标签:复杂 运行 选择排序 基础 运行时 strong 一般来说 空间换时间 其他
一、时间复杂度、空间复杂度
时间复杂度:用来评估算法运行效率的一个东西,用O()来表示
举例时间复杂度计算:
print(‘Hello World‘) O(1)
for i in range(n): #n次循环 print(‘Hello World‘) O(n)
for i in range(n): for j in range(n): #两个n嵌套循环 print(‘Hello World‘) O(n²)
以下这些代码时间复杂度呢?
print(‘Hello World‘) print(‘Hello Python‘) #看着是三个运行,但是也是O(1) print(‘Hello Algorithm’) O(1)
for i in range(n): print(‘Hello World’) for j in range(n): print(‘Hello World‘) O(n²)
下面这个代码的时间复杂度呢?
while n > 1: print(n) n = n // 2 2^6=64 log2^64=6 所以时间复杂度是:O(log2^n),也可以当做O(logn)
时间复杂度小结:
1.时间复杂度是用来估计算法运行时间的一个式子(单位)。
2.一般来说,时间复杂度高的算法比复杂度低的算法慢。
如何一眼判断时间复杂度?
1.循环减半的过程:O(logn)
2.几次循环就是n的几次方的复杂度
空间复杂度:用来评估算法内存占用大小的一个式子。
采用:空间换时间
二、列表排序
列表排序:将无序列表变为有序列表
输入:无序列表
输出:有序列表
几种常见的排序算法:冒泡排序,选择排序,插入排序,快速排序等
1.冒泡排序
思路:
1.有一个无序列表,比较列表两个相邻的数,如果前边的比后边的大,就交换它们两个
2.对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对,这样最后的元素就是值最大的。
3.重复上面的步骤,除了最后一个
所以我们要写两个for循环:
第一个for循环作用:控制排序的轮数
第二个for循环作用:控制每一轮里的每一个比较
冒泡排序代码如下:
li=[4,1,3,6,7,9,2,5,8] def Bubble_sort(li): for i in range(len(li)-1): for j in range(len(li)-1-i): if li[j] > li[j+1]: li[j], li[j+1] = li[j+1], li[j] print(li) Bubble_sort(li) #排序结果 [1, 2, 3, 4, 5, 6, 7, 8, 9]
冒泡排序的时间复杂度:O(n²),空间复杂度O(1)
冒泡排序优化:
如果冒泡排序中执行一趟而没有交换,则列表已经是有序状态,可以直接结束算法。

2.选择排序
思路:
1.一趟遍历记录最小的数,放到第一个位置。
2.再一趟遍历记录剩余列表中最小的数,继续放置
可以理解为:取列表索引为0的值,和后面位置的元素比较,索引为0的值大于其他位置的值就调换位置。索引0的值和所有元素比较完了,再索引1的值和后面元素依次比较,索引1的值大于其他位置的值就调换位置,以此类推,从小到大排序。
选择排序代码示例:
li=[4,3,6,1,7,9,2,5,8] def select_sort(li): for i in range(len(li)): minLoc = i ###i = 0 for j in range(i+1, len(li)): if li[j] < li[minLoc]: li[j], li[minLoc] = li[minLoc], li[j] print(li) select_sort(li) #结果[1, 2, 3, 4, 5, 6, 7, 8, 9]
选择排序的时间复杂度:O(n²),空间复杂度O(1)
3.插入排序
思路:类似于斗地主插牌
1.列表被分为有序区和无序区两个部分,最初有序区只有一个元素,假如抽取第一个元素
2.每次从无序区选择一个元素,插入到有序区的位置,和有序区的值一一比较,直到无序区变空
插入排序代码示例:
li=[4,3,6,1,7,9,2,5,8] def insert_sort(li): for i in range(1, len(li)): tmp = li[i] j = i - 1 while j >=0 and li[j] > tmp: li[j+1] = li[j] j = j - 1 li[j+1] = tmp print(li) insert_sort(li) #结果 [1, 2, 3, 4, 5, 6, 7, 8, 9]
插入排序时间复杂度:O(n²),空间复杂度O(1)
4.快速排序
好写的排序算法里最快的 ,快的排序算法里最好写的(写法比之前的几种复杂一点)
思路:
1.从数列中取出一个元素(一般取第一个元素),称为"基准"
2.写一个函数重新排序数列,所有元素比基准小的都放在基准左边,所有元素比基准大的都放在右边,相同的数到同一边。在这个分区退出之后,该基准就处于数列的中间位置。
3.再写一个函数,使用递归把小于基准值元素的子数列和大于基准值元素的子数列排序。递归的最底部情形,是数列的大小是零或一,也就是永远都已经被排序好了。虽然一直递归下去,但是这个算法总会退出,因为在每次的迭代中,它至少会把一个元素摆到它最后的位置去。
快速排序关键点:1.整理,2.递归
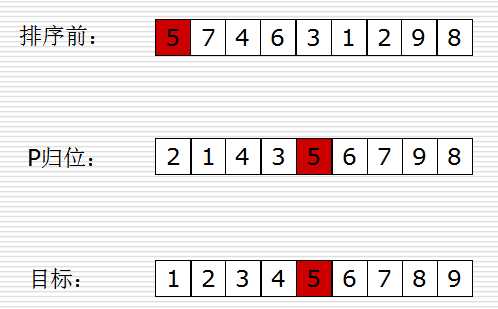
快速排序代码示例:
li=[4,3,6,1,7,9,2,5,8] #第一个函数,根据基准分区 def partition(li, left, right): tmp = li[left] while left < right: while left < right and li[right] >= tmp: right = right - 1 li[left] = li[right] while left < right and li[left] <= tmp: left = left + 1 li[right] = li[left] li[left] = tmp return left #第二个函数使用迭代 def quick_sort(li, left, right): if left < right: mid = partition(li, left, right) quick_sort(li, left, mid-1) quick_sort(li, mid+1, right) print(li) quick_sort(li, 0, len(li)-1) #结果:[1, 2, 3, 4, 5, 6, 7, 8, 9]
快速排序时间复杂度:O(nlogn),空间复杂度:O(logn)
未完。。。。
标签:复杂 运行 选择排序 基础 运行时 strong 一般来说 空间换时间 其他
原文地址:https://www.cnblogs.com/wangcuican/p/12094060.html