标签:grant ott 连接 基础用法 查看 incr 就会 内存 需求
(操作物理文件目录本身)
#库
#创建库
create database dbname; database schema一样,都是建库的意思
create schema dbname;
#?增加判断,如果已经存在库,会避免程序报错
create database if not exists dbname;
#创建库并设置字符集,default可以不写
create database db1 default charset utf8;
查看如何创建的数据库db1
mysql> show create database db1 ;
+----------+--------------------------------------------------------------+
| Database | Create Database |
+----------+--------------------------------------------------------------+
| db1 | CREATE DATABASE `db1` /*!40100 DEFAULT CHARACTER SET utf8 */ |
+----------+--------------------------------------------------------------+
1 row in set (0.00 sec)
#校验规则,建库时可以指定,源码安装时也可以指定
create database db3 charset utf8 collate utf8_bin;
mysql> show create database db3;
+----------+-------------------------------------------------------------------------------+
| Database | Create Database |
+----------+-------------------------------------------------------------------------------+
| db3 | CREATE DATABASE `db3` /*!40100 DEFAULT CHARACTER SET utf8 COLLATE utf8_bin */ |
+----------+-------------------------------------------------------------------------------+
1 row in set (0.00 sec)#表
#建表
create table student2(
sid int primary key auto_increment,
sname varchar(20) not null,
sage tinyint unsigned not null,
sgender enum('f','m','haoge') default 'm',
cometime datetime default now());
#插入数据
#默认可以不写的参数,需要在表下面添加相对应的别名:student4(sname,sage,sgender)
mysql> insert into s into student4(sname,sage,sgender) values('jiangwei',29,'m');
Query OK, 1 row affected (0.01 sec)
#查看表数据
mysql> select * from student4
-> ;
+-----+----------+------+---------+---------------------+
| sid | sname | sage | sgender | cometime |
+-----+----------+------+---------+---------------------+
| 1 | jiangwei | 29 | m | 2019-12-18 17:00:01 |
+-----+----------+------+---------+---------------------+
1 row in set (0.00 sec)
#如果要求sid从001开始002---003等需要用一个参数?:zerofill
如下:?
create table student4(
sid int(3) zerofill primary key auto_increment,
sname varchar(20) not null,
sage tinyint unsigned not null,
sgender enum('f','m','haoge') default 'm',
cometime datetime default now());
## 规范的建表语句
create table student7(
sid int zerofill primary key auto_increment comment '学号',
sname varchar(20) not null comment '学生姓名',
#not null 必须要填写,不能为空
sage tinyint unsigned not null comment '学生年龄',
#非负并且不能为空,注意unsigned是要约束tinyint的,所以跟在tinyint后面
#加了无符号,数值变成128+128,前面的负的变成正的
sgender enum('f','m') default 'm' comment '学生性别',
#default 默认值为m
cometime datetime default now() comment '入学时间') engine=innodb charset utf8;
#插入数据
mysql> insert into student7 values(1,'jerry',18,'m',now());
Query OK, 1 row affected (0.00 sec)
mysql> select * from student7;
+------------+-------+------+---------+---------------------+
| sid | sname | sage | sgender | cometime |
+------------+-------+------+---------+---------------------+
| 0000000001 | jerry | 18 | m | 2019-12-18 17:27:09 |
+------------+-------+------+---------+---------------------+
1 row in set (0.00 sec)
#comment的注释的目的可以清晰知道代表的意思,是能通过show create table student7;查看
mysql> show create table student7;
+----------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+----------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| student7 | CREATE TABLE `student7` (
`sid` int(10) unsigned zerofill NOT NULL AUTO_INCREMENT COMMENT '学号',
`sname` varchar(20) NOT NULL COMMENT '学生姓名',
`sage` tinyint(3) unsigned NOT NULL COMMENT '学生年龄',
`sgender` enum('f','m') DEFAULT 'm' COMMENT '学生性别',
`cometime` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '入学时间',
PRIMARY KEY (`sid`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8 |
+----------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
drop #库 drop database xxx;
#表 drop table test.student; alter(针对库的改很少)
#库(修改数据库字符集)
alter database zls10 charset utf8;
#表
mysql> create table stu1(haoge varchar(10));
mysql> desc stu1;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| haoge | varchar(10) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
?
-- 添加字段
mysql> alter table stu1 add qls char(10);
-- 在指定字段之前插入字段
mysql> alter table stu1 add dawei int first;
-- 将字段插入到两个字段的中间
mysql> alter table stu1 add feishang varchar(10) after dawei;
-- 删除字段
mysql> alter table stu1 drop haoge;
-- 修改字段的数据类型
mysql> alter table stu1 modify feishang int;
-- 修改字段的名字和数据类型
mysql> alter table stu1 change feishang haoge char(10);
-- 修改字段的约束
mysql> alter table stu1 modify dawei int not null;
-- 修改表名
mysql> alter table stu1 rename stu;
-- 修改id字段为主键字段,且自增
mysql> alter table student1 modify id int primary key auto_increment;(操作文件中的内容)
mysql> desc student7;
+----------+---------------------------+------+-----+-------------------+
| Field | Type | Null | Key | Default |
+----------+---------------------------+------+-----+-------------------+
| sid | int(10) unsigned zerofill | NO | PRI | NULL |
| sname | varchar(20) | NO | | NULL |
| sage | tinyint(3) unsigned | NO | | NULL |
| sgender | enum('f','m','haoge') | YES | | m |
| cometime | datetime | YES | | CURRENT_TIMESTAMP |
+----------+---------------------------+------+-----+-------------------+
?
1.不规范写法
mysql> insert into student7 values(1,'suibian',18,'f',now());
?
2.规范写法
mysql> insert into student7(sname,sage,sgender) values('zls',18,'m');
#插入多行
mysql> insert into student7(sname,sage,sgender) values('qls',20,'f'),('dawei',17,'m');
或
insert into student7(sname,sage,sgender)
values('qls',20,'f'),
('dawei',17,'m');update(危险)
#没有进入任何库,需要加绝对路径test.student7
#这种比较危险,因为没有加条件,所以会全表都生效
mysql> update test.student7 set sgender='f';
1.规范,必须加where条件
mysql> update test.student7 set sgender='m' where sname='zls';
2.就算需求是整列数据都需要修改,也必须加where
mysql> update test.student7 set sage=30 where 1=1;
3.加多条件
mysql> update test.student7 set sname='qls' where sage=31 and sgender='f';delete(危险)
#删除test下的student7表,到一定要加条件
mysql> delete from test.student7;
1.规范,必须加where条件
mysql> delete from test.student7 where sname='zls';
2.就算需求是整列数据都需要删除,也必须加where
mysql> delete from test.student7 where 1=1;#查询表
mysql> select * from student7;
+------------+-------+------+---------+---------------------+
| sid | sname | sage | sgender | cometime |
+------------+-------+------+---------+---------------------+
| 0000000001 | jerry | 18 | m | 2019-12-18 17:27:09 |
| 0000000002 | jiang | 19 | m | 2019-12-19 10:55:39 |
| 0000000003 | zhang | 20 | f | 2019-12-19 10:55:39 |
| 0000000004 | wang | 40 | m | 2019-12-19 16:55:17 |
+------------+-------+------+---------+---------------------+
4 rows in set (0.00 sec)
#用delete删除student7表
mysql> delete from student7 where 1=1;
Query OK, 4 rows affected (0.00 sec)
mysql> select * from student7;
Empty set (0.00 sec)
#此时再插入两行数据
mysql> insert into student7(sname,sage,sgender)
-> values('jerry01',20,'f'),
-> ('jerry02',30,'m');
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0
#我们会发现sid从5开始,什么原因呢?
mysql> select * from student7;
+------------+---------+------+---------+---------------------+
| sid | sname | sage | sgender | cometime |
+------------+---------+------+---------+---------------------+
| 0000000005 | jerry01 | 20 | f | 2019-12-19 17:00:30 |
| 0000000006 | jerry02 | 30 | m | 2019-12-19 17:00:30 |
+------------+---------+------+---------+---------------------+
2 rows in set (0.00 sec)
#使用truncate删除表
mysql> truncate student7;
Query OK, 0 rows affected (0.02 sec)
mysql> select * from student7;
Empty set (0.00 sec)
#再次插入数据
mysql> insert into student7(sname,sage,sgender)
-> values('jerry03',40,'m'),
-> ('jerry04',50,'f');
Query OK, 2 rows affected (0.01 sec)
Records: 2 Duplicates: 0 Warnings: 0
#查看表数据,从1开始。
mysql> select * from student7;
+------------+---------+------+---------+---------------------+
| sid | sname | sage | sgender | cometime |
+------------+---------+------+---------+---------------------+
| 0000000001 | jerry03 | 40 | m | 2019-12-19 17:03:19 |
| 0000000002 | jerry04 | 50 | f | 2019-12-19 17:03:19 |
+------------+---------+------+---------+---------------------+
2 rows in set (0.00 sec)
问题:为什么truncate删除后写数据从头开始,delete删除后从之前的开始?
mysql> show create table student7;
+----------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+----------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| student7 | CREATE TABLE `student7` (
`sid` int(10) unsigned zerofill NOT NULL AUTO_INCREMENT COMMENT '学号',
`sname` varchar(20) NOT NULL COMMENT '学生姓名',
`sage` tinyint(3) unsigned NOT NULL COMMENT '学生年龄',
`sgender` enum('f','m') DEFAULT 'm' COMMENT '学生性别',
`cometime` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '入学时间',
PRIMARY KEY (`sid`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8
# 可以看到这边有个自增AUTO_INCREMENT=3,truncate就没有 |
+----------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
mysql> truncate student7;
Query OK, 0 rows affected (0.02 sec)
mysql> select * from student7;
Empty set (0.00 sec)
mysql> show create table student7;
+----------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+----------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| student7 | CREATE TABLE `student7` (
`sid` int(10) unsigned zerofill NOT NULL AUTO_INCREMENT COMMENT '学号',
`sname` varchar(20) NOT NULL COMMENT '学生姓名',
`sage` tinyint(3) unsigned NOT NULL COMMENT '学生年龄',
`sgender` enum('f','m') DEFAULT 'm' COMMENT '学生性别',
`cometime` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '入学时间',
PRIMARY KEY (`sid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
+----------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)为什么要做伪删除?
目的:伪删除一般是为了数据恢复,这样需要的时候,还可以还原数据。一般对于数据量不大的数据库,如果不是为了空间考虑,就不需要去真实的删除数据,而是通过一个标记来处理。
如何实现?
我们可以给生产的表创建一个状态列,此状态列只有0和1,0代表删除,1代表未删除,0代表的删除就是伪删除,呈现给客户的显示已经删除,但是在数据库中只是由状态1 变成0,实际数据依然存在,当某VIP客户要求恢复数据,我们只需要在数据库将状态0设置成1,就可以实现秒级恢复,这就是伪删除。
那么伪删除的数据会永久存在吗?个人认为,可以设置时间,比如1个月三个月,内存大的服务器可以更久。
具体操作:
#1.先要给生产的表,创建一个状态列
mysql> alter table student7 add state enum('0','1') default '1';
mysql> desc student7;
+----------+---------------------------+------+-----+-------------------+----------------+
| Field | Type | Null | Key | Default | Extra |
+----------+---------------------------+------+-----+-------------------+----------------+
| sid | int(10) unsigned zerofill | NO | PRI | NULL | auto_increment |
| sname | varchar(20) | NO | | NULL | |
| sage | tinyint(3) unsigned | NO | | NULL | |
| sgender | enum('f','m') | YES | | m | |
| cometime | datetime | YES | | CURRENT_TIMESTAMP | |
| state | enum('0','1') | YES | | 1 | |
+----------+---------------------------+------+-----+-------------------+----------------+
6 rows in set (0.00 sec)
#2.插入数据
mysql> insert into student7(sname,sage,sgender) values('qls',20,'f'), ('dawei',17,'m'),('zls',18,'m');
mysql> insert into student7(sname,sage,sgender) values('qls',20,'f'), ('dawei',17,'m'),('zls',18,'m');
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql>
mysql> select * from student7;
+------------+-------+------+---------+---------------------+-------+
| sid | sname | sage | sgender | cometime | state |
+------------+-------+------+---------+---------------------+-------+
| 0000000001 | qls | 20 | f | 2019-12-19 20:09:50 | 1 |
| 0000000002 | dawei | 17 | m | 2019-12-19 20:09:50 | 1 |
| 0000000003 | zls | 18 | m | 2019-12-19 20:09:50 | 1 |
+------------+-------+------+---------+---------------------+-------+
#3.删除数据
mysql> update student7 set state='0' where sid=3;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from student7;
+------------+-------+------+---------+---------------------+-------+
| sid | sname | sage | sgender | cometime | state |
+------------+-------+------+---------+---------------------+-------+
| 0000000001 | qls | 20 | f | 2019-12-19 20:09:50 | 1 |
| 0000000002 | dawei | 17 | m | 2019-12-19 20:09:50 | 1 |
| 0000000003 | zls | 18 | m | 2019-12-19 20:09:50 | 0 |
+------------+-------+------+---------+---------------------+-------+
3 rows in set (0.00 sec)
#4.查询数据
?mysql> select * from student7 where state='1';
+------------+-------+------+---------+---------------------+-------+
| sid | sname | sage | sgender | cometime | state |
+------------+-------+------+---------+---------------------+-------+
| 0000000001 | qls | 20 | f | 2019-12-19 20:09:50 | 1 |
| 0000000002 | dawei | 17 | m | 2019-12-19 20:09:50 | 1 |
+------------+-------+------+---------+---------------------+-------+
2 rows in set (0.00 sec)
#注意:需要和开发统一update替代delete,状态0和1,简单来说用:户删除---开发程序得到消息---状态要变成0----消息下达到数据库----数据库得到消息程序里就会执行 update from xxx.xxx where id=1;然后查询的时候 ,select * from xxx.xxx where state=1;
别吐槽,我都说了,简单来说。
最终客户查询时看到的是已删除的界面,但数据依然在服务器中。#grant
grant all on *.* to root@'%' identified by '123' with grant option;
#其他参数(扩展)
max_queries_per_hour:一个用户每小时可发出的查询数量
max_updates_per_hour:一个用户每小时可发出的更新数量
max_connections_per_hour:一个用户每小时可连接到服务器的次数
max_user_connections:允许同时连接数量
?
grant select on test.* to dev@'%' identified by '123' with grant option max_user_connections 1;
?
grant select,update on test.* to dev5@'%' identified by '123' with
grant option
max_user_connections 2
max_queries_per_hour 4
max_updates_per_hour 2
max_connections_per_hour 3;
?
#revoke回收权限
mysql> revoke select on test.* from dev5@'%';mysql> source /root/world.sql
mysql> show tables from world;
+-----------------+
| Tables_in_world |
+-----------------+
| city | #城市表
| country | #国家表
| countrylanguage | #国家语言表
mysql> select * from world.city; mysql> select id,name from world.city; (京东一页60个商品,数据库就是这样的方式排序的)
mysql> select * from city limit 10;
+----+----------------+-------------+---------------+------------+
| ID | Name | CountryCode | District | Population |
+----+----------------+-------------+---------------+------------+
| 1 | Kabul | AFG | Kabol | 1780000 |
| 2 | Qandahar | AFG | Qandahar | 237500 |
| 3 | Herat | AFG | Herat | 186800 |
| 4 | Mazar-e-Sharif | AFG | Balkh | 127800 |
| 5 | Amsterdam | NLD | Noord-Holland | 731200 |
| 6 | Rotterdam | NLD | Zuid-Holland | 593321 |
| 7 | Haag | NLD | Zuid-Holland | 440900 |
| 8 | Utrecht | NLD | Utrecht | 234323 |
| 9 | Eindhoven | NLD | Noord-Brabant | 201843 |
| 10 | Tilburg | NLD | Noord-Brabant | 193238 |
+----+----------------+-------------+---------------+------------+
?
mysql> select * from world.city where countrycode='CHN' limit 0,60; #第一页
mysql> select * from world.city where countrycode='CHN' limit 60,60; #第二页
mysql> select * from world.city where countrycode='CHN' limit 120,60; #第三页mysql> select * from world.city where countrycode='CHN' order by population desc limit 0,60;
#以京东为例?
select * from 京东 where 商品名称='gucci' order by 价格 limit 0,60;?
#as设置别名
mysql> select id as 商品序号,name as 商品名称,countrycode as 商品别名,district as 商品厂商,population as 商品价格 from world.city wherre countrycode='CHN' order by population desc limit 0,10;
+--------------+--------------------+--------------+--------------+--------------+
| 商品序号 | 商品名称 | 商品别名 | 商品厂商 | 商品价格 |
+--------------+--------------------+--------------+--------------+--------------+
| 4080 | zls | CHN | zls | 9999999 |
| 1890 | Shanghai | CHN | Shanghai | 9696300 |
| 1891 | Peking | CHN | Peking | 7472000 |
| 1892 | Chongqing | CHN | Chongqing | 6351600 |
| 1893 | Tianjin | CHN | Tianjin | 5286800 |
| 1894 | Wuhan | CHN | Hubei | 4344600 |
| 1895 | Harbin | CHN | Heilongjiang | 4289800 |
| 1896 | Shenyang | CHN | Liaoning | 4265200 |
| 1897 | Kanton [Guangzhou] | CHN | Guangdong | 4256300 |
| 1898 | Chengdu | CHN | Sichuan | 3361500 |
+--------------+--------------------+--------------+--------------+--------------+#计算类的函数:
count:统计
sum:求和
avg:平均值
min:最小值
max:最大值
distinct:去重
#此时此刻,我想吟诗一首
1.遇到统计想函数
2.形容词前groupby
3.函数中央是名词
4.列名select后添加
#统计世界上每个国家的总人口数
1.sum()
2.group by countrycode
3.sum(population)
??
select countrycode,sum(population) from world.city group by countrycode;
+-------------+-----------------+
| CountryCode | sum(Population) |
+-------------+-----------------+
| ABW | 29034 |
| AFG | 2332100 |
| AGO | 2561600 |
| AIA | 1556 |
| ALB | 270000 |
| AND | 21189 |
| ANT | 2345 |
| ARE | 1728336 |
| ARG | 19996563 |
| ARM | 1633100 |
| ASM | 7523 |
| ATG | 24000 |
| AUS | 11313666 |
...省略#统计中国各个省的人口数量
sum()
group by district
sum(population)
?
mysql> select countrycode,district,sum(population) from world.city where countrycode='chn' group by district;
+----------------+-----------------+
| District | sum(Population) |
+----------------+-----------------+
| Anhui | 5141136 |
| Chongqing | 6351600 |
| Fujian | 3575650 |
| Gansu | 2462631 |
| Guangdong | 9510263 |
| Guangxi | 2925142 |
| Guizhou | 2512087 |
| Hainan | 557120 |
| Hebei | 6458553 |
| Heilongjiang | 11628057 |
| Henan | 6899010 |
| Hubei | 8547585 |
....省略#模糊查询,只要带H就能查询
mysql> select * from city where countrycode like '%H%';
#以H开头
mysql> select * from city where countrycode like 'h%';
#以H结尾
mysql> select * from city where countrycode like '%h';#多条件查询(一般来说,and接两个不相同的字段)
mysql> select * from city where countrycode='chn' and population > 100000;
mysql> select * from city where countrycode='chn' or countrycode='usa';
mysql> select * from city where countrycode in ('chn','usa'); mysql> explain select * from city where countrycode='chn' union all select * from city where countrycode='usa'; mysql> select * from city where population < 100;
mysql> select * from city where population != 100;
mysql> select * from city where population <> 100;
mysql> select * from city where population>100 and population<200;关系型数据库,免不了表之间存在各种引用与关联。这些关联是通过主键与外键搭配来形成的。 所以,取数据时,很大情况下单张表无法满足需求,额外的数据则需要将其他表加入到查询中来, 这便是联表查询的操作。
1:主键和外键的定义
主键(primary key):一列(或一组列),其值能够唯一区分表中每个行 。
外键(foreign key) 外键为某个表中的一列,它包含另一个表的主键值,定义了两个表之间的关系
借用其他博客中的三个数据表解析一下:
学生表(学号,姓名,性别,班级) // 学号唯一,能确定学生表的一行
课程表(课程编号,课程名,学分) // 课程编号唯一,能确定课程表的一行
成绩表(学号,课程号,成绩) // 学号和课程号才能唯一确定哪个人哪门课得了多少分,学号和课程号这两列为主键
2:是哪个表的外键?
以上面的成绩表为例,学号和课程号是成绩表的主键,那么学号是成绩表的外键还是学生表的外键?当然是成绩表的外键,
因为学号是学生表的主键呀,怎么可能是外键?同理成绩表课程号也应该是成绩表的外键。其实,外键主要建立与其他表的联系,
如果我们想知道成绩表中某一行成绩是谁考的,啥性别,在哪个班级,就可通过成绩表的外键学号与学生表建立一种关系。# 世界上人口数量小于100的城市在哪个国家,人口数是多少?
国家名 城市名 人口数量
country.name city.name city.population
select country.name as 国家名,city.name as 城市名,city.population as 城市人口数量
from city,country
where city.countrycode=country.code
and city.population < 100;
+-----------+-----------+--------------------+
| 国家名 | 城市名 | 城市人口数量 |
+-----------+-----------+--------------------+
| Pitcairn | Adamstown | 42 |
+-----------+-----------+--------------------+
#世界上人口数量小于100的城市在哪个国家,人口数量是多少,说的什么语言?
国家名 城市名 城市人口数量 语言
country.name city.name city.population countrylanguage.language
select country.name,city.name,city.population,countrylanguage.language
from city,country,countrylanguage
where city.countrycode=country.code
and country.code=countrylanguage.countrycode
and city.population<100;
+----------+-----------+------------+-------------+
| name | name | population | language |
+----------+-----------+------------+-------------+
| Pitcairn | Adamstown | 42 | Pitcairnese |
+----------+-----------+------------+-------------+### inner join on (inner可以忽略)
# 世界上 人口数量小于100的城市,在哪个国家,人口数量是多少?
国家名 城市名 城市人口数量
country.name city.name city.population
select country.name,city.name,city.population
from city join country
on city.countrycode=country.code
where city.population<100;
+----------+-----------+------------+
| name | name | population |
+----------+-----------+------------+
| Pitcairn | Adamstown | 42 |
+----------+-----------+------------+
#世界上人口数量小于100的城市在哪个国家,人口数量是多少,说的什么语言?
国家名 城市名 城市人口数量 语言
country.name city.name city.population countrylanguage.language
# A join B on 1 join C on 2 join D on 3
select country.name,city.name,city.population,countrylanguage.language
from countrylanguage join city
on countrylanguage.countrycode=city.countrycode
join country
on city.countrycode=country.code
where city.population<100;
+----------+-----------+------------+-------------+
| name | name | population | language |
+----------+-----------+------------+-------------+
| Pitcairn | Adamstown | 42 | Pitcairnese |
+----------+-----------+------------+-------------+注意:一般来说,我们需要,小表在前,大表在后
### natural join
大前提条件:两个表的等价条件,必须有相同的字段名
## 人口数量小于100的城市,国家代码是什么,说的什么语言,人口数量是多少?
国家代码 城市名 语言 城市人口数量
city.countrycode city.name countrylanguage.language city.population
select city.countrycode,city.name,countrylanguage.language,city.population
from countrylanguage natural join city
where city.population<100;
#countrylanguage表和city表里都有countrycode字段,所以可以使用natural join
mysql> select city.countrycode,city.name,countrylanguage.language,city.population
-> from countrylanguage natural join city
-> where city.population<100;
+-------------+-----------+-------------+------------+
| countrycode | name | language | population |
+-------------+-----------+-------------+------------+
| PCN | Adamstown | Pitcairnese | 42 |
+-------------+-----------+-------------+------------+left join 是left outer join的简写,它的全称是左外连接,是外连接中的一种。(只显示左边的 表)
如下图:左(外)连接,左表(a_table)的记录将会全部表示出来,而右表(b_table)只会显示符合搜索条件的记录。右表记录不足的地方均为NULL。
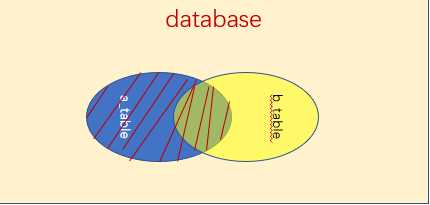
mysql> select city.name,country.code,country.name
-> from city left join country
-> on city.countrycode=country.code
-> and city.population<100 limit 10;
+----------------+-------------+------+
| name | countrycode | name |
+----------------+---- ---------+------+
| Kabul | AFG | NULL |
| Qandahar | AFG | NULL |
| Herat | AFG | NULL |
| Mazar-e-Sharif | AFG | NULL |
| Amsterdam | NLD | NULL |
| Rotterdam | NLD | NULL |
| Haag | NLD | NULL |
| Utrecht | NLD | NULL |
| Eindhoven | NLD | NULL |
| Tilburg | NLD | NULL |
+----------------+-------------+------+right join是right outer join的简写,它的全称是右外连接,是外连接中的一种。(只显示右边的 表)
如下图:与左(外)连接相反,右(外)连接,左表(a_table)只会显示符合搜索条件的记录,而右表(b_table)的记录将会全部表示出来。左表记录不足的地方均为NULL。
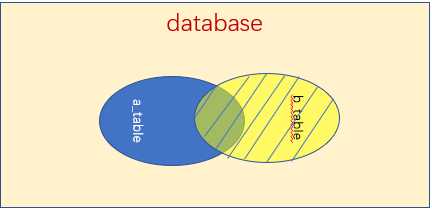
mysql> select city.name,city.countrycode,country.name
-> from city right join country
-> on city.countrycode=country.code
-> and city.population<100 limit 10;
+------+-------------+----------------------+
| name | countrycode | name |
+------+-------------+----------------------+
| NULL | NULL | Aruba |
| NULL | NULL | Afghanistan |
| NULL | NULL | Angola |
| NULL | NULL | Anguilla |
| NULL | NULL | Albania |
| NULL | NULL | Andorra |
| NULL | NULL | Netherlands Antilles |
| NULL | NULL | United Arab Emirates |
| NULL | NULL | Argentina |
| NULL | NULL | Armenia |
+------+-------------+----------------------+
10 rows in set (0.00 sec)
字符集:是一个系统支持的所有抽象字符的集合。字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。
#查看字符集 mysql> show charset;
#校验规则 mysql> show collation; mysql> show collation where charset='utf8';
+--------------------------+---------+-----+---------+----------+---------+
| Collation | Charset | Id | Default | Compiled | Sortlen |
+--------------------------+---------+-----+---------+----------+---------+
| utf8_general_ci | utf8 | 33 | Yes | Yes | 1 |
| utf8_bin | utf8 | 83 | | Yes | 1 |
| utf8_unicode_ci | utf8 | 192 | | Yes | 8 |
| utf8_icelandic_ci | utf8 | 193 | | Yes | 8 |
| utf8_latvian_ci | utf8 | 194 | | Yes | 8 |
| utf8_romanian_ci | utf8 | 195 | | Yes | 8 |
| utf8_slovenian_ci | utf8 | 196 | | Yes | 8 |
| utf8_polish_ci | utf8 | 197 | | Yes | 8 |
| utf8_estonian_ci | utf8 | 198 | | Yes | 8 |
| utf8_spanish_ci | utf8 | 199 | | Yes | 8 |
| utf8_swedish_ci | utf8 | 200 | | Yes | 8 |
| utf8_turkish_ci | utf8 | 201 | | Yes | 8 |
| utf8_czech_ci | utf8 | 202 | | Yes | 8 |
| utf8_danish_ci | utf8 | 203 | | Yes | 8 |
| utf8_lithuanian_ci | utf8 | 204 | | Yes | 8 |
| utf8_slovak_ci | utf8 | 205 | | Yes | 8 |
| utf8_spanish2_ci | utf8 | 206 | | Yes | 8 |
| utf8_roman_ci | utf8 | 207 | | Yes | 8 |
| utf8_persian_ci | utf8 | 208 | | Yes | 8 |
| utf8_esperanto_ci | utf8 | 209 | | Yes | 8 |
| utf8_hungarian_ci | utf8 | 210 | | Yes | 8 |
| utf8_sinhala_ci | utf8 | 211 | | Yes | 8 |
| utf8_german2_ci | utf8 | 212 | | Yes | 8 |
| utf8_croatian_ci | utf8 | 213 | | Yes | 8 |
| utf8_unicode_520_ci | utf8 | 214 | | Yes | 8 |
| utf8_vietnamese_ci | utf8 | 215 | | Yes | 8 |
| utf8_general_mysql500_ci | utf8 | 223 | | Yes | 1 |
+--------------------------+---------+-----+---------+----------+---------+
mysql> show collation like '%cs';
+--------------------+---------+----+---------+----------+---------+
| Collation | Charset | Id | Default | Compiled | Sortlen |
+--------------------+---------+----+---------+----------+---------+
| latin1_general_cs | latin1 | 49 | | Yes | 1 |
| latin2_czech_cs | latin2 | 2 | | Yes | 4 |
| cp1250_czech_cs | cp1250 | 34 | | Yes | 2 |
| latin7_estonian_cs | latin7 | 20 | | Yes | 1 |
| latin7_general_cs | latin7 | 42 | | Yes | 1 |
| cp1251_general_cs | cp1251 | 52 | | Yes | 1 |
+--------------------+---------+----+---------+----------+---------+
ci结尾的校验规则: 不区分大小写
bin和cs结尾的校验规则:严格区分大小写#操作系统C6
[root@db01 ~]# vim /etc/syscofig/i18n
#操作系统C7
[root@db01 ~]# vim /etc/locale.conf
LANG="en_US.UTF-8"
#数据库设置字符集
vim /etc/my.cnf
character_set_server=utf8
#建库语句
mysql> create database xxx charset utf8;
#建表语句
mysql> create table xxx(id int)charset utf8;思考:在生产环境中,字符集不够用
mysql> alter table aaa charset gbk;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show create table aaa;
+-------+--------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+--------------------------------------------------------------------------------------+
| aaa | CREATE TABLE `aaa` (
`id` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=gbk |
+-------+--------------------------------------------------------------------------------------+
在生产中,只能将小的字符集改成大的字符集。
举例子:
latin1 1-5000
utf8 2-65535
gbk 4000-65535
utf8mb4 1-90000
#修改字符集前先要去查询是否有包含的关系,如果有才可以修改,如上:latin1不能改成utf8,可以改成utf8mb4标签:grant ott 连接 基础用法 查看 incr 就会 内存 需求
原文地址:https://www.cnblogs.com/captain-jiang/p/12109673.html