标签:命令 原因 res 最小值 找不到 不包含 视图 场景 关键字
1.查询全部列
SELECT *FROM 表名;
2.查询特定的列:
SELECT id, name FROM student;
3.起别名:
SELECT 列名1 AS "列1别名",列名2 AS "列2别名" FROM 表名;
或
SELECT 列名1 "列1别名",列名2 "列2别名" FROM 表名;
4.查询去重
select distinct 字段名 from 表名;
5.+号的作用
select 数值+数值;
6.concat函数(拼接字符,相当于java中的 "1"+"23"="123")
select concat(字符1,字符2,字符3,...);
7.ifnull函数
select ifnull(commission_pct,0) from employees;
8.isnull函数
功能:判断某字段或表达式是否为null,如果是,则返回1,否则返回0
select 查询列表 from 表名 where 筛选条件;
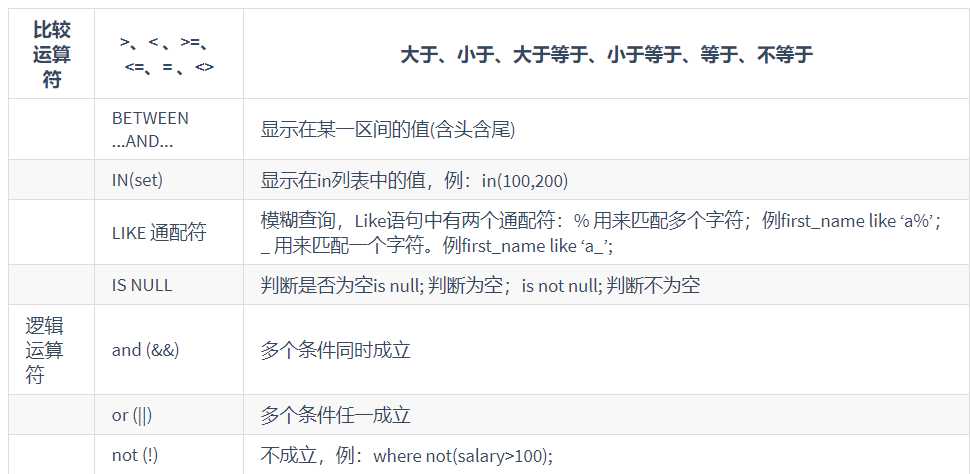
1.按条件表达式查询
SELECT * FROM employees WHERE salary>12000;
2.按逻辑表达式筛选
SELECT last_name, salary, commission_pct FROM employees WHERE salary>=10000 AND salary<=20000;
3.模糊查询
select last_name, salary FROM employees WHERE last_name LIKE ‘__e_a%‘;(查询员工名中第三个字符为e,第五个字符为a的员工名和工资)
4.IN查询
SELECT last_name, job_id FROM employees WHERE job_id IN( ‘IT_PROT‘ ,‘AD_VP‘,‘AD_PRES‘);
5.IS NULL语句
SELECT last_name, commission_pct FROM employees WHERE commission_pct IS NULL;
6.安全等于<=>
SELECT last_name, salary FROM employees WHERE salary <=> 12000;
ASC(ascend): 升序。DESC(descend): 降序
select 查询列表 from 表名 【where 筛选条件】 order by 排序的字段或表达式;
1.单个字段查询
SELECT * FROM employees WHERE department_id>=90 ORDER BY employee_id DESC;
2.按表达式排序
SELECT *,salary*12*(1+IFNULL(commission_pct,0)) FROM employees ORDER BY salary*12*(1+IFNULL(commission_pct,0)) DESC;
3.按函数排序
SELECT LENGTH(last_name),last_name FROM employees ORDER BY LENGTH(last_name) DESC;
4.多个字段排序
SELECT * FROM employees ORDER BY salary DESC,employee_id ASC;
字符函数:
1.length(s) 获取字符长度
SELECT LENGTH(‘john‘); SELECT LENGTH(‘张三丰hahaha‘);
2.concat(s1,s2...sn) 拼接字符串
SELECT CONCAT(last_name,‘_‘,first_name) 姓名 FROM employees;
3.upper(s) 将字符串转换为大写
SELECT UPPER(‘john‘);
4.lower(s) 将字符串转换为小写
SELECT LOWER(‘joHn‘);
5.substr(s,start,length)、substring() SUBSTR(s, start, length):从字符串 s 的 start 位置截取长度为 length 的子字符串
SELECT SUBSTR(‘李莫愁爱上了陆展元‘,1,3) out_put;
6.instr(s,s) 返回子串第一次出现的索引,如果找不到返回0
SELECT INSTR(‘杨不殷六侠悔爱上了殷六侠‘,‘殷八侠‘) AS out_put;
7.trim(s) 去掉字符串开始和结尾处的空格
SELECT LENGTH(TRIM(‘ 张翠山 ‘)) AS out_put;
8.lpad(s1,len,s2) 在字符串 s1 的开始处填充字符串 s2,使字符串长度达到 len
SELECT LPAD(‘殷素素‘,5,‘*‘) AS out_put; --> **殷素素
9.rpad(s1,len,s2) 在字符串 s1 的结尾处添加字符串 s2,使字符串的长度达到 len
SELECT RPAD(‘殷素素‘,5,‘*‘) AS out_put; --> 殷素素**
10.replace(s,s1,s2) 用字符串 s2 替代字符串 s 中的字符串 s1
SELECT REPLACE(‘张无忌爱上了周芷若‘,‘周芷若‘,‘赵敏‘) AS out_put; -->张无忌爱上了赵敏
1.round(x) ROUND(x,d):保留d位小数,四舍五入
SELECT ROUND(-1.55); --> -2
2.ceil(x) 向上取整
SELECT CEIL(-1.02); --> -1
3.floor(x) 向下取整
SELECT FLOOR(-1.58); --> -2
4.truncate(x,y) 返回数值 x 保留到小数点后 y 位的值(与 ROUND 最大的区别是不会进行四舍五入)
SELECT TRUNCATE(1.567,2); --> 1.56
5.mod(x,y) 返回 x 除以 y 以后的余数
SELECT MOD(10,-3); --> 1
1.now() 返回当前系统时间(注:日期+时间)
SELECT NOW(); --> 2019-10-05 09:56:57
2.curdate() 返回当前系统日期,不包含时间
ELECT CURDATE(); --> 2019-10-05
3.curtime() 返回当前系统日期,不包含日期
SELECT CURTIME(); -->09:56:57
4.year(d) 返回年份
SELECT YEAR(NOW()); -->2019
5.month(d) 返回日期d中的月份值,1 到 12
SELECT MONTH(NOW()); --> 10
6.monthname(d) 返回日期当中的月份名称,如 November
SELECT MONTHNAME(NOW()); --> October
7.str_to_date(s,f) 将字符通过指定的格式转换成日期
SELECT STR_TO_DATE(‘1998-3-2‘,‘%Y-%c-%d‘) AS out_put; --> 1998-03-02
8.date_format(d,f) 将日期通过指定的格式转换成字符
SELECT DATE_FORMAT(NOW(),‘%Y年%m月%d日‘) AS out_put; --> 2019年10月05日
1.version() 返回当前数据库名
2.user() 返回当前用户
SELECT USER();
1.if(expr,v1,v2) 如果表达式 expr 成立,返回结果 v1;否则,返回结果 v2。
SELECT IF(1 > 0,‘正确‘,‘错误‘); --> 正确
2.case CASE 表示函数开始,END 表示函数结束。如果 condition1 成立,则返回 result1, 如果 condition2 成立,则返回 result2,当全部不成立则返回 result,而当有一个成立之后,后面的就不执行了。
查询员工的工资,要求
SELECT salary 原始工资,department_id,
CASE department_id
WHEN 30 THEN salary*1.1
WHEN 40 THEN salary*1.2
WHEN 50 THEN salary*1.3
ELSE salary
END AS 新工资
FROM employees;
1.sum(expression) ? 求和
SELECT SUM(salary) FROM employees;
2.avg(expression) ? 平均值
SELECT AVG(salary) FROM employees;
3.max(expression) ? 最大值
SELECT MAX(salary) FROM employees;
4.min(expression) ? 最小值
SELECT MIN(salary) FROM employees;
5.count(expression) 计算个数
SELECT COUNT(salary) FROM employees;
分组函数支持哪些类型:
字符:先试图将字符转换成数值,如果转换成功,则继续运算;否则转换成0,再做运算
日期:SELECT SUM(hiredate) ,AVG(hiredate) FROM employees;
特点:
sum、avg一般用于处理数值型
max、min、count可以处理任何类型
以上分组函数都忽略null值
可以和distinct搭配实现去重的运算
一般使用count(*)用作统计行数
和分组函数一同查询的字段要求是group by后的字段
语法:select 分组函数,分组后的字段 from 表 【where 筛选条件】 group by 分组的字段 【having 分组后的筛选】 【order by 排序列表】
特点:
必须是group by后出现的字段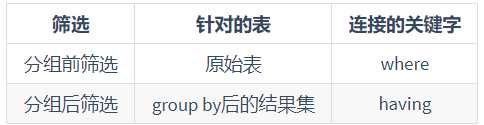
1.简单的分组
SELECT AVG(salary),job_id FROM employees GROUP BY job_id;
2.分组前筛选
例1:查询邮箱中包含a字符的 每个部门的最高工资
SELECT MAX(salary),department_id FROM employees WHERE email LIKE ‘%a%‘ GROUP BY department_id;
3.分组后筛选
例1:查询哪个部门的员工个数>5
SELECT COUNT(*),department_id FROM employees GROUP BY department_id HAVING COUNT(*)>5;
4.添加排序
例1:每个工种有奖金的员工的最高工资>6000的工种编号和最高工资,按最高工资升序
SELECT job_id 工种编号, MAX( salary ) 最高工资 FROM employees WHERE commission_pct IS NOT NULL GROUP BY job_id HAVING MAX( salary )> 6000 ORDER BY MAX( salary );
5.按多个字段分组
例1:查询每个工种每个部门的最低工资,并按最低工资降序
SELECT MIN( salary ) 最低工资, department_id 部门, job_id 工种 FROM employees GROUP BY department_id, job_id ORDER BY MIN( salary ) DESC;
select 字段1,字段2 from 表1,表2,...;
1.笛卡尔积现象
当查询多个表时,没有添加有效的连接条件,导致多个表所有行实现完全连接
表1 有m行,表2有n行,结果=m*n行
发生原因:没有有效的连接条件 如何避免:添加有效的连接条件
2.分类
按功能分类: 内连接: 等值连接 非等值连接 自连接 外连接: 左外连接 右外连接 全外连接(mysql不支持) 交叉连接
3.等值连接
多表等值连接的结果为多表的交集部分
n表连接,至少需要n-1个连接条件
表的顺序没有要求
一般需要为表起别名
可以搭配前面介绍的所有子句使用,比如排序、分组、筛选
例1:查询女神名和对应的男神名
SELECT NAME,boyName FROM boys, beauty WHERE beauty.boyfriend_id = boys.id;
4.为表起别名
SELECT e.last_name, e.job_id, j.job_title FROM employees e, jobs j WHERE e.`job_id` = j.`job_id`;
5.加筛选条件
SELECT last_name, department_name, commission_pct FROM employees e, departments d WHERE e.`department_id` = d.`department_id` AND e.`commission_pct` IS NOT NULL;
6.加分组
例1:查询每个城市的部门个数
SELECT COUNT(*) 个数, city FROM departments d, locations l WHERE d.`location_id` = l.`location_id` GROUP BY city;
7.非等值连接
语法:select 查询列表 from 表1 别名,表2 别名 where 非等值的连接条件 【and 筛选条件】 【group by 分组字段】 【having 分组后的筛选】 【order by 排序字段】
例1:SELECT e.salary 工资, j.grade_level 工资级别 FROM employees e, job_grades j WHERE e.salary BETWEEN j.lowest_sal AND j.highest_sal;
8.自连接
语法:select 查询列表 from 表 别名1,表 别名2 where 等值的连接条件 【and 筛选条件】 【group by 分组字段】 【having 分组后的筛选】 【order by 排序字段】
例1:查询员工名和上级的名称
SELECT e.last_name 员工名, m.last_name 上级名称 FROM employees e, employees m WHERE e.manager_id = m.employee_id;
语法:select 查询列表 from 表1 别名 【inner】 join 表2 别名 on 连接条件 where 筛选条件 group by 分组列表 having 分组后的筛选 order by 排序列表 limit 子句;
特点:
1.内连接-等值连接
例1:查询员工名、部门名
SELECT last_name, department_name FROM departments d INNER JOIN employees e ON e.`department_id` = d.`department_id`;
2.内连接-非等值连接
例1:查询员工的工资级别
SELECT e.last_name 员工名, e.salary 薪水, j.grade_level 工资级别 FROM employees e JOIN job_grades j ON e.salary BETWEEN j.lowest_sal AND j.highest_sal;
3.内连接-自连接
例1:查询员工的名字、上级的名字
SELECT e.last_name 员工名, m.last_name 上级名 FROM employees e JOIN employees m ON e.manager_id = m.employee_id;
语法:select 查询列表 from 表1 别名 left|right|full【outer】 join 表2 别名 on 连接条件 where 筛选条件 group by 分组列表 having 分组后的筛选 order by 排序列表 limit 子句;
应用场景:用于查询一个表中有,另一个表没有的记录
特点:
外连接的查询结果为主表中的所有记录
如果从表中有和它匹配的,则显示匹配的值
如果从表中没有和它匹配的,则显示null
外连接查询结果=内连接结果+主表中有而从表没有的记录
左外连接,left join 左边的是主表
右外连接,right join 右边的是主表
左外和右外交换两个表的顺序,可以实现同样的效果
全外连接=内连接的结果+表1中有但表2没有的+表2中有但表1没有的
1.左外连接
例1:查询哪个部门没有员工
SELECT d.* FROM departments d LEFT JOIN employees e ON d.department_id = e.department_id WHERE e.department_id IS NULL
2.右外连接
例1:查询哪个部门没有员工(调换位置使用RIGHT JOIN)
SELECT d.* FROM employees e RIGHT JOIN departments d ON d.department_id = e.department_id WHERE e.department_id IS NULL
3.全外连接(mysql不支持全外连接)
USE girls; SELECT b.*,bo.* FROM beauty b FULL OUTER JOIN boys bo ON b.`boyfriend_id` = bo.id;
4.交叉连接(交叉联接返回左表中的所有行,左表中的每一行与右表中的所有行组合。交叉联接也称作笛卡尔积。)
SELECT b.*,bo.* FROM beauty b CROSS JOIN boys bo;
1.标量子查询
例1:谁的工资比 Abel 高?
SELECT * FROM employees WHERE salary>( SELECT salary FROM employees WHERE last_name = ‘Abel‘ );
2.列子查询
| 操作符 | 含义 |
|---|---|
| IN/NOT IN | 等于列表中的任意一个 |
| ANY|SOME | 和子查询返回的某一个值比较 |
| ALL | 和子查询返回的所有值比较 |
例1:返回location_id是1400或1700的部门中的所有员工姓名
SELECT last_name FROM employees WHERE department_id IN( SELECT DISTINCT department_id FROM departments WHERE location_id IN(1400,1700) );
3.行子查询
例1:查询员工编号最小并且工资最高的员工信息
SELECT * FROM employees WHERE (employee_id,salary)=( SELECT MIN(employee_id),MAX(salary) FROM employees );
4.select后面
例1:查询每个部门的员工个数
SELECT d.*,( SELECT COUNT(*) FROM employees e WHERE e.department_id = d.`department_id` ) 个数 FROM departments d;
5.from后面
例1:查询每个部门的平均工资的工资等级
SELECT ag_dep.*,g.`grade_level` FROM ( SELECT AVG(salary) ag,department_id FROM employees GROUP BY department_id ) ag_dep INNER JOIN job_grades g ON ag_dep.ag BETWEEN lowest_sal AND highest_sal;
6.exists(相关子查询)
例1:查询有员工的部门名
SELECT department_name FROM departments d WHERE EXISTS( SELECT * FROM employees e WHERE d.`department_id`=e.`department_id` );
语法:select 查询列表 from 表 【join type】 join 表2 on 连接条件 where 筛选条件 group by 分组字段 having 分组后的筛选 order by 排序的字段】 limit 【offset,】size;
例1:查询前五条员工信息
SELECT * FROM employees LIMIT 0,5;
语法:查询语句1 union 【all】 查询语句2 union 【all】 ...
特点:
例1:查询部门编号>90或邮箱包含a的员工信息
SELECT * FROM employees WHERE email LIKE ‘%a%‘ UNION SELECT * FROM employees WHERE department_id>90;
1.INSERT
insert into 表名(字段名,...) values(值,...);
2.UPDATE
update 表名 set 字段=值,字段=值 【where 筛选条件】;
3.DELETE
delete from 表名 【where 筛选条件】【limit 条目数】
4.TRUNCATE(清空表)
truncate table 表名
1.MySQL数据类型
| 分类 | 类型名称 | 说明 |
|---|---|---|
| 整数类型 | tinyInt | 很小的整数 |
| smallint | 小的整数 | |
| mediumint | 中等大小的整数 | |
| int(integer) | 普通大小的整数 | |
| 小数类型 | float | 单精度浮点数 |
| double | 双精度浮点数 | |
| decimal(m,d) | 压缩严格的定点数 | |
| 日期类型 | year | YYYY 1901~2155 |
| time | HH : MM : SS -838:59 : 59~838 : 59 : 59 | |
| date | YYYY-MM-DD 1000-01-01~9999-12-3 | |
| datetime | YYYY-MM-DD HH : MM : SS 1000-01-01 00 : 00 : 00~ 9999-12-31 23 : 59 : 59 | |
| timestamp | YYYY-MM-DD HH : MM : SS 1970 |
|
| 文本、二进制类型 | CHAR(M) | M为0~255之间的整数 |
| VARCHAR(M) | M为0~65535之间的整数 | |
| TINYBLOB | 允许长度0~255字节 | |
| BLOB | 允许长度0~65535字节 | |
| MEDIUMBLOB | 允许长度0~167772150字节 | |
| LONGBLOB | 允许长度0~4294967295字节 | |
| TINYTEXT | 允许长度0~255字节 | |
| TEXT | 允许长度0~65535字节 | |
| MEDIUMTEXT | 允许长度0~167772150字节 | |
| LONGTEXT | 允许长度0~4294967295字节 | |
| VARBINARY(M) | 允许长度0~M个字节的变长字节字符串 | |
| BINARY(M) | 允许长度0~M个字节的定长字节字符串 |
事务由单独单元的一个或多个SQL语句组成,在这个单元中,每个MySQL语句是相互依赖的。而整个单独单元作为一个不可分割的整体,如果单元中某条SQL语句一旦执行失败或产生错误,整个单元将会回滚。所有受到影响的数据将返回到事物开始以前的状态;如果单元中的所有SQL语句均执行成功,则事物被顺利执行。
事务的特性(ACID):
原子性(Atomicity)
原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
一致性(Consistency)
事务必须使数据库从一个一致性状态变换到另外一个一致性状态。
隔离性(Isolation)
事务的隔离性是指一个事务的执行不能被其他事务干扰,即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
持久性(Durability)
持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来的其他操作和数据库故障不应该对其有任何影响
2.开启事务
# 关闭自动提交 set autocommit=0; #开启事物(可选) start transaction;
3.结束事务
commit;提交事务 # 或者 rollback;回滚事务 # 或者 rollback to 回滚点名;回滚到指定的地方
4.并发事务
事务的并发问题是如何发生的?
多个事务 同时 操作 同一个数据库的相同数据时
并发问题都有哪些?
脏读: 对于两个事务 T1, T2, T1 读取了已经被 T2 更新但还没有被提交的字段. 之后, 若 T2 回滚, T1读取的内容就是临时且无效的
不可重复读: 对于两个事务T1, T2, T1 读取了一个字段, 然后 T2 更新了该字段. 之后, T1再次读取同一个字段, 值就不同了(在一个事物中不管读多少次,读取的数据应该都一样)
幻读: 对于两个事务T1, T2, T1 从一个表中读取了一个字段, 然后 T2 在该表中插入了一些新的行. 之后, 如果 T1 再次读取同一个表, 就会多出几行
如何解决并发问题
通过设置隔离级别来解决并发问题
5.事务隔离级别
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| read uncommitted:读未提交 | × | × | × |
| read committed:读已提交 | √ | × | × |
| repeatable read:可重复读 | √ | √ | × |
| serializable:串行化 | √ | √ | √ |
6.查看隔离级别
select @@tx_isolation;
7.设置隔离级别
# 设置当前 mySQL 连接的隔离级别: set transaction isolation level read committed; # 设置数据库系统的全局的隔离级别: set global transaction isolation level read committed;
MySQL从5.0.1版本开始提供视图功能。一种虚拟存在的表,行和列的数据来自定义视图的查询中 使用的表,并且是在使用视图时动态生成的,只保存了sql逻辑,不保存查询结果
1.创建视图
create view 视图名 as 查询语句;
例1:创建视图emp_v2,要求查询部门的最高工资高于12000的部门信息
# 创建视图,查询每个部门的最高工资,筛选出高于12000的 DROP VIEW emp_v2; CREATE VIEW emp_v2 AS SELECT department_id, MAX( salary ) max_salary FROM employees GROUP BY department_id HAVING max_salary > 12000;
# 根据创建的视图连接departments表查询部门信息 SELECT d.*, ev2.max_salary FROM departments d JOIN emp_v2 ev2 ON d.department_id = ev2.department_id;
2.修改视图
create or replace view 视图名 as 查询语句;
3.删除视图
drop view 视图名,视图名,...
4.查看视图
DESC 视图名;
5.视图的更新
视图的可更新性和视图中查询的定义有关系,以下类型的视图是不能更新的。
什么是存储过程:事先经过编译并存储在数据库中的一段sql语句的集合。类似于java中的方法
1.创建语法
CREATE PROCEDURE 存储过程名(参数列表) BEGIN 存储过程体(一组合法的SQL语句) END
例1:插入到admin表中五条记录
USE girls; DELIMITER $ CREATE PROCEDURE myp1() BEGIN INSERT INTO admin(username,`password`) VALUES (‘john1‘,‘0000‘),(‘lily‘,‘0000‘),(‘rose‘,‘0000‘),(‘jack‘,‘0000‘),(‘tom‘,‘0000‘); END $
2.调用语法
CALL 存储过程名(实参列表);
3.创建带IN模式参数的存储过程
例1:创建存储过程实现 根据女神名,查询对应的男神信息
DELIMITER $ CREATE PROCEDURE myp2(IN beautyName VARCHAR(20)) BEGIN SELECT bo.* FROM boys bo RIGHT JOIN beauty b ON bo.id = b.boyfriend_id WHERE b.name=beautyName; END $
CALL myp2(‘赵敏‘);
4.创建out模式参数的存储过程
例1:根据输入的女神名,返回对应的男神名
DELIMITER $ CREATE PROCEDURE myp4(IN beautyName VARCHAR(20),OUT boyName VARCHAR(20)) BEGIN SELECT bo.boyname INTO boyname FROM boys bo RIGHT JOIN beauty b ON b.boyfriend_id = bo.id WHERE b.name=beautyName ; END $
# 调用 使用自定义变量接收 CALL myp4(‘赵敏‘,@name); SELECT @name;
5.创建带inout模式参数的存储过程
例1:传入a和b两个值,最终a和b都翻倍并返回
DROP PROCEDURE IF EXISTS myp5; DELIMITER $ CREATE PROCEDURE myp5(INOUT a INT,INOUT b INT) BEGIN SET a:=a*2; SET b:=b*2; END $
SET @m=10; SET @n=20; CALL myp5(@m,@n); SELECT @m,@n;
存储过程与存储函数的区别:存储过程:可以有0个返回,也可以有多个返回,适合做批量插入、批量更新,存储函数:有且仅有1 个返回,适合做处理数据后返回一个结果
1.创建语法
CREATE FUNCTION 函数名(参数列表) RETURNS 返回类型 BEGIN 函数体 END
2.调用语法
SELECT 函数名(参数列表);
3.无参数返回
例1:返回公司的员工个数
USE myemployees; DELIMITER // CREATE FUNCTION myf1() RETURNS INT BEGIN DECLARE c INT DEFAULT 0; #定义局部变量 SELECT COUNT(*) INTO c #赋值 FROM employees; RETURN c; END //
SELECT myf1();
4.有参数返回
例1:根据员工名,返回它的工资
DELIMITER // CREATE FUNCTION myf2(empName VARCHAR(20)) RETURNS DOUBLE BEGIN SET @sal=0; #定义用户变量 SELECT salary INTO @sal #赋值 FROM employees WHERE last_name = empName; RETURN @sal; END //
SELECT myf2(‘Kochhar‘); SELECT @sal;
5.查看函数
SHOW CREATE FUNCTION myf3;
6.删除函数
DROP FUNCTION myf3;
标签:命令 原因 res 最小值 找不到 不包含 视图 场景 关键字
原文地址:https://www.cnblogs.com/wuwuyong/p/12085431.html