标签:记录 查看 读写分离 方案 数据 逻辑 数据同步 相对 部分
起源
现在基本所有的程序中都会用到数据库,而数据库其实就是对所有业务逻辑处理结果的保存,所以不论在什么情况下数据的丢失都不被允许的,最坏的情况也要最小化数据的丢失程度,所以一般情况下,数据源都会至少配有两个节点,一个业务处理使用的节点,一个甚至多个从节点,这些从节点就是我们常说的冷备,业务处理节点(主节点)和备份节点一定的时间间隔内进行数据同步,从而来保证当一个数据源坏掉之后,数据也不会丢失,或着丢失很少(主要看同步的时间间隔)。但是为了提高资源的使用效率,所以有人就提出了,可不可以让冷备也被利用起来,替主节点分担部分压力,所以就提出了读写分离的方案。
读写分离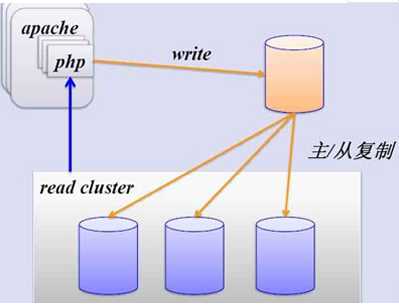
读写分离提高了资源的利用效率的同时也引出了一个问题,就是由于延时(网络传输,操作)而引起的数据库主从不一致的问题,对于这个问题,给一下集中解决方案。
1-半同步复制
主从不一致的原因是延时引起的,所以要消除这个延时的影响,可以从主库进行CUD操作时进行规避,办法就是等主从同步完成之后,主库上的写请求再返回,就是大家常说的“半同步复制”semi-sync。
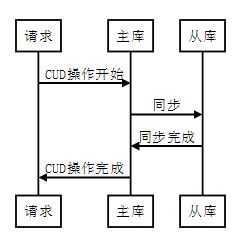
请求请求主库主库从库从库CUD操作开始同步同步完成CUD操作完成
方案优点:利用数据库原生功能,比较简单
方案缺点:主库的写请求时延会增长,吞吐量会降低
2-缓存记录写key法
CUD操作
(1)将某个库上的某个key要发生写操作,记录在cache里,并设置“经验主从同步时间”的cache超时时间,例如500ms
(2)修改数据库
R操作
(1)先到cache里查看,对应库的对应key有没有相关数据
(2)如果cache hit,有相关数据,说明这个key上刚发生过写操作,此时需要将请求路由到主库读最新的数据
(3)如果cache miss,说明这个key上近期没有发生过写操作,此时将请求路由到从库,继续读写分离
方案优点:相对数据库中间件,成本较低
方案缺点:方案缺点:为了保证“一致性”,引入了一个cache组件,并且读写数据库时都多了一步cache操作
标签:记录 查看 读写分离 方案 数据 逻辑 数据同步 相对 部分
原文地址:https://www.cnblogs.com/zhanggaofeng/p/12129197.html