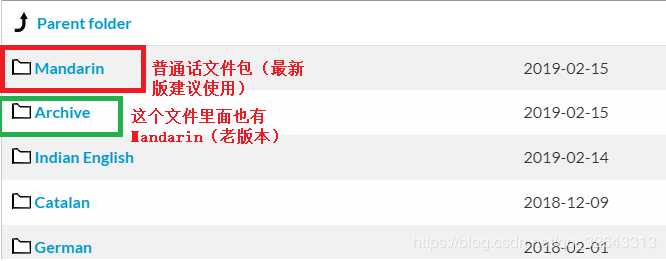
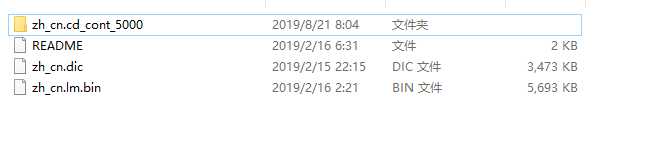
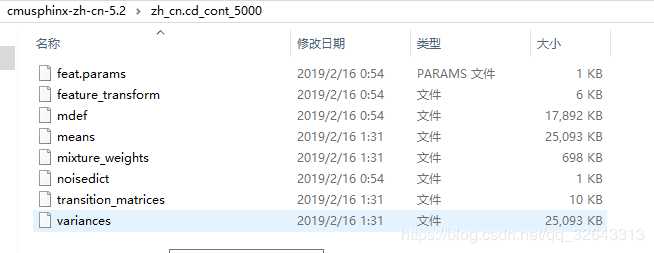
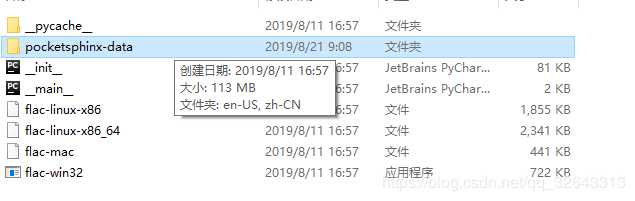
点击进入pocketsphinx-data文件夹,并新建文件夹zh-CN

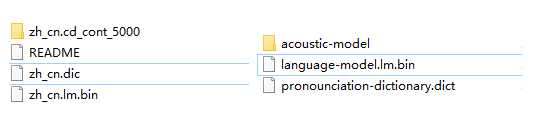
在这个文件夹中添加进入刚刚解压的文件,需要注意:把解压出来的zh_cn.cd_cont_5000文件夹重命名为acoustic-model、zh_cn.lm.bin命名为language-model.lm.bin、zh_cn.dic中dic改为dict格式
用声音控制Windows程序
开发案例
Python使用Speech_Recognition实现普通话识别
标签:普通话 file 脚本 tee 学习任务 重命名 code mamicode 文本
原文地址:https://www.cnblogs.com/lishangzhi/p/12089981.html