标签:最大 数据 har 切换 buffer 技术 dem nbsp mesi
一、重排序场景

class ResortDemo {
int a = 0;
boolean flag = false;
public void writer() {
a = 1; //1
flag = true; //2
}
Public void reader() {
if (flag) { //3
int i = a * a; //4
……
}
}
}
当两个线程 A 和 B,A 首先执行writer() 方法,随后 B 线程接着执行 reader() 方法。线程B在执行操作4时,能否看到线程 A 在操作1对共享变量 a 的写入?
答案是:不一定能看到。
由于操作1和操作2没有数据依赖关系,编译器和处理器可以对这两个操作重排序;同样,操作3和操作4没有数据依赖关系,编译器和处理器也可以对这两个操作重排序。
二、追根溯源
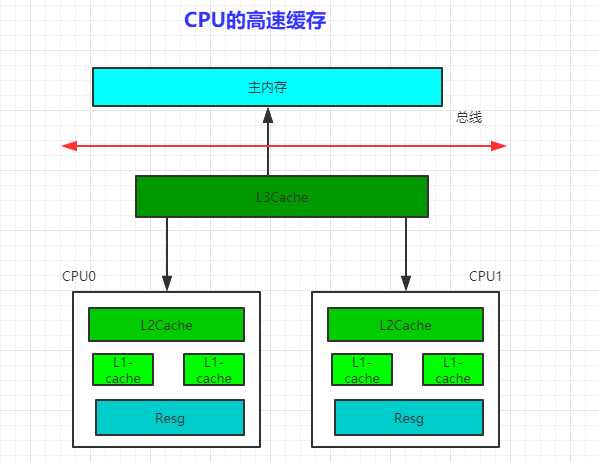
三、缓存一致性协议
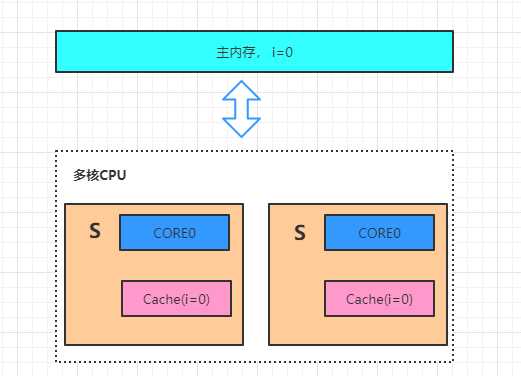
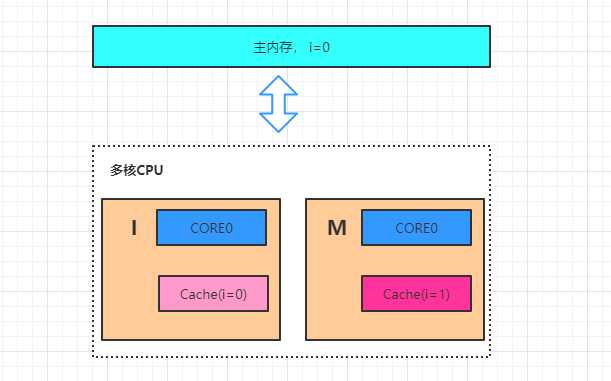
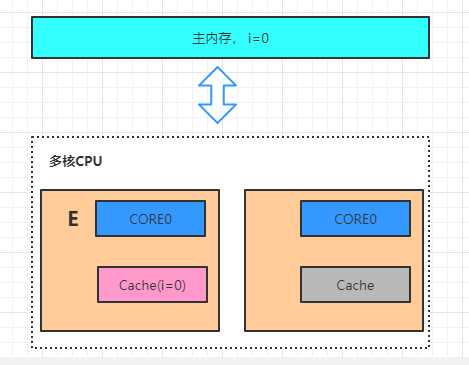
四、重排序原因
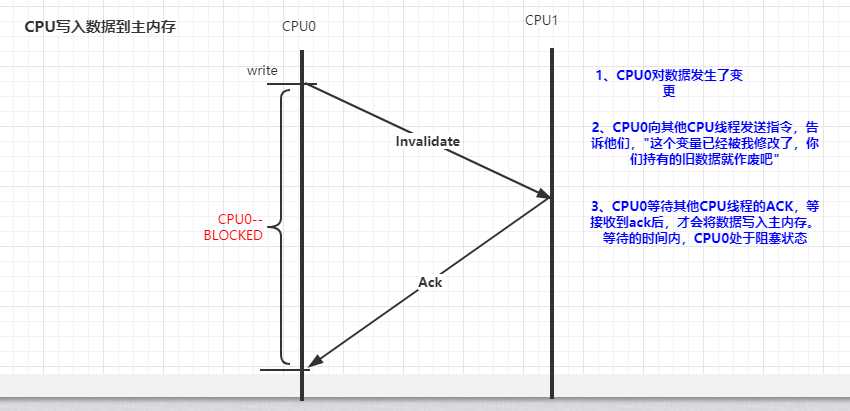
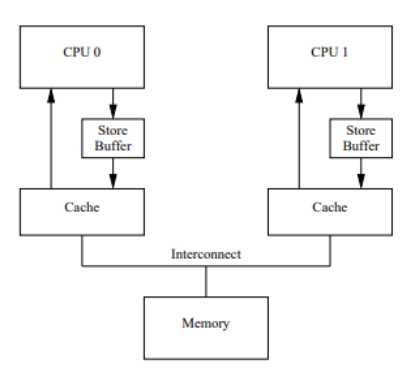
基于上图中的原因,CPU又引入了storeBuffers的缓冲区。CPU0 只需要在写入共享数据时,直接把数据写入到 storebufferes 中,同时发送 invalidate 消息,然后继续去处理其
这个时候,我们再来看上述标题一中的重排序场景。
class ResortDemo {
int a = 0;
boolean flag = false;
public void writer() {
a = 1; //1
flag = true; //2
}
Public void reader() {
if (flag) { //3
int i = a * a; //4
……
}
}
}
当执行1操作时,a的状态从S->M,此时,线程A会先把变更写入到storebuffers,然后发送invalidate去异步通知其他CPU线程,紧接着就执行了下面的2操作。
此时,可能1的变更还在storebuffers中,并未提交到主内存。什么时候会提交到主内存,也不确定。
所以,线程B调用read方法可能会出现,看到了flag的变更,但是看不到a的变更,就出现了重排序的现象。
标签:最大 数据 har 切换 buffer 技术 dem nbsp mesi
原文地址:https://www.cnblogs.com/minikobe/p/12123661.html