标签:blog http sp 数据 2014 问题 log bs 时间
声明:本文是对 xuetangx 清华大学 丁俊晖 老师 数据结构 课程的个人总结。
冒泡排序的原理很简单:
每一次扫描,遇到相邻逆序队就交换,这样,每一趟扫描下来,当前区间最大值都被交换到区间最后位置,而问题规模相应的 -1。
算法复杂度是 O(n^2) 的,毫无疑问。算法正确性也毫无疑问。
考虑如何优化:
对于我们尚未确定最终位置的左边的无序区间,有可能含有一部分甚至是所有的元素都是有序的。
如下图:
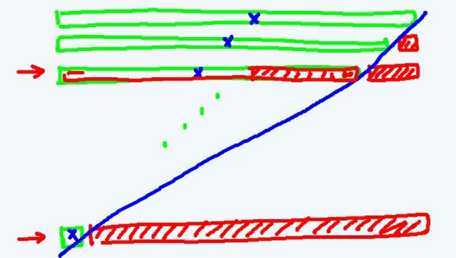
我们如何提前判断结束这个算法呢?
实际上,我们这里判断有序的依据是:相邻元素都是顺序的。
由此得出一个改进策略:
每一趟扫描交换,都记录下是否存在逆序元素。
存在的情况是,当且仅当做过交换。
如果没有做过扫描交换,我们即可判断整个区间有序。
实现如下:

时间复杂度前后对比如图:
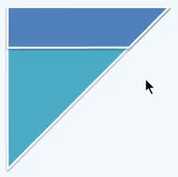
继续考虑改进:
考虑这样一个例子:
初始区间很大的后缀部分已然有序,而无序部分都集中在区间很小的一个前缀区间内。
即便大后缀已经有序,有序每次前缀中都存在交换,所以依然我们每次会依次扫描到整个区间末尾。
而需要扫描 前缀长度 r 趟,即直到前缀有序。
整个算法复杂度是 O(n*r) 的。
我们发现,上例中多余出来的时间消耗就是对已就位后缀的扫描。而显然对这些元素的扫描都是不必的。
改进应运而生:即每趟扫描记录最后一次进行交换的位置。
那么记录位置的后缀就都是已经就位了的。
实现:

不同点就在于 last 记录位置。
这种一次性将有序区间扩大很多而不是每次只将有序区间扩大一个位置的情况,
可能就出现在某趟扫描交换后,而不仅仅是第一次扫描后。
即我们每次都会聪明的找到最大的有序后缀。
时间对比:
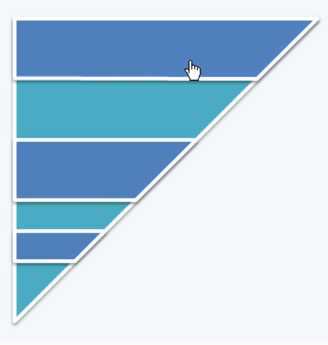
这个多个梯形的面积和,至少是不大于上面那一个梯形的面积的。
当然,以上改进,在最坏的情况下,依然是于事无补的,依然是 O(n^2) 的时间。
综合评价:
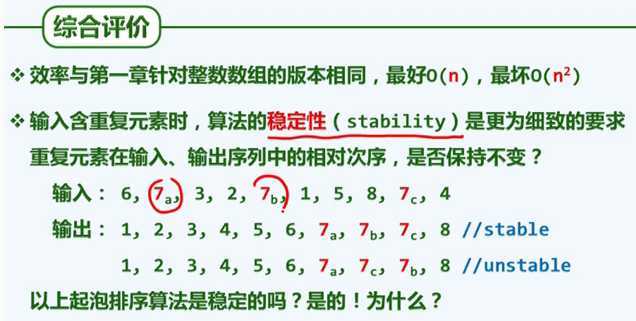

if 条件中是 严格 > 而不是 >=,所以保证了稳定性。
然而,有太多跟冒泡排序复杂度在数量级上存在差别的排序算法,但这种一步一步优化的过程,或者说思维,值得探究。
标签:blog http sp 数据 2014 问题 log bs 时间
原文地址:http://www.cnblogs.com/maples7/p/4065976.html