标签:sele 样本 取值 str 迭代 全局最优 log 公式 chm
目录
@(机器学习(2)之回归算法)
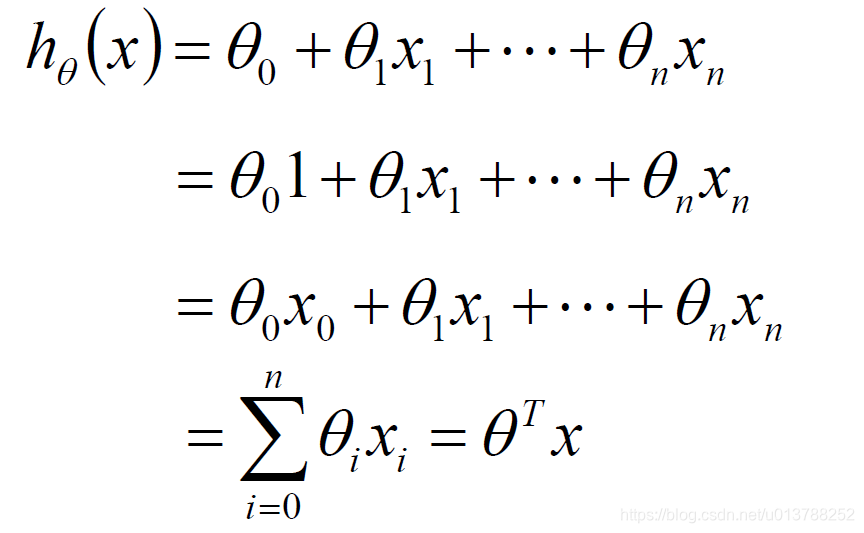
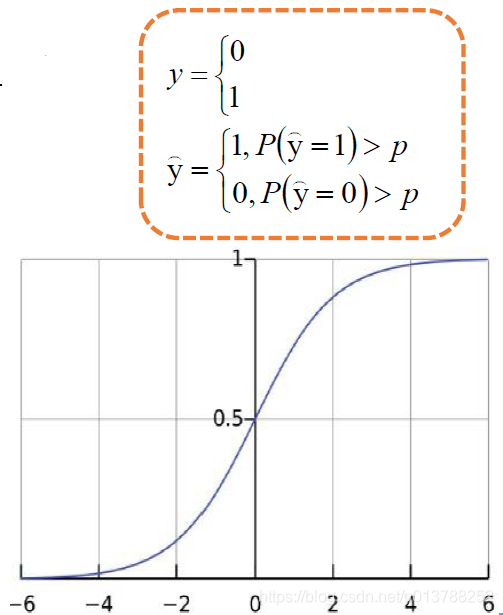
最终要求是计算出 θ 的值,并选择最优的 θ值构成算法公式
可以写为
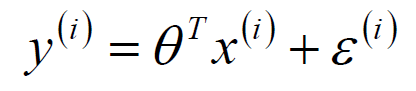
其中ε^(i)^是误差,独立同分布的,服从均值为0,方差为某定值δ^2^的高斯分布。
即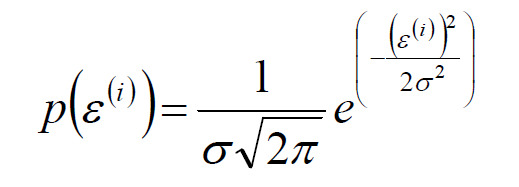
似然函数
(释然函数的概念可以参考:https://segmentfault.com/a/1190000014373677?utm_source=channel-hottest)
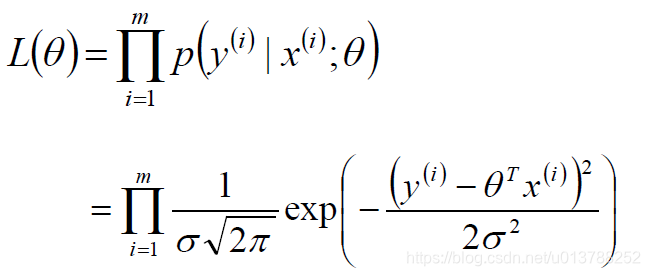
注:似然函数里面用的是正态分布,实际问题中,很多随机现象可以看做众多因素的独立影响的综合反应,往往服从正态分布。
对数似然函数
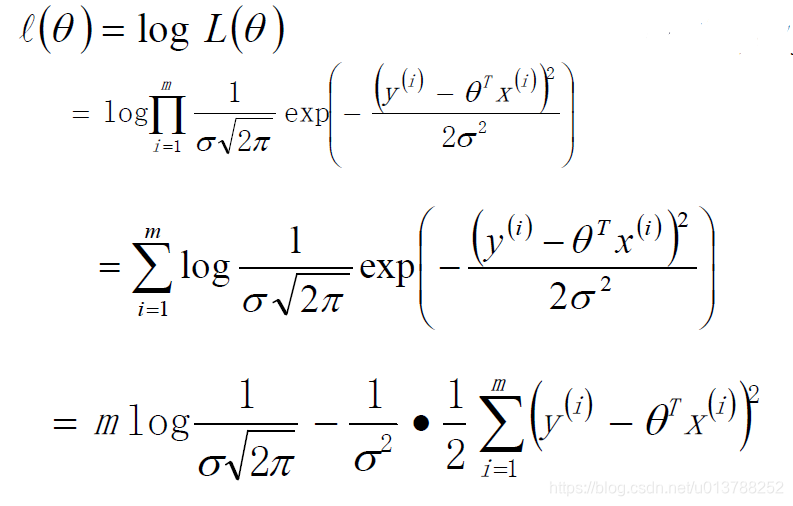
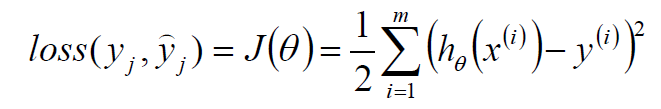
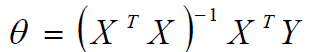

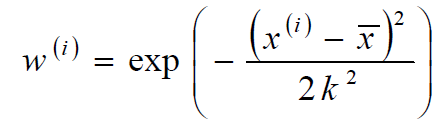
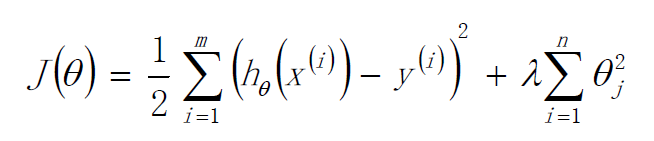
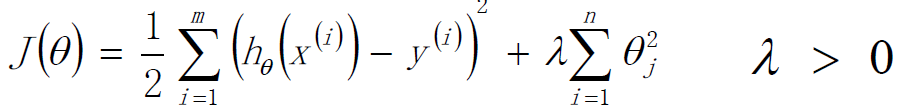
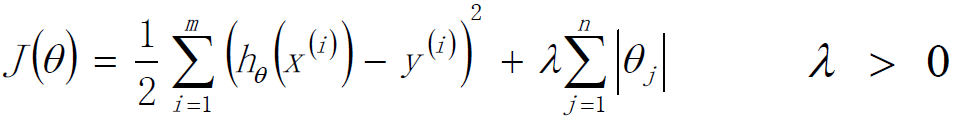
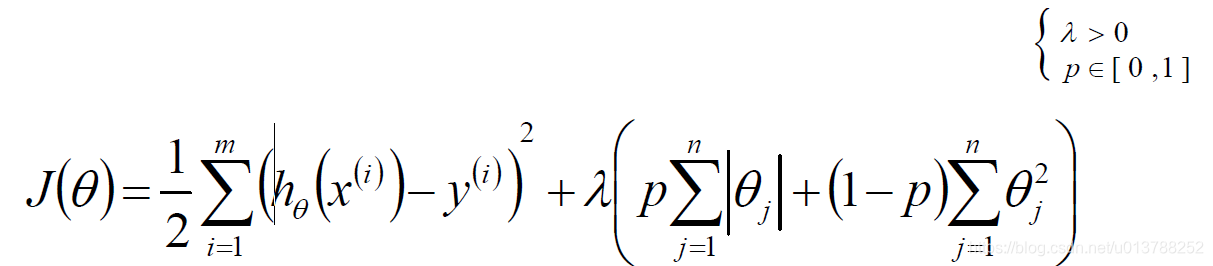
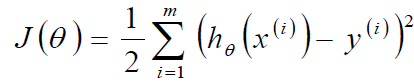
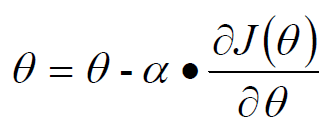
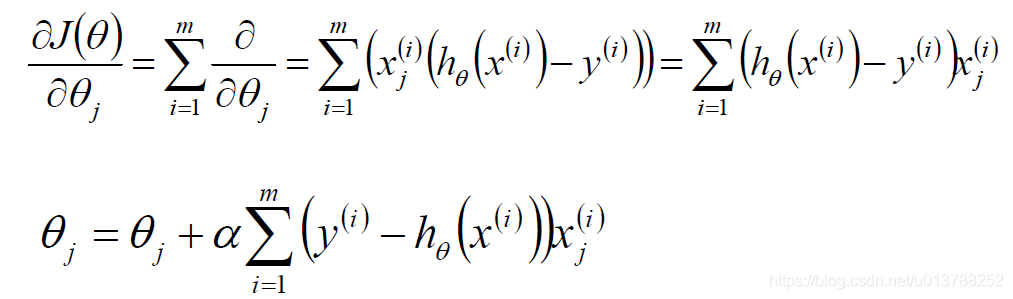
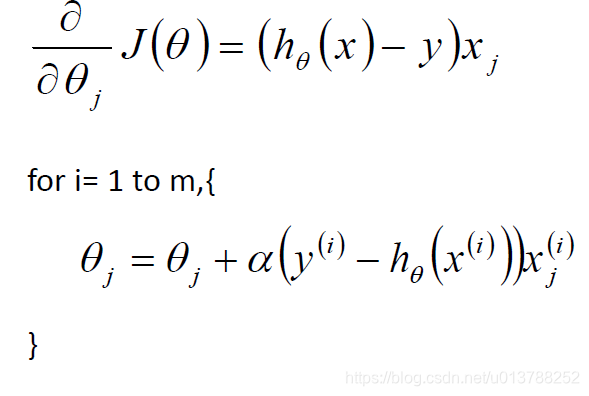
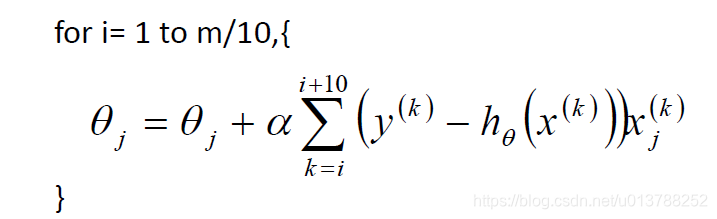
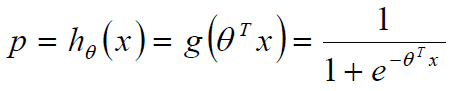
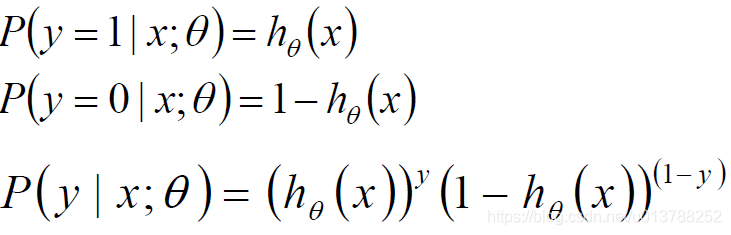
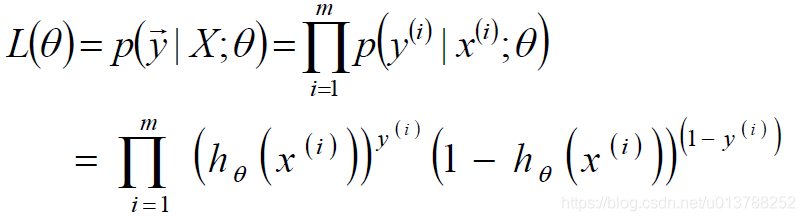
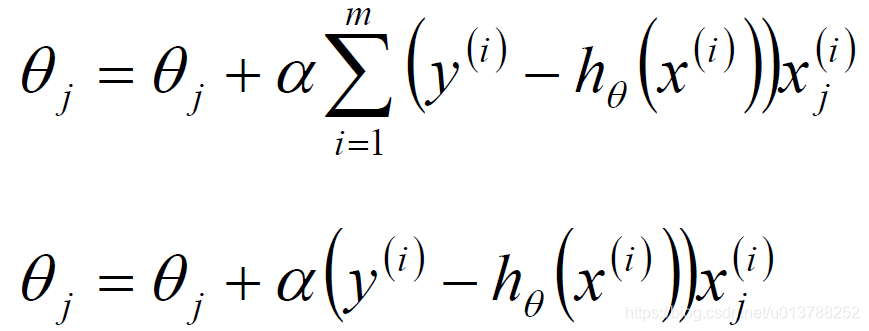
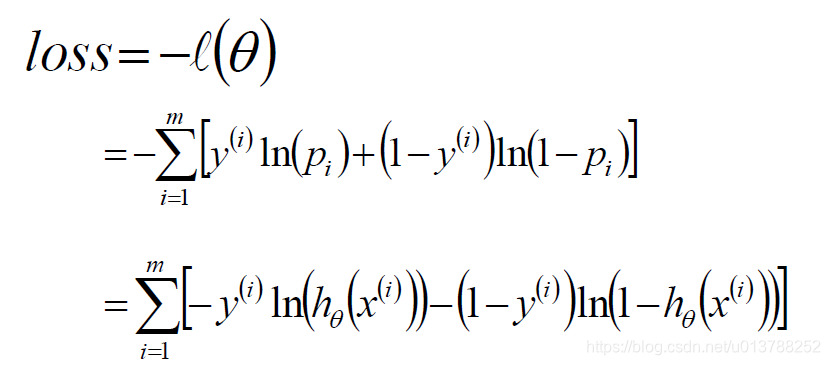
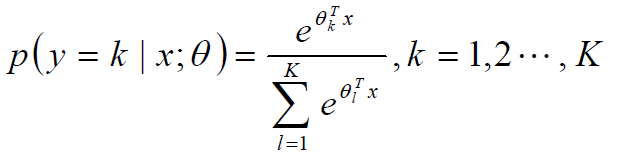
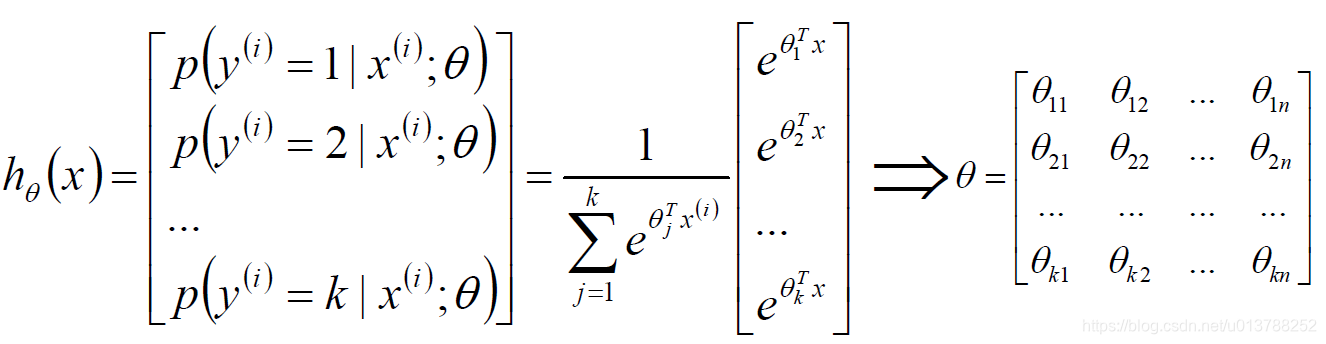
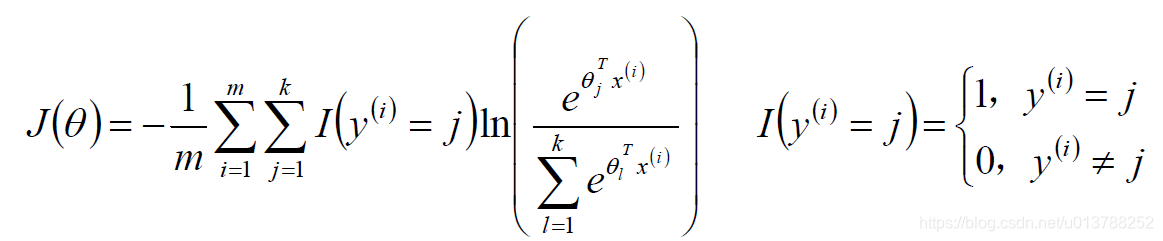
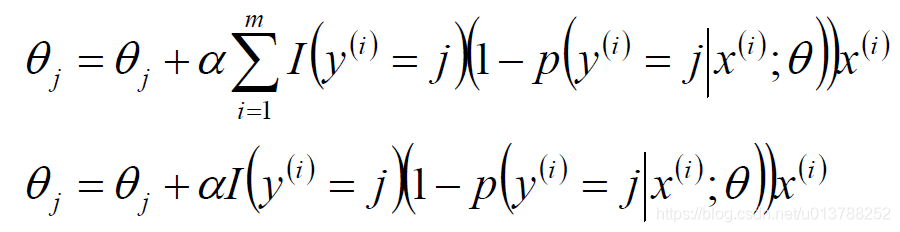
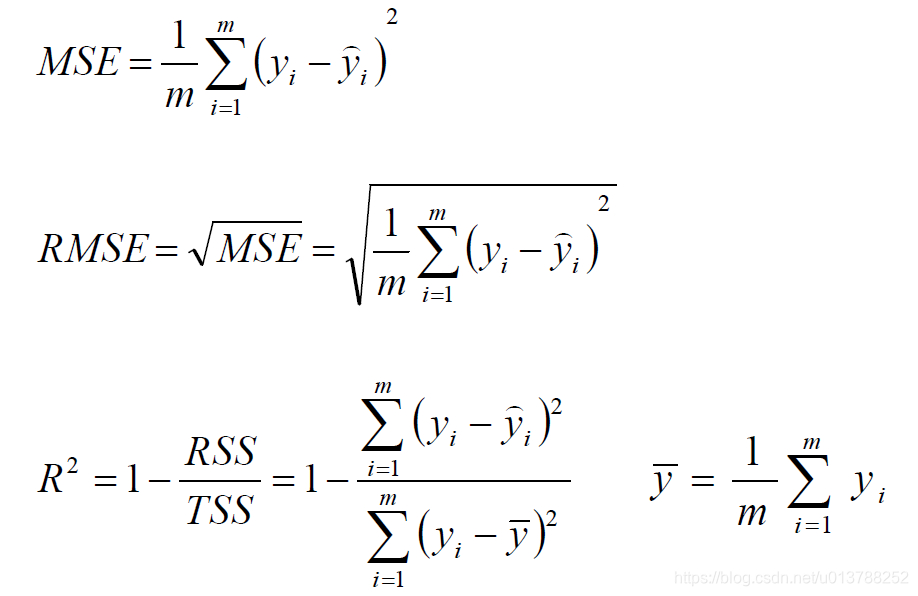
标签:sele 样本 取值 str 迭代 全局最优 log 公式 chm
原文地址:https://www.cnblogs.com/tankeyin/p/12123695.html