标签:docke 比较 人生苦短 基础入门 selenium cookies text nts meteor

人生苦短,我用 Python
前文传送门:
小白学 Python 爬虫(2):前置准备(一)基本类库的安装
小白学 Python 爬虫(3):前置准备(二)Linux基础入门
小白学 Python 爬虫(4):前置准备(三)Docker基础入门
小白学 Python 爬虫(6):前置准备(五)爬虫框架的安装
小白学 Python 爬虫(10):Session 和 Cookies
小白学 Python 爬虫(11):urllib 基础使用(一)
小白学 Python 爬虫(12):urllib 基础使用(二)
小白学 Python 爬虫(13):urllib 基础使用(三)
小白学 Python 爬虫(14):urllib 基础使用(四)
小白学 Python 爬虫(15):urllib 基础使用(五)
小白学 Python 爬虫(16):urllib 实战之爬取妹子图
小白学 Python 爬虫(17):Requests 基础使用
小白学 Python 爬虫(18):Requests 进阶操作
小白学 Python 爬虫(21):解析库 Beautiful Soup(上)
小白学 Python 爬虫(22):解析库 Beautiful Soup(下)
小白学 Python 爬虫(23):解析库 pyquery 入门
小白学 Python 爬虫(26):为啥买不起上海二手房你都买不起

前面连续几篇爬虫实战不知道各位同学玩的怎么样,小编是要继续更新了,本篇我们来介绍一个前面已将安装过的工具: Selenium ,如果说是叫爬虫工具其实并不合适,在业界很多时候是拿来做自动化测试的,所以本篇的标题也就叫成了自动化测试框架。
至于为什么叫这个名字我们就不去深究了,老外起名字的想象力还是相当可以的。
它可以通过驱动程序驱动浏览器执行特定的动作,这个特性对我们爬取由 JavaScript 动态渲染的页面是非常友好的。
因为由 JavaScript 动态渲染的页面,这种页面上的 JavaScript 通常经过了编译打包,看到的都是简码,非常难以阅读。
其实他们编译打包的目的就是不想让别人看,但是由于浏览器的特性由所有人都看得到,这个就比较尴尬了。。。
比较常见的打包方式有 webpack 打包等等。
有感兴趣的同学可以在留言区留言,人多的话小编后续可以分享一些前端的内容。

在开始之前,如果还没安装过环境的同学建议还是翻一翻前面你的文章,先把环境搞定。
请确认自己已经安装了 Chrome 浏览器并且也已经正确的配置了 ChromeDriver ,然后还需要正常的安装了 Selenium 库。
首先,还是官方网址敬上:
官方文档:https://selenium.dev/selenium/docs/api/py/api.html
有任何问题找官方,看不懂可以使用翻译软件。
以上前置准备都 ok 了以后,我们开始了解一下 Selenium 的一些基础操作把。先写一点简单的小功能演示一下:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
input = browser.find_element_by_id('kw')
input.send_keys('极客挖掘机')
input.send_keys(Keys.ENTER)
print(browser.current_url)
print(browser.get_cookies())
print(browser.page_source)运行以上代码,可以看到自动弹出来一个 Chrome 浏览器,并且上面标示了: Chrome 正受到自动软件的控制 。然后打开了百度,在输入框中输入了 “极客挖掘机” 进行搜索。
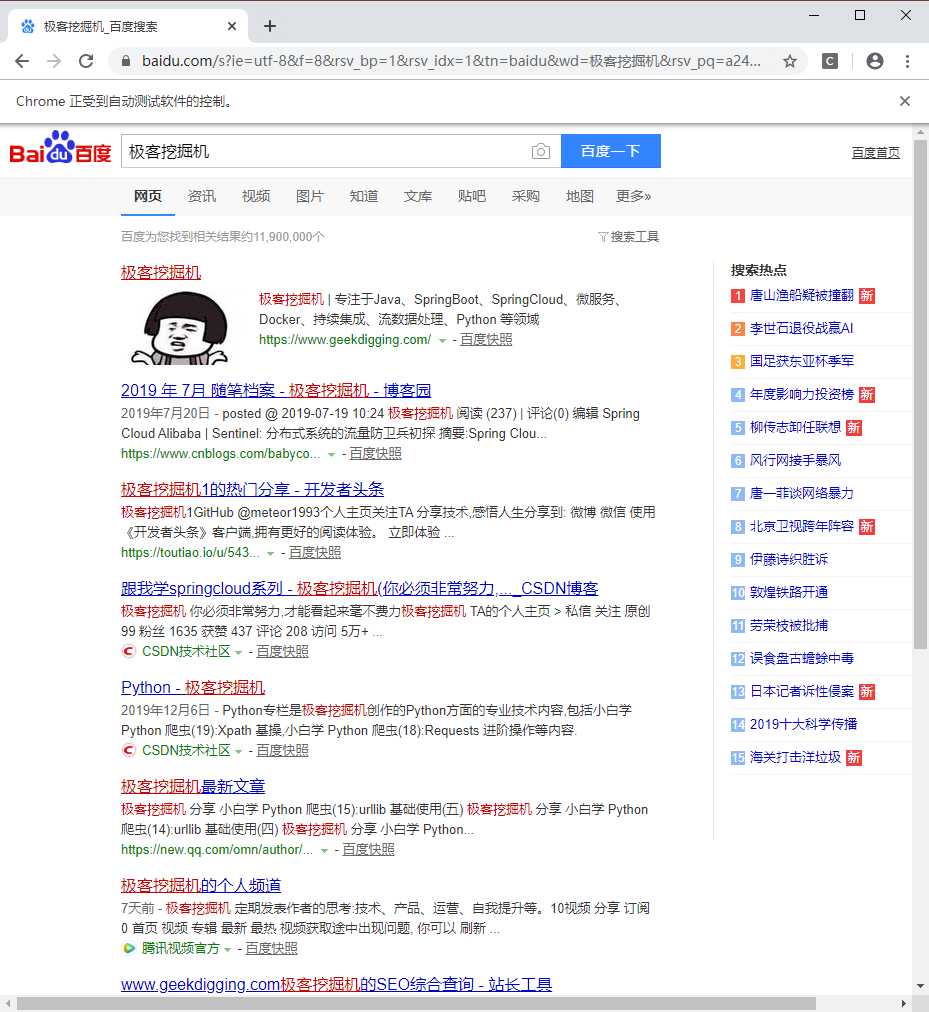
再搜索结果出来后控制台打印了当前的 URL 、 cookies 和网页的源代码。

控制台的运行结果就截个图吧,内容太长就不贴了。
可以看到, Selenium 拿到的内容,都是真实展示在浏览器中的内容。由 JavaScript 动态加载的页面生成的 DOM 节点在 Selenium 下也无所遁形。
这个很好解释,因为 Selenium 是直接拿到的浏览器展示的内容。
Selenium 支持非常多的浏览器,如:
from selenium import webdriver
# 声明浏览器对象,需对应的驱动程序方可使用
browser = webdriver.android()
browser = webdriver.blackberry()
browser = webdriver.chrome()
browser = webdriver.edge()
browser = webdriver.firefox()
browser = webdriver.ie()
browser = webdriver.opera()
browser = webdriver.phantomjs()
browser = webdriver.safari()可以看到有我熟悉的 IE 浏览器、 Edge 浏览器、 FireFox 浏览器、 Opera 浏览器等等。
访问网页可以使用 get() 方法,参数传入我们想要访问的网站即可:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.jd.com/')
print(browser.page_source)通过上面两行代码,我们可以看到自动打开了浏览器并访问的京东,在控制台打印了京东的源代码。
当然,如果想要程序自动关闭浏览器的话可以使用:
browser.close()这句话加在上面可以看到浏览器打开后访问京东一闪而过就关掉了。
我们获取到网页后,第一步肯定是要先查找到 DOM 节点啊,然后可以直接从 DOM 节点中获取数据。
不过有了 Selenium 以后,我们不仅可以查找到节点获取数据,还可以模拟用户操作,比如在搜索框输入某些内容,点击按钮等等操作,不过还是先看看怎么查找节点:
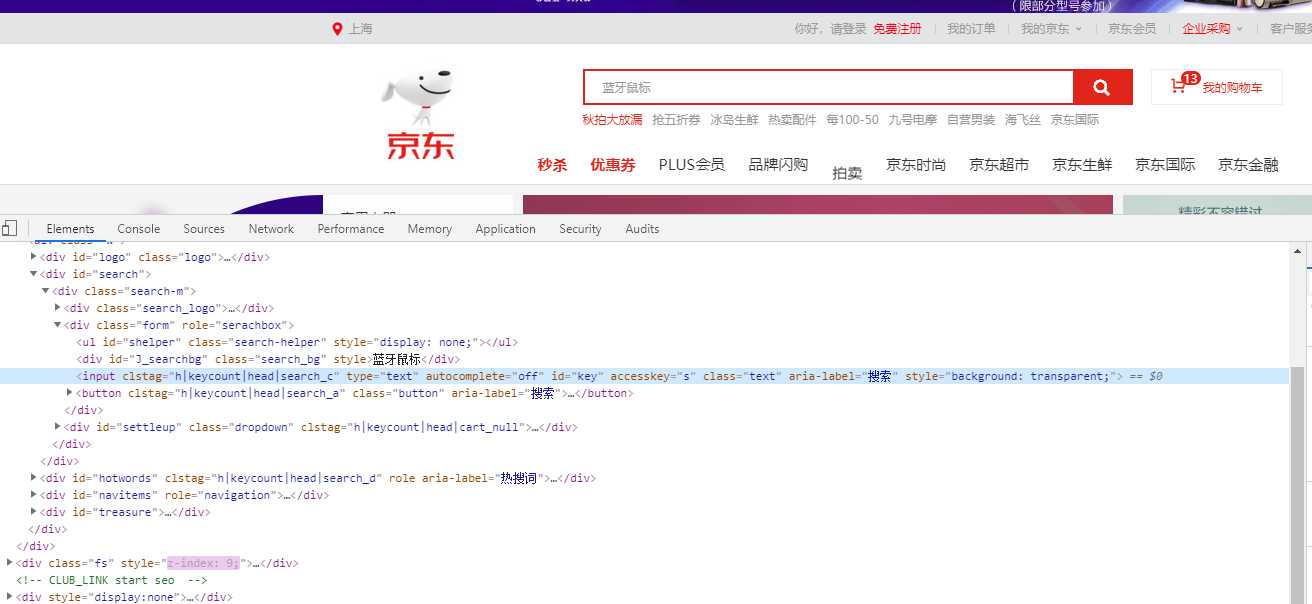
从上面这张图可以看到,我们想要获取输入框,可以通过 id 进行获取,那么我们接下来的代码要这么写:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.jd.com/')
input_key = browser.find_element_by_id('key')
print(input_key)结果如下:
<selenium.webdriver.remote.webelement.WebElement (session="86d1ae1419bee22099a168dfbf921a27", element="53047804-ad39-4dfd-b3fb-a149fb1c8ac8")>可以看到,我们获得的元素类型是 WebElement 。
小编这里顺手列出所有的获得单个节点的方法:
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector此外, selenium 还未我们提供了一个通用方法 find_element() ,它需要传入两个参数:查找方式 By 和值。实际上上面示例中的查找方式还可以这么写(效果完全一样哦~~~):
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get('https://www.jd.com/')
input_key1 = browser.find_element(By.ID, 'key')
print(input_key1)结果小编就不贴了,各位同学可以自己运行下进行对比。
比如我们要查找左边的这种导航条的所有条目:

可以这么写:
lis = browser.find_elements_by_css_selector('.cate_menu li')
print(lis)结果如下:
[<selenium.webdriver.remote.webelement.WebElement (session="6341ab4f39733b5f6b6bd51508b62f1d", element="8e0d1a8c-d5dc-4b1f-8250-7f0eca864ea7")>, <selenium.webdriver.remote.webelement.WebElement (session="6341ab4f39733b5f6b6bd51508b62f1d", element="15cd4dc9-42f4-4ed7-9258-9aa29073243c")>,
......]太多了,小编后面的结果就省略掉了。
下面列出来所有的多节点选择的方法:
find_elements_by_name
find_elements_by_xpath
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_tag_name
find_elements_by_class_name
find_elements_by_css_selector同样,多节点选择也有一个 find_elements() 的方法,小编这里就不展示,各位同学自己试一试。
本篇先到这里,下一篇我们接着介绍交互操作。
本系列的所有代码小编都会放在代码管理仓库 Github 和 Gitee 上,方便大家取用。
https://selenium-python.readthedocs.io/api.html
https://cuiqingcai.com/5630.html
小白学 Python 爬虫(27):自动化测试框架 Selenium 从入门到放弃(上)
标签:docke 比较 人生苦短 基础入门 selenium cookies text nts meteor
原文地址:https://www.cnblogs.com/babycomeon/p/12100183.html