标签:包含 mic aic 第四部分 amp app 箭头 sar 工作
在监督学习中,我们通常可以访问n个 观测值的p个 特征 集 ,并 在相同观测值上测得的 Y。
无监督学习是一组没有相关的变量 Y的方法。在这里,我们重点介绍两种技术…
通常,无监督学习比主观学习更具挑战性,因为它更具主观性。分析没有简单的目标,例如预测响应。无监督学习通常用作 探索性数据分析的一部分。此外,由于没有普遍接受的交叉验证或验证方法,因此很难评估获得的结果的准确性。简而言之 ,除了简单的直觉或手头上的过程的理论知识外,我们无法真正 在无人监督的情况下检查工作。但是,无监督方法有许多用途:
通过识别患者亚组来了解癌症行为。
网站(尤其是电子商务)通常会根据您之前的活动尝试向您推荐产品。
Netflix电影推荐。
当出现大量相关变量时,主要成分使我们能够将集合概括为较少数量的代表变量,这些变量 共同解释了原始集合中的大多数可变性。
主成分分析(PCA)是指计算主成分的过程,以及随后在理解数据中使用这些成分的过程。PCA还可以用作数据可视化的工具。
假设我们希望通过 对一组p个 特征的测量值来可视化 n个观测值,以 用于探索性数据分析的一部分。具体来说,我们希望找到一种数据的低维表示形式,该表示形式可以捕获尽可能多的信息。PCA提供了一种执行此操作的方法。PCA会寻求少量尽可能有趣的维度,其中有趣的概念 通过观察值在整个维度上的变化量来度量。
我们还可以通过利用主要组件来衡量丢失了多少信息。为此,我们可以计算 每个主成分解释的方差的 比例(PVE)。通常最好将其解释为累积图,以便我们可以可视化每个成分的PVE和所解释的总方差。一
总的来说,我们希望使用最少数量的主成分来充分理解数据。可以说,做到这一点的最好方法是在scree图中可视化数据 ,我们将在后面演示。它只是累积PVE的图。与我们选择其他学习技术的最佳调整参数的方式类似,查看百分比变化何时下降,这样,添加主要成分并不会真正增加大量的方差。我们可以结合一些对数据的理解来使用这种技术。
大多数统计方法都可以适应于使用主成分作为预测变量,这有时会导致噪声较小。
我们执行PCA 。
states <- rownames(USArrests)
states## [1] "Alabama" "Alaska" "Arizona" "Arkansas"
## [5] "California" "Colorado" "Connecticut" "Delaware"
## [9] "Florida" "Georgia" "Hawaii" "Idaho"
## [13] "Illinois" "Indiana" "Iowa" "Kansas"
## [17] "Kentucky" "Louisiana" "Maine" "Maryland"
## [21] "Massachusetts" "Michigan" "Minnesota" "Mississippi"
## [25] "Missouri" "Montana" "Nebraska" "Nevada"
## [29] "New Hampshire" "New Jersey" "New Mexico" "New York"
## [33] "North Carolina" "North Dakota" "Ohio" "Oklahoma"
## [37] "Oregon" "Pennsylvania" "Rhode Island" "South Carolina"
## [41] "South Dakota" "Tennessee" "Texas" "Utah"
## [45] "Vermont" "Virginia" "Washington" "West Virginia"
## [49] "Wisconsin" "Wyoming"数据集的列包含四个变量。
names(USArrests)## [1] "Murder" "Assault" "UrbanPop" "Rape"让我们来探讨一下数据。
kable(summary(USArrests))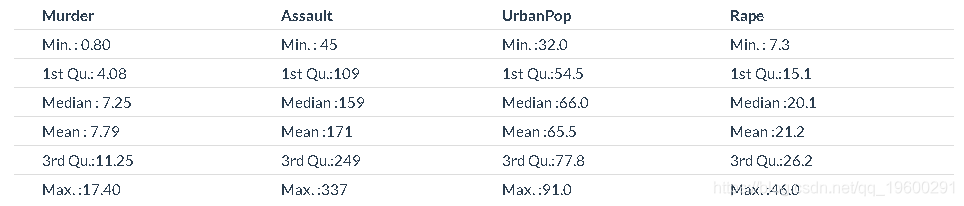
![]() ?
?
我们可以看到数据具有不同的均值和方差。此外,这些变量是在完全不同的尺度上测量的。例如 UrbanPop ,以百分比为单位,每10万个人测量次数。如果我们不对数据进行标准化,那就麻烦了。
执行PCA 提供主成分载荷。

![]() ?
?
我们已经可以确定每个主成分所代表的内容。例如,第一个部分似乎解释了与犯罪有关的信息与城市人口之间的差异。这也是第一个组成部分,从直观上来说,这是最大的差异。第二部分肯定解释了城市环境的影响,第三和第四部分显示了其他犯罪的区别。
我们可以绘制第一个主成分的图。
Biplot
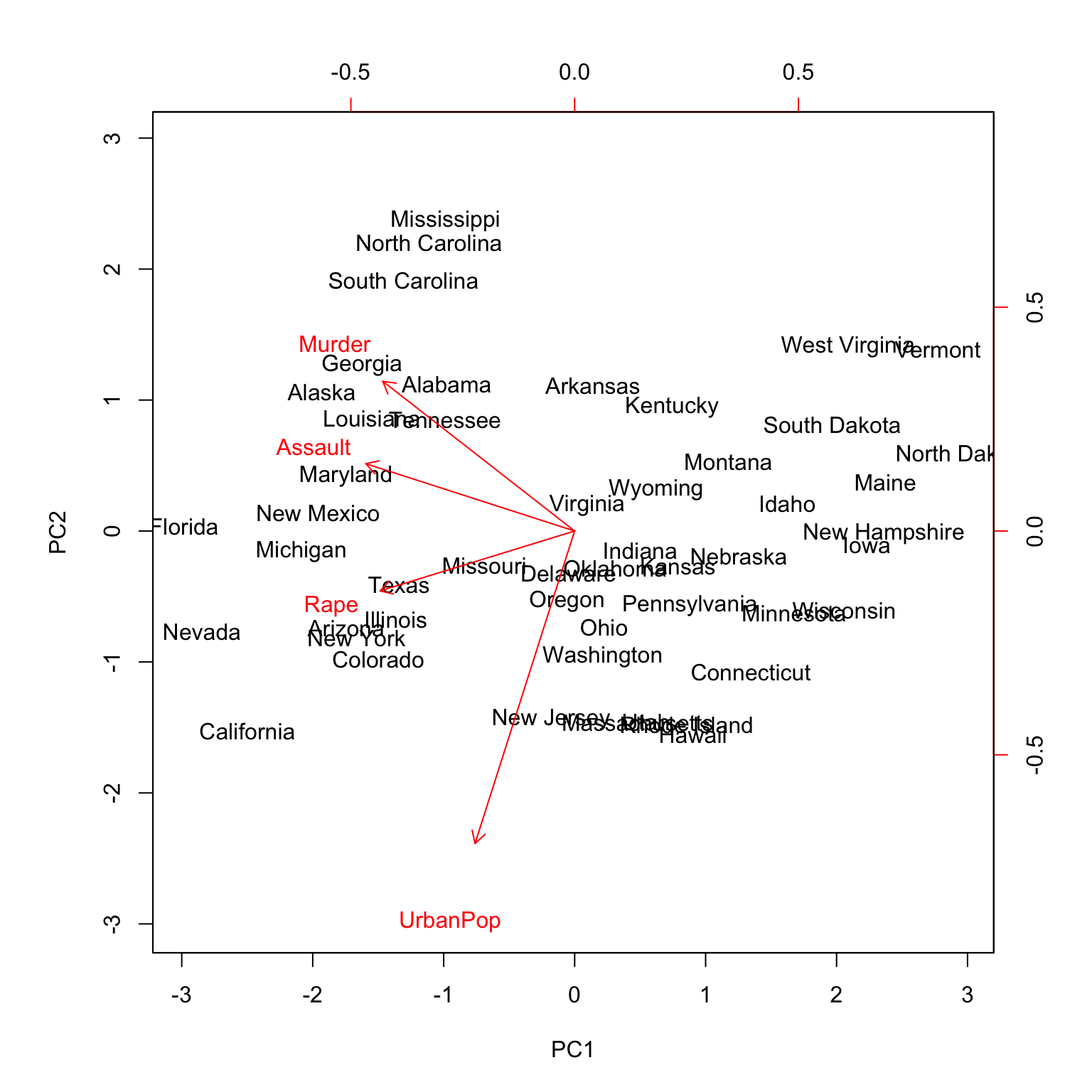
![]() ?
?
在这里我们可以看到很多信息。首先查看轴,轴上的PC1 x 和轴上的 PC2 y。箭头显示了它们如何在两个维度上移动。黑色状态显示每个状态在PC方向上如何变化。例如,加利福尼亚州既有高犯罪率,又是城市人口最多的国家之一。
该 $sdev 属性输出每个组件的标准偏差。每个分量解释的方差可以通过对这些平方进行平方来计算:
## [1] 2.4802 0.9898 0.3566 0.1734然后,为了计算每个主成分解释的方差比例,我们先将其除以总方差。
## [1] 0.62006 0.24744 0.08914 0.04336在这里,我们看到第一PC解释了大约62%的数据,第二PC解释了大约24%的数据。我们还可以绘制此信息。
碎石图
par(mfrow=c(1,2))
plot(pve, xlab=‘Principal Component‘,
ylab=‘Proportion of Variance Explained‘,
ylim=c(0,1),
type=‘b‘)
plot(cumsum(pve), xlab=‘Principal Component‘,
ylab=‘Cumuative Proportion of Variance Explained‘,
ylim=c(0,1),
type=‘b‘)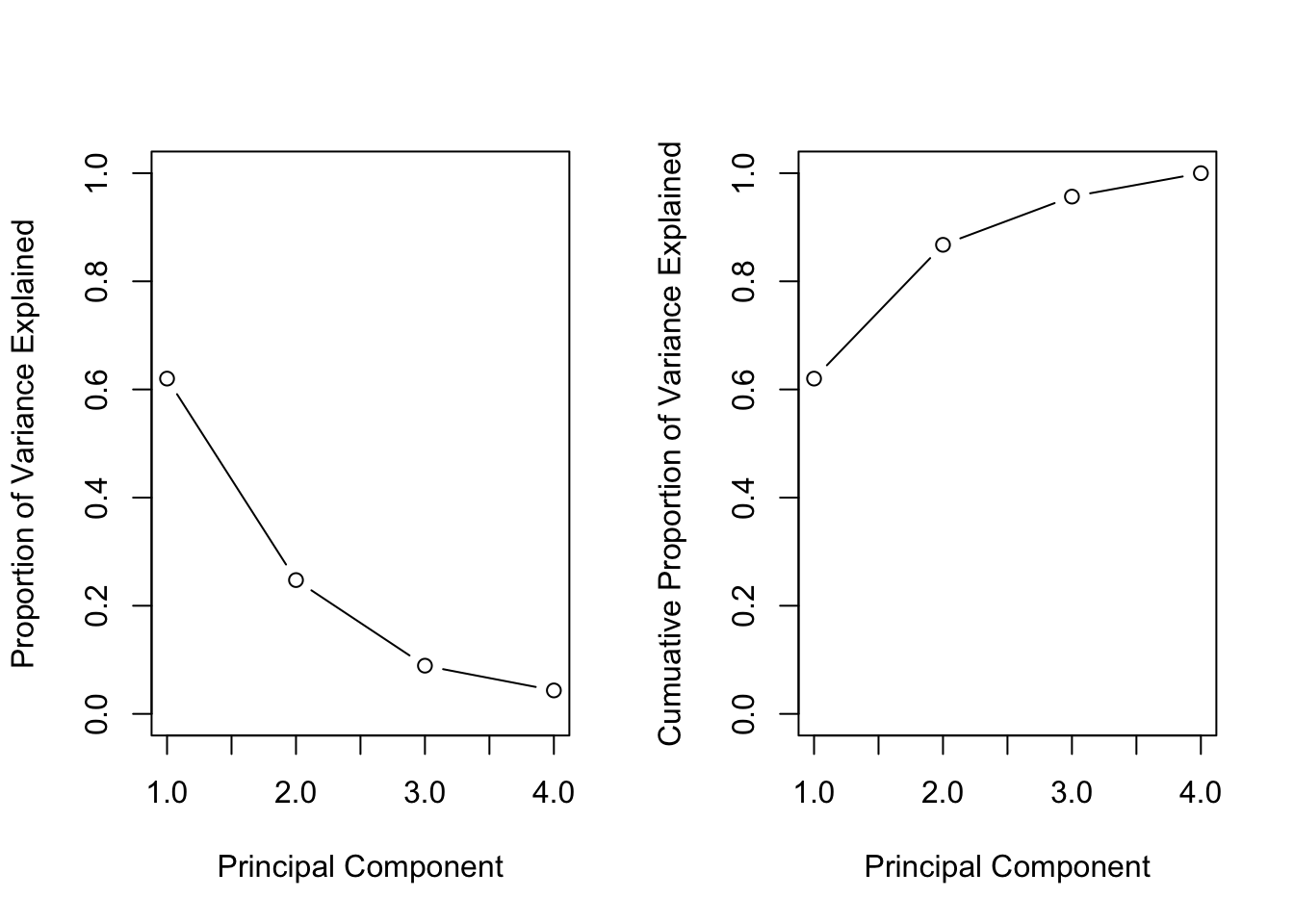
![]() ?
?
![]()
大数据部落 -中国专业的第三方数据服务提供商,提供定制化的一站式数据挖掘和统计分析咨询服务
统计分析和数据挖掘咨询服务:y0.cn/teradat(咨询服务请联系官网客服)
![]() ?
?QQ:3025393450
![]() ?QQ交流群:186388004
?QQ交流群:186388004 
【服务场景】
科研项目; 公司项目外包;线上线下一对一培训;数据爬虫采集;学术研究;报告撰写;市场调查。
【大数据部落】提供定制化的一站式数据挖掘和统计分析咨询



欢迎选修我们的R语言数据分析挖掘必知必会课程!

标签:包含 mic aic 第四部分 amp app 箭头 sar 工作
原文地址:https://www.cnblogs.com/tecdat/p/12099458.html