Urllib库是python中的一个功能强大的,用于操做URL,并在做爬虫的时候经常要用到的库,在python2中,分为Urllib和Urllib2两个库,在python3之后就将两个库合并到Urllib库中,使用方法有所不同,我使用的是python3。
第一步,先导入Urllib库对应的模块,import urllib.request 或者直接导入request模块 from urllib import request

from urllib import request file = request.urlopen("http://www.baidu.com") #urlopen打开并爬取一个页面,并将值赋给file,以百度为例 data = file.read() #read()读取全部能容 dataline = file.readline() #readline()只读取一行 # 分别打印两个值 print(dataline) print(data)
打印结果:
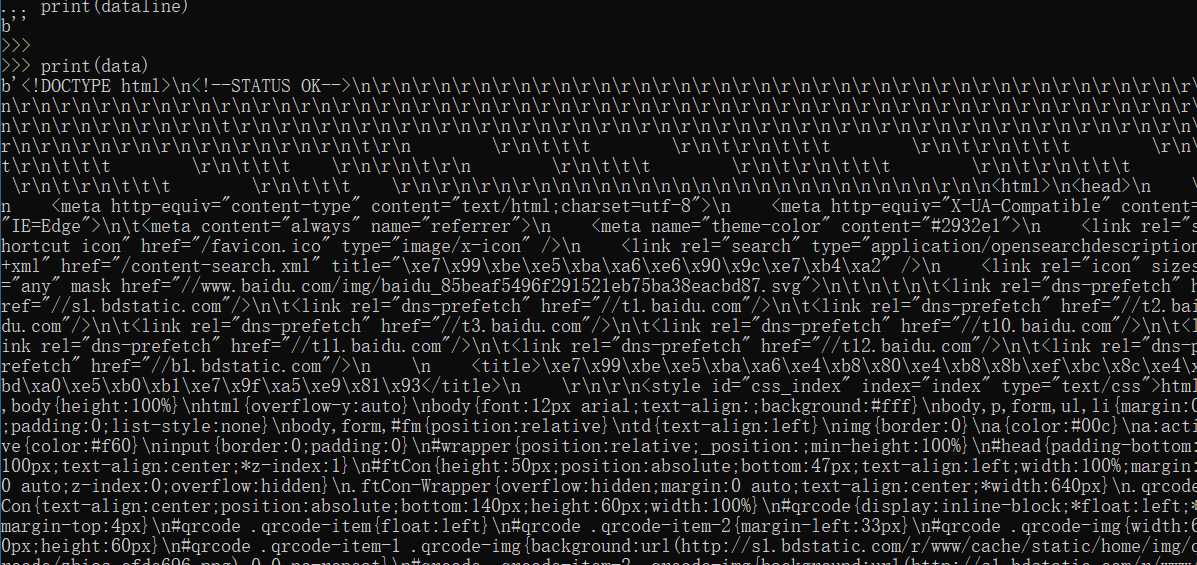
这样就将获取的网页的HTML代码爬取下来了
爬取到数据之后我们怎么将爬取的网页以网页的形式进行保存
from urllib import request file = request.urlopen("http://www.baidu.com") data = file.read() fhandle = open("F:/爬虫/1.html","wb") #通过open()函数打开该文件,“wb”以二进制写入形式打开,不会的话可以学习一下之前的python的文件写入操作。 #文件目录自己先创建 fhandle.write(data) #将data数据写入到 fhandle.close() #将文件关闭
然后找到该文件,用浏览器打开
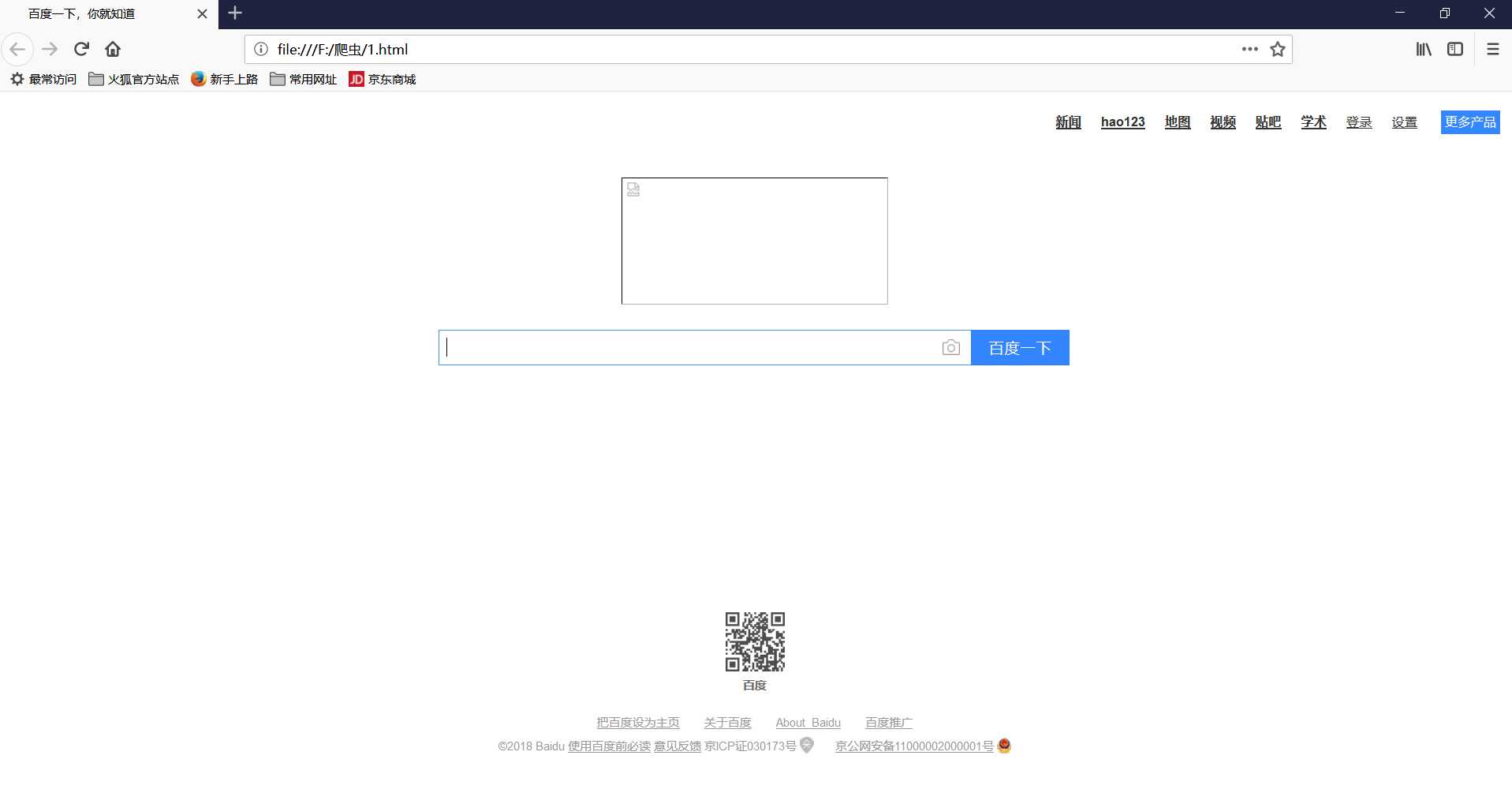
图片信息还未爬取,但至此我们已经网页爬取并保存。
还有一种直接使用request模块中的urlretrieve函数直接写入
格式:urlretrieve(url,filename=本地地址)
from urllib import request filename=request.urlretrieve("http://www.qq.com",filename="F:/爬虫/2.html" )
然后查看保存的路径下的文件,打开之后
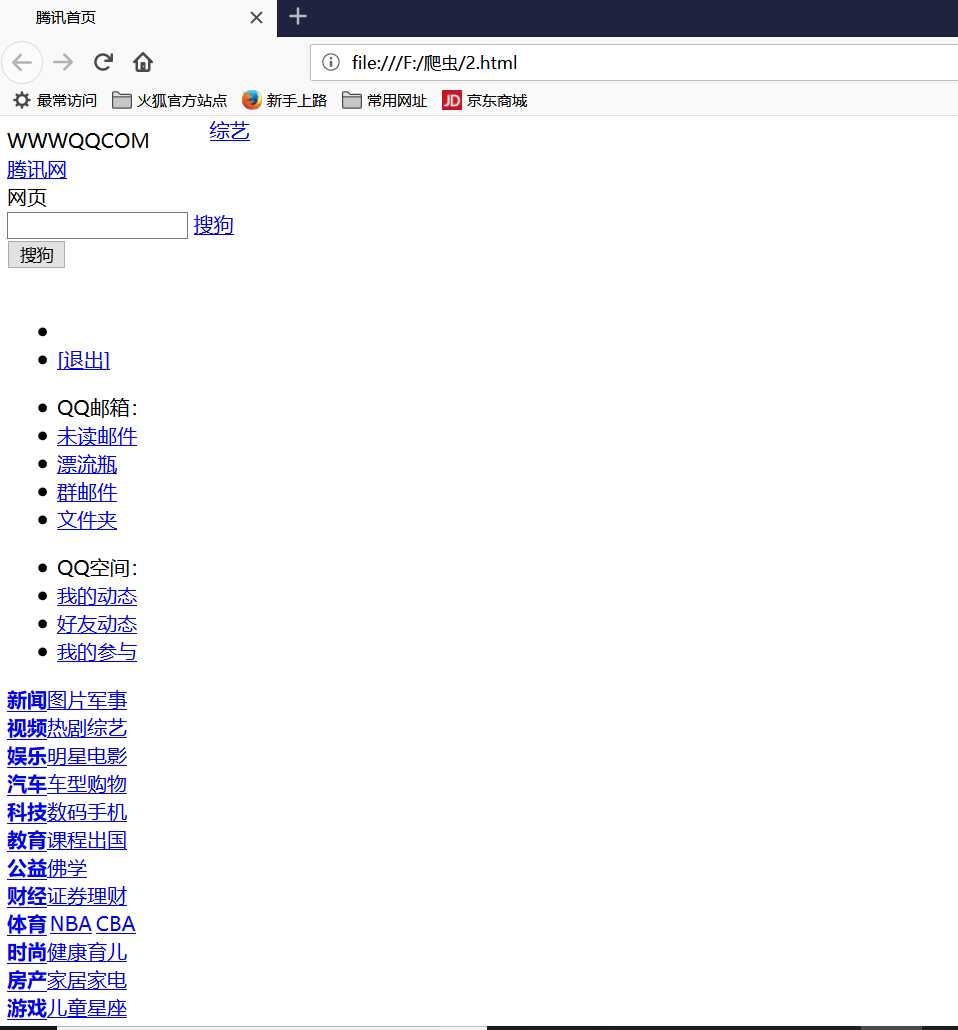
使用urlretrieve执行的过程中会产生一些缓存,可以使用函数urlcleanup()进行清除
还有写其他的常用的方法如下:
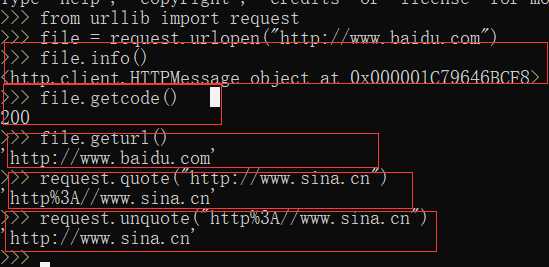
返回与当前环境有关的信息 info()
获取当前爬取网页的状态码 getcode()
获取当前爬取网页的URL地址 geturl()
由于URL标准中之允许一部分的ASCII字符,比如数字,字母,部分表单符号等,其他不符合标准的要进行编码,使用quote()
编码之后进行解码 unquote()
当然不是所有的网站都可以这么轻松的获取到,很多网站都进行了反爬虫设置,用浏览器可以打开但用爬虫爬不到,此时我们就需要设置一些headers信息,模拟成浏览器去访问这些网站。
首先打开浏览器,输入www.baidu.com 然后按F12 在刷新一下网页
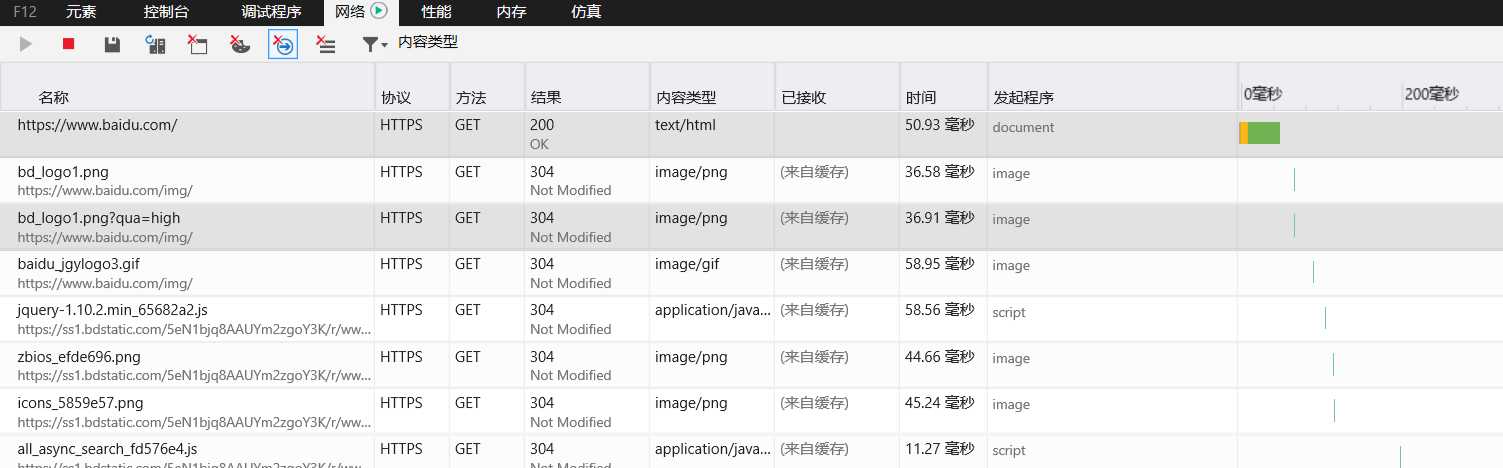
点击网络就可以看到上面的图了,然后点击第一个和右边的按钮

你就可以看到这样的
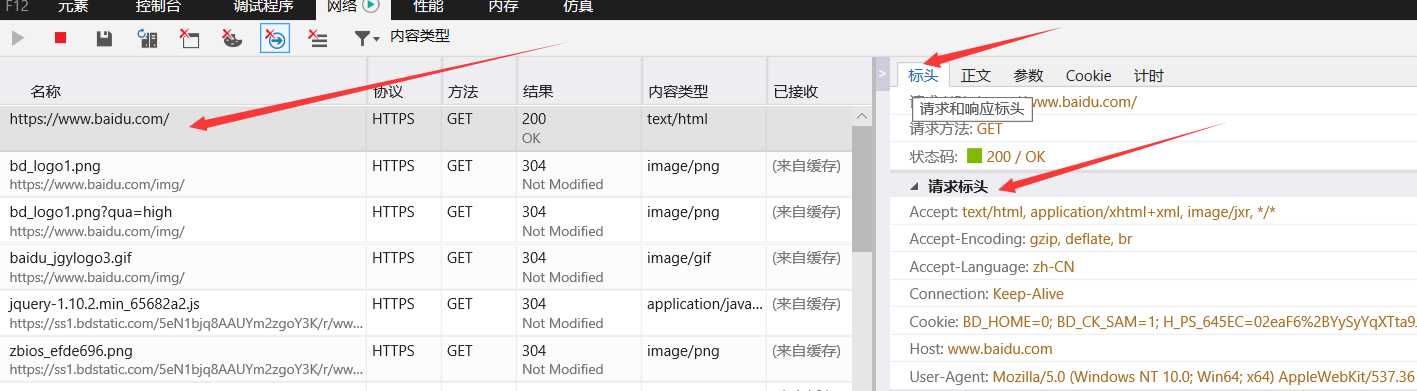
右边的标头就是headers,然后找到User-Agent,这个就是我们要用到的模拟浏览器的信息,将其复制下来
我们可以得到该信息 “User-Agent:Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36”
这样我们就可以修改报头,其中request()下的build_opener()和request.Request()下的add_header()都可以进行操作,如下:
from urllib import request url = "www.baidu.com" #仅仅是个例子 headers = ("User-Agent","User-Agent:Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36") opener = request.build_opener() opener.addheaders=[headers] data = opener.open(url).read() print(data)
还有一种方法是通过request.Request(url)方式进行操作如下:
from urllib import request urll = "http://www.baidu.com" req = request.Request(urll) req.add_header("User-Agent","User-Agent:Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36") #这里的键值对不止这一个,你也可以把所有的都写上,比如Cookie、host都可以 data = request.urlopen(req).read() fhandle = open("F:/爬虫/1.html","wb") fhandle.write(data) fhandle.close()
HTTP请求之GET请求
当我们用百度进行搜索时会看到网络请求用的时get请求
![]()
可以看出搜索词的关键字时wd,这样我们可以通过构造类似的网址进行网络请求,然后再将请求的网址保存
from urllib import request keywd = "中国是一个伟大的国家" key_code = request.quote(keywd) #汉字要编码, urll = "http://www.baidu.com/s?wd="+key_code #拼接字符串 req = request.Request(urll) data = request.urlopen(req).read() fhandle = open("F:/爬虫/3.html","wb") fhandle.write(data) fhandle.close()
然后打开本地保存的文件
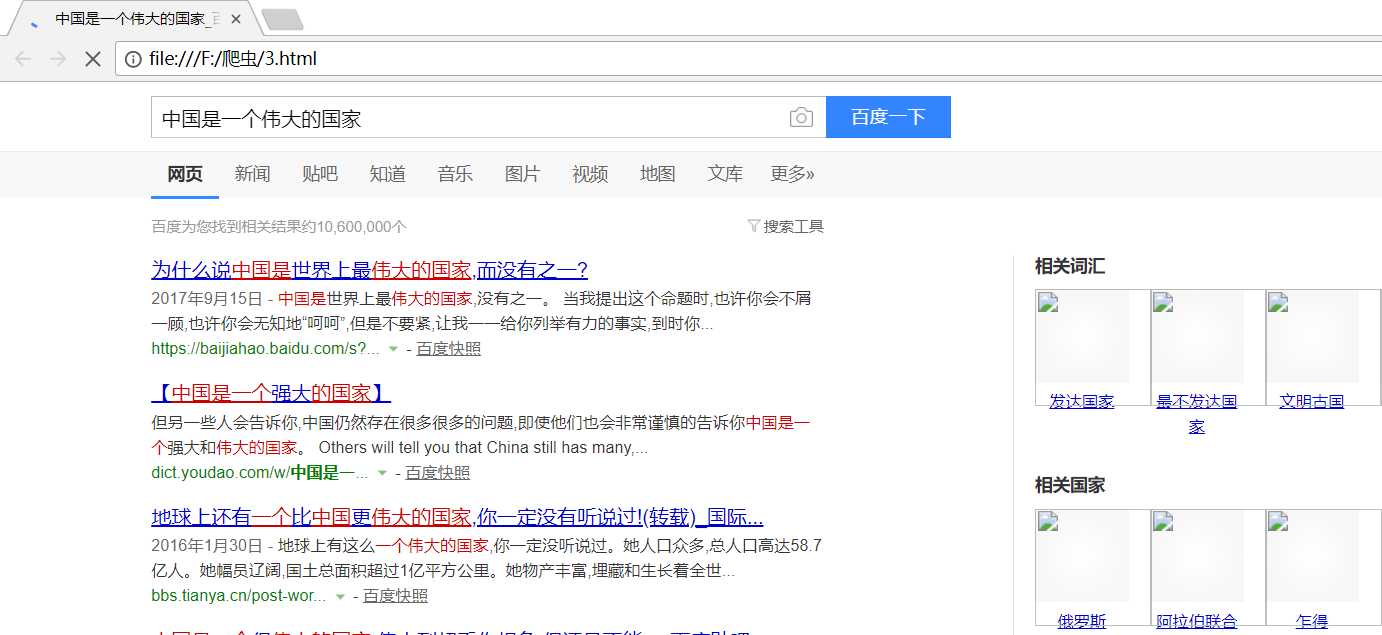
从上面的示例中可以总结出,使用GET请求的思路如下:
1.构造对应的URL地址,该URL地址包含GET请求的字段名和字段内容的信息,并且URL满足GET请求的格式,即 “http://网址?字段1=字段内容1&字段2=字段内容2”。
2.以顶印度额URL为参数,构建Request对象。
3.通过urlopen()打开构建的Request对象。
4.按需求进行后续处理的操作,比如读取网页的内容、将内容写入文件等。
HTTP请求之POST请求
在注册和登陆网站是我们基本上都会遇到post请求,下面举个例子,这个是自己搭建的post请求网页,很粗糙的一个,只是将post请求的用户名个密码提交之后打印在了页面上。源码如下:
<form action="<?=$_SERVER[‘PHP_SELF‘] ?>" method="POST"> 用户名<input type="text" name="username"><br> 密码<input type="password" name="passwd"><br> <input type="submit" name="submit" value="提交"> </form> <?php if (isset($_POST[‘submit‘])) { echo "<br>"; echo ‘用户名:‘.$_POST[‘username‘]."<br>"; echo "密码:".$_POST[‘passwd‘].‘<br>‘; } ?>
原始的页面是
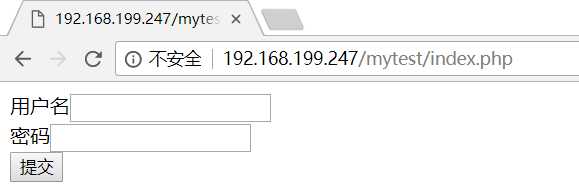
填写用户名和密码之后的页面
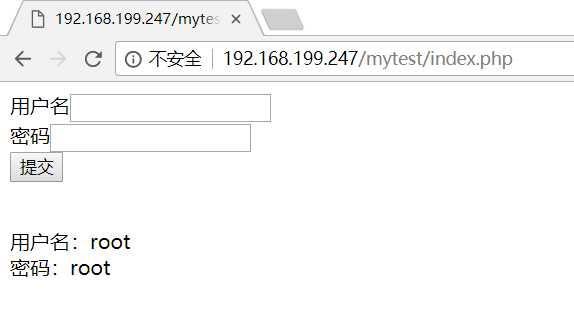
怎么构建post请求,一般的思路如下:
1.设置好URL网址
2.构建表单数据,并使用urllib.parse.urlencode对数据进行编码处理
3.创建Request对象,参数包括URL地址和要传递的编码处理
4.使用add_header()添加头部信息,模拟浏览器进行爬取
5.使用urllib.request.urlopen()打开对应的Request对象,完成信息的传递
6.读取或者写入等操作
现在我们去爬一下上面的网站:http://192.168.199.247/mytest/index.php
至于构建表单数据,我们需要看一下源码,打开网页,按F12,找到from表单的部分。
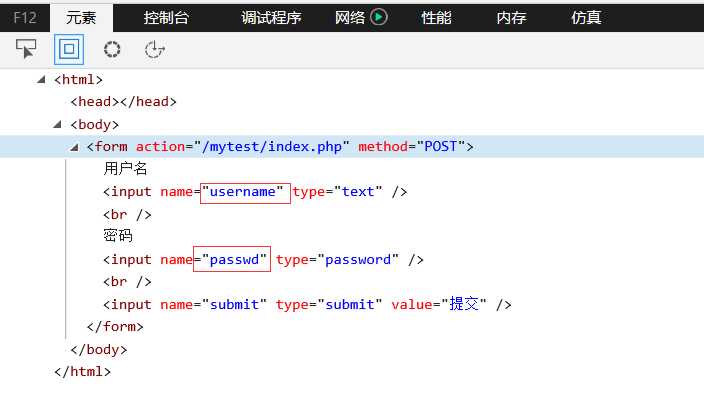
从上面我们可以看出需要提交表单的两个字段分别是:username、passwd。这样我们就可以构造数据,POST请求时的数据构造都要是以字典的形式进行所以我们构造的函数为:
{"username":"root","passwd":"root"},我们将用户名和密码都设置为root,这只完之后我们进行编码。然后创建Request对象之后就按着思路往下走就可以了
代码:
from urllib import request from urllib import parse #编码时需要用到的库 url = "http://192.168.199.247/mytest/index.php" postdata = parse.urlencode({ "username":"root", "passwd":"root" }).encode("utf-8") #设置编码格式为utf-8 req = request.Request(url,postdata) #在Request之后可以直接设置传递的数据 Request(url地址,传递的数据) req.add_header("User-Agent","User-Agent:Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36") data = request.urlopen(req).read() fhandle = open("F:/爬虫/1.html","wb") fhandle.write(data) fhandle.close()