标签:balance 使用 tuple tor 统计 变更 提升性能 文章 前置
Vertica作为C-Store项目的商业化实现,所有前置论文C-Store要先看下
The Vertica Analytic Database (Vertica) is a distributed massively parallel RDBMS system that commercializes the ideas of the C-Store[21] project.
Vertica完成是为了AP设计的,
只能给出,TP和AP场景的不同,TP是高QPS,但是每个Transaction都只会操作少量的数据;AP是QPS较低,但是每条查询都会扫描大量的数据

核心设计
首先和C-Store一样,在物理上,Vertica也是以projections的形式存储的
这里有意思的是,Projections是一种受限形式的物化视图,这就部分解释了为何要用projections
因为在实际中,物化视图会包含聚合,join等,在实际系统中成本是无法接受的,至少现在没有那个开源数据库支持物化视图的
所以Vertica这里其实是用projections模拟轻量的物化视图

之前C-Store为了让projections之间可以join成行,增加join index,这个设计明显在实际应用中,成本很高
所以在Vertica中干脆放弃这个设计,直接默认增加super projection,包含所有column
数据库设计都是要normalized,但这样会导致join,所以理想情况是,逻辑上normalized,但在物理存储上denormalized,但是这很少用,因为这个很明显会降低loading的数据,得不偿失
可以看出,Vertica大部分的优化思路都是空间换时间,尽量避免join发生

基于列的encoding和压缩,是列存的关键,因为如果要用空间换时间,那空间的成本就需要控制在合理范围

这里描述两种数据划分,都是水平划分
一种是intra-node,节点内的,称为Partitioning,这样可以提升单节点的并发;并且带来的额外的好处,可以快速删除,比如按天,如果按天partition的话,可以优化查询,因为可以根据统计prune partitions
另一种是inter-node,节点间的,称为Segmentation,好处会把相同id的tuple都放到相同的node上,这样做聚合和join,会很方便;一个问题会造成热点,怎么解?



这里可以看一个segmentation的例子,
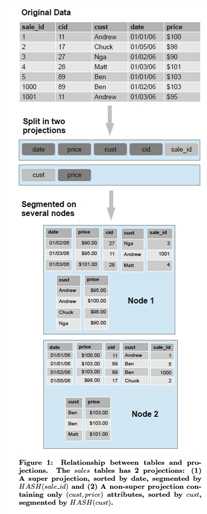
这里是列存的核心设计,
如果要支持实时写入,
就需要有一个WOS,并且用Tuple Mover,定时把数据move到ROS,大部分列存都是参考此种设计
Ros中,包含一些ROS containers,我个人理解,一个container包含一个projection排序后的数据,每个column会有一个独立的文件
除了数据问题,还有一个position index文件,放的是元数据和统计信息
Vertica并没有实现C-Store论文里面用的B-tree
虽然Vertica支持多个列存一个文件,column famliy的概念,这种称为Hybrid row-column的方式一般不会使用,因为影响压缩
WOS,完全在内存中,所以行存和列存,在性能上没有差异,都可以,也不用特意做encoding和compress,因为这些操作是用cpu换disk IO,在内存中没有必要
同样对于AP场景,一般不会做update,而且倾向于append,这个也是影响深远
append就需要解决,update和delete的问题,如果update变成delete和insert,所以只需要解决delete问题
这里给出的方法也是,经典方法,deleted vector,标记哪些行被删除
你可以认为deleted vector就是一种特殊列,所以在内存中,先DVWOS,在被move到磁盘中,DVROS

Mover是链接WOS和ROS之间的桥梁
主要做两件事情,Moveout,从WOS到ROS
Mergeout,把小的ROS合并成大的ROS,太多小的ROS会有很多问题,所以Mergeout对于这种架构是必须的功能,用于提升性能

Vertica有个特点,他也支持Transaction的能力
引入epoch概念,逻辑时间戳,每次commit或delete的时候,都会带上这个逻辑时间戳
因此,Vertica实现snapshot isolation,因为如果所有的节点都确定该epoch内的Transaction都已经完成提交,那么这个epoch就代表一个Globally Consistent Snapshot,有意思的想法!!!
那么Vertica默认就支持,Read Committed,因为你只要读epoch-1就好

那么如果每次只能读epoch-1,用户会觉得很奇怪,因为读不到最新的数据
那所有Vertica做的优化是,
当commit Transaction,如果包含DML或变更数据的DDL,就自动advances epoch;而不等leader定时触发advance;这样的代价,epoch会很多,而且epoch在advance的时候,是要保证epoch中所有Transaction都成功的,这样写入效率会降低
Vertica会记录两种Epoch,
LastGoodEpoch,记录哪个Epoch已经成功写入ROS中
Ancient History Mark,等同于low watermark,小于LWM的数据可以被过期掉

为了故障恢复,每个Projection,至少要有一个buddy projection包含相同的columns,然后segmentation保证存到不同的node上

Vertica是append模式,所有append模式都不需要另外记录WAL,因为append本身就是log
然后恢复过程分为,Historical Phase和Current Phase,分别对应于磁盘中数据和内存中数据
如果buddy projections的排序相同,那么可以直接copy ROS containers,如果不同排序,就需要从新排序,所以就是select insert过程
Vertica除了restore,还有refresh,rebalance和backup
backup过程,会先对meta catalog做snapshot,然后对数据文件做hard link,防止backup过程中文件被删除,copy数据,最后删除hardlink
backup不考虑WOS的?

总结,本篇文章就C-Store如何实现做了阐述,还是比较有借鉴意义的
The Vertica Analytic Database: CStore 7 Years Later
标签:balance 使用 tuple tor 统计 变更 提升性能 文章 前置
原文地址:https://www.cnblogs.com/fxjwind/p/12095868.html